- The paper presents a new CLERC dataset built from 1.84M federal cases to advance legal case retrieval and retrieval-augmented analysis generation.
- The authors developed tailored tasks and open-source pipelines for document-level retrieval and passage-level analysis, emphasizing citation precision.
- Empirical evaluations show that existing models struggle with long-context legal cases and hallucinated outputs, signaling a need for domain-specific fine-tuning.
An In-depth Analysis of "CLERC: A Dataset for Legal Case Retrieval and Retrieval-Augmented Analysis Generation"
The paper "CLERC: A Dataset for Legal Case Retrieval and Retrieval-Augmented Analysis Generation" (2406.17186) presents the development of a new dataset aimed at enhancing both retrieval and generative tasks in legal document composition. This dataset, CLERC, comprises digitized case law and aids in training and evaluating models in the field of legal information retrieval (IR) and retrieval-augmented generation (RAG).
Dataset Construction and Design
Compilation of the CLERC Dataset
The CLERC dataset is built on legal sources from the Caselaw Access Project (CAP), consisting of over 1.84 million federal case documents. Each document contains an average of 11.54 citations. The dataset transforms these historical legal cases into tasks conducive to current NLP methodologies, specifically focusing on IR and RAG tasks.
Key Contributions:
- Task Formulation: Developed legal case retrieval and generation tasks informed by both legal professionals and computational constraints.
- Pipeline Development: Created an open-source infrastructure for converting CAP data into a high-caliber dataset suitable for training models on legal retrieval and generation tasks.
- Empirical Evaluation: Demonstrated that existing models struggle significantly on long-context case retrieval and generation, with prevalent hallucinations by LLMs.
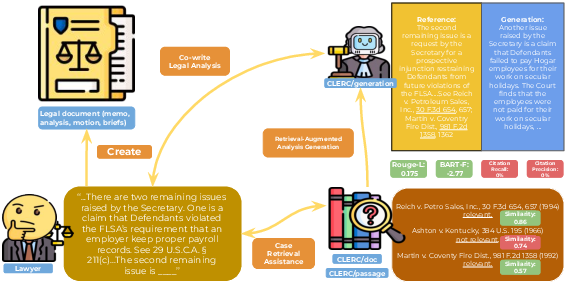
Figure 1: An overview of how CLERC enables systems that empower legal professionals: retrieval models for CLERC/doc and CLERC/passage that assist with finding relevant cases to support the analysis, and retrieval-augmented generation systems with CLERC/generation that aid in legal analysis generation.
Dataset Processing and Task Setup
The dataset includes a comprehensive taxonomy of U.S. legal data, with CLERC focusing specifically on a subset of federal cases, highlighting a robust area for potential enhancement. Documents in CLERC are prepared for IR by dividing into chunks (CLERC/passage) and remain whole for retrieval tasks (CLERC/doc). Generation tasks are constructed to evaluate the ability of LLMs to craft legally coherent analyses from preceding legal contexts.
Evaluation of Retrieval and Generation Models
Legal Case Retrieval
Benchmarking using state-of-the-art retrieval methods reveals prevailing challenges. The best-performing models achieve a Recall@1K of only 48.3% in zero-shot conditions, with fine-tuned versions showing significant improvement. Notably, GPT-based retrieval demonstrates a proclivity toward hallucinated outputs, underscoring the need for optimized legal training datasets.
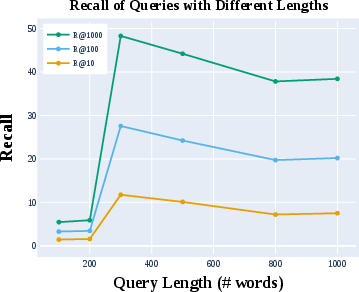
Figure 2: Retrieval results of BM25 with CLERC queries of length 100 to 1000 words. R@X represents Recall@X. Queries with 300 words maximize recall and are used for our main experiments.
Legal Analysis Generation
For retrieval-augmented legal analysis generation tasks, GPT-4o emerges with the highest ROUGE F-scores but also exhibits the most frequent hallucinations. Interestingly, prompting models with precise case texts considerably boosts citation precision and recall while diminishing false positives, a critical adaptation for legal text generation.
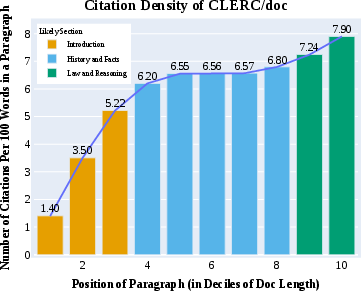
Figure 3: Number of citations per 100 words in a paragraph, arranged by the positions (in deciles) of paragraphs in the document. Documents tend to cite more often in later paragraphs.
Limitations and Future Directions
The dataset provides a foundational resource for legal AI but illustrates significant model limitations in both retrieval and generation domains due to inherent constraints in handling complex legal jargon and elongated contexts. An identified domain shift suggests a necessity for domain-specific model tuning for effective retrieval. Additionally, current models require robust citation management capabilities to be fully applicable in legal environments.
Conclusion
The introduction of CLERC represents an essential step forward in the development of NLP systems tailored to legal professionals. While current models benefit from this dataset, the research highlights considerable room for improvement in both retrieval precision and generation faithfulness. Future research could explore legal-specific model fine-tuning and enhanced methodologies for mitigating hallucinations in text generation.