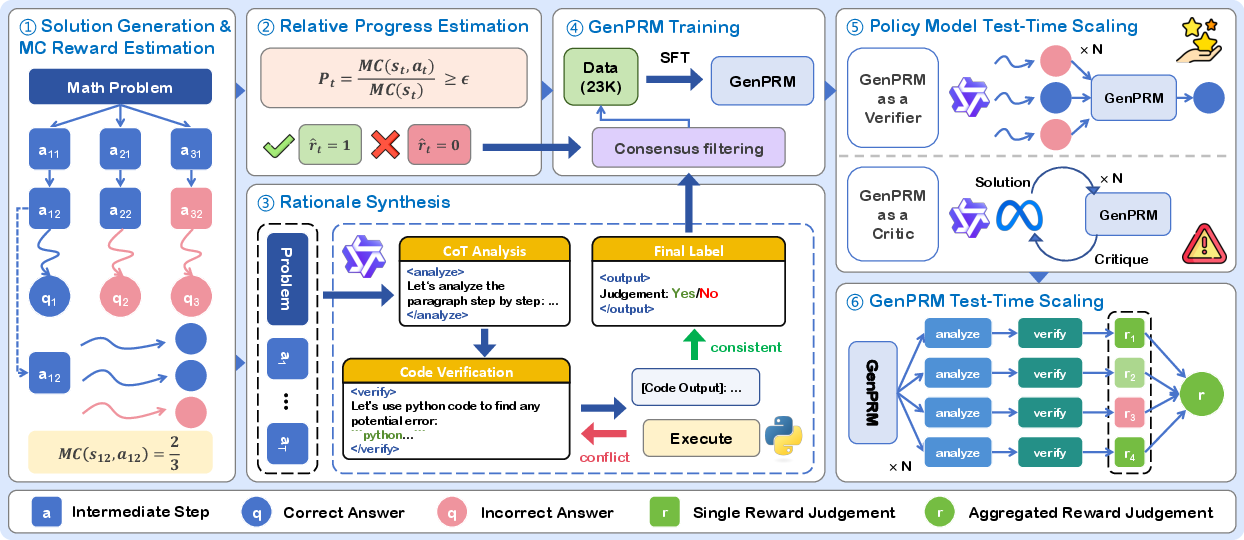
- The paper introduces a generative approach that reframes process reward models as verifiers using explicit chain-of-thought reasoning.
- It integrates code-based verification for step-level evaluation, reducing dependency on extensive training data while improving output accuracy.
- The model scales test-time compute effectively, enabling smaller LLMs to outperform larger models on challenging reasoning benchmarks.
GenPRM: Scaling Test-Time Compute of Process Reward Models via Generative Reasoning
Introduction
"GenPRM: Scaling Test-Time Compute of Process Reward Models via Generative Reasoning" proposes a novel generative approach to enhancing Process Reward Models (PRMs) for LLMs. Traditional PRMs face constraints on process supervision and generalization, stemming partially from reliance on scalar value predictions. GenPRM reimagines PRMs as verifiers that leverage explicit Chain-of-Thought (CoT) reasoning, integrating code verification to bolster step-level evaluation in reasoning tasks. This transforms the task of process supervision into a generative modeling problem, providing productive avenues for scaling test-time compute to improve LLM performance in complex scenarios.
GenPRM Framework
GenPRM introduces a generative process verification architecture, which incorporates CoT reasoning and code-based verification:
Experimentation and Results
GenPRM demonstrates substantial improvements over prior classification-focused PRMs in various mathematical reasoning benchmarks, including ProcessBench and MATH. The model achieves these improvements using significantly less training data due to its generative nature.
- Performance Metrics: The results showcase that with a parameter count of 1.5B, GenPRM rivals or exceeds the capabilities of larger, more resource-intensive models such as GPT-4o and Qwen2.5-Math-PRM-72B through techniques like majority voting and Best-of-N sampling.

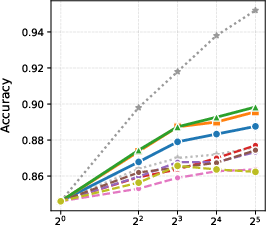
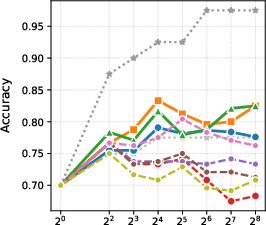
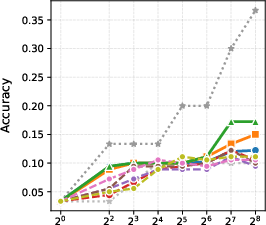
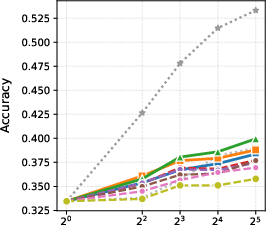
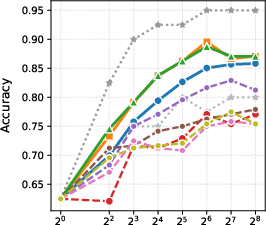
Figure 2: BoN results with different generation models.
- Test-Time Scaling: By exploiting the scalability of its generative process, the GenPRM framework enables smaller models to outperform what were previously best-in-class models by scaling compute efficiently.
Practical Implications and Future Directions
- Scalability: GenPRM establishes a paradigm where smaller models effectively compete or surpass larger counterparts by optimizing test-time compute operations. This scalability reduces dependency on excessively large models, creating potential cost efficiencies and resource savings.
- Critique Framework: The incorporation of code-based verification positions GenPRM as a potential critic model that can refine LLM outputs dynamically. This extends its utility beyond static verification into real-time, adaptive processing tasks.
- Broader Applicability: While this work emphasizes mathematical reasoning, the generative reasoning approach holds promise for other domains reliant on process-level supervision, such as coding or multimodal tasks.
Conclusion
GenPRM represents a shift towards generative reasoning mechanisms for validating and improving LLM performance. By leveraging the generative capacities of LLMs in conjunction with explicit reasoning techniques and code execution, GenPRM advances the scalability and usability of PRM frameworks. Future research can enhance this paradigm by exploring dynamic pruning methods and adaptations to other knowledge domains, thus further extending the impact of generative reasoning on LLM capabilities.