- The paper introduces a probabilistic reward redistribution framework that models per-step rewards as Gaussian random variables using a leave-one-out strategy.
- It leverages maximum likelihood estimation to capture temporal dependencies and uncertainty in sparse, non-Markovian reward settings.
- Experimental results on Box-2d and MuJoCo tasks show improved sample efficiency and policy performance compared to baseline methods.
Likelihood Reward Redistribution
The paper "Likelihood Reward Redistribution" introduces a probabilistic framework to address sparse and delayed rewards in reinforcement learning (RL), which is a common challenge across various applications. Unlike traditional methods that treat per-step rewards as isolated, the proposed approach models these rewards using parametric probability distributions whose parameters depend on the state-action pair. This method is aimed at improving the learning efficiency and policy performance by introducing uncertainty regularization and considering the interdependencies among state-action pairs.
Reward Redistribution
Reinforcement Learning often deals with environments where rewards are sparse, leading to inefficient learning processes. Typically, RL frameworks model environments using a Markov decision process (MDP) to learn optimal policies. However, when rewards are only provided at the end of an episode, this episodic setting complicates the learning due to the non-Markovian attributes of decision processes. The goal is then to transform episodic feedback into a dense reward signal through reward redistribution.
Previous methods aim to decompose episodic returns into per-step contributions, often ignoring temporal dependencies between state-action pairs. This paper proposes a new reward redistribution framework leveraging maximum likelihood estimations and modeling rewards as random variables to capture these dependencies. By adopting a leave-one-out (LOO) strategy, the framework accounts for the likelihood of observed returns while integrating an uncertainty regularization.
Likelihood-based Approach
The proposed Likelihood Reward Redistribution (LRR) employs a Gaussian model where each proxy reward is treated as a Gaussian random variable. In this framework, the per-step reward is associated with both a mean and a standard deviation, parameterized by a neural network. The negative log-likelihood of rewards, calculated via the LOO strategy across full trajectories, serves as the optimization objective. This LRR framework extends to non-Gaussian distributions, allowing for flexibility in handling real-world asymmetric reward distributions such as those observed in finance.
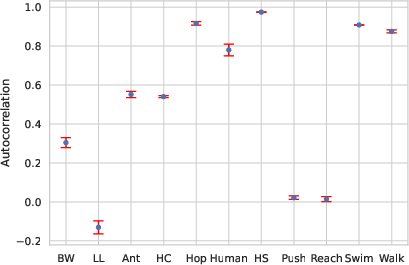
Figure 1: A summary of Lag-1 Autocorrelation (ρ1)
Implementation and Algorithm
The practical algorithm for implementing the Gaussian Reward Redistribution involves:
- Initializing model parameters and a replay buffer.
- Collecting trajectories and computing episodic rewards.
- In each update iteration, sampling a mini-batch from the replay buffer.
- Computing LOO rewards for each trajectory to capture interdependencies.
- Calculating the negative log-likelihood loss for Gaussian-distributed rewards and updating parameters via gradient descent.
This probabilistic reward model is seamlessly integrated with off-policy algorithms like Soft Actor-Critic (SAC), significantly enhancing sample efficiency and policy performance.
Experimental Evaluation
The LRR framework was evaluated on Box-2d and MuJoCo environments:
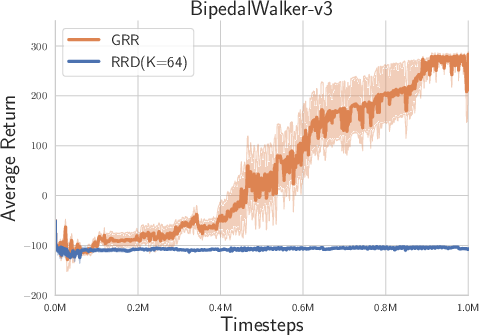
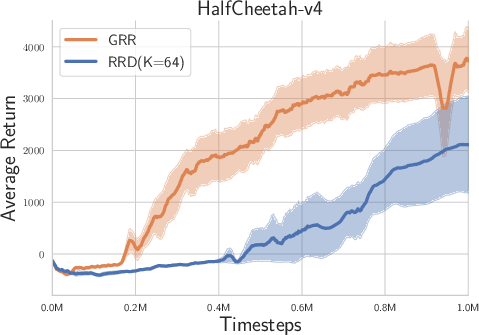
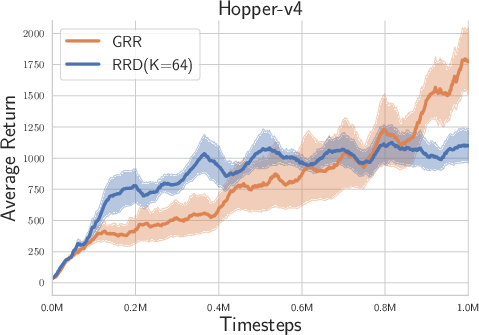
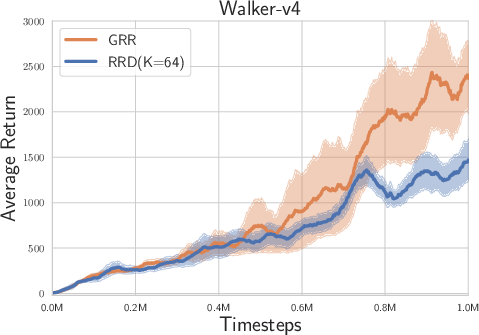
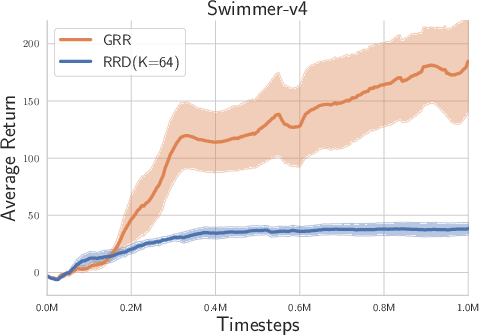
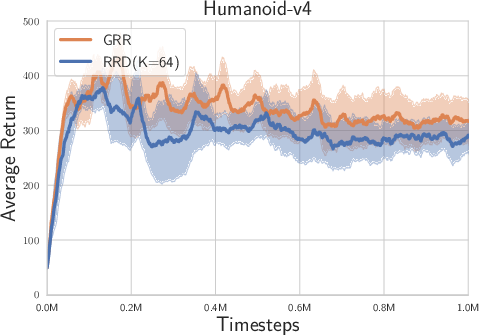
Figure 2: Experimental results on Box-2d and MuJoCo tasks with high reward autocorrelation.
- Overall Performance: The LRR consistently demonstrated superior performance compared to the randomized return decomposition (RRD) benchmark across tasks such as Hopper-v4, Humanoid-v4, and Walker-v4, which exhibit high lag-1 autocorrelation.
- Temporal Correlations: The likelihood-based approach was shown to be particularly beneficial in environments with moderate to high temporal correlations, enhancing the ability of the model to capture complex interdependencies between actions and states over time.
Conclusion
This paper proposes a robust probabilistic framework for reward redistribution that addresses challenges in environments with sparse, non-Markovian rewards. By modeling per-step rewards as stochastic variables and leveraging a LOO strategy, the approach captures temporal dependencies, leading to improved learning efficiency and policy effectiveness. Future work could explore extensions to multi-agent scenarios and different noise distributions, enhancing the framework's adaptability across diverse RL environments.