Enhancing Embedding Representation Stability in Recommendation Systems with Semantic ID
Abstract: The exponential growth of online content has posed significant challenges to ID-based models in industrial recommendation systems, ranging from extremely high cardinality and dynamically growing ID space, to highly skewed engagement distributions, to prediction instability as a result of natural id life cycles (e.g, the birth of new IDs and retirement of old IDs). To address these issues, many systems rely on random hashing to handle the id space and control the corresponding model parameters (i.e embedding table). However, this approach introduces data pollution from multiple ids sharing the same embedding, leading to degraded model performance and embedding representation instability. This paper examines these challenges and introduces Semantic ID prefix ngram, a novel token parameterization technique that significantly improves the performance of the original Semantic ID. Semantic ID prefix ngram creates semantically meaningful collisions by hierarchically clustering items based on their content embeddings, as opposed to random assignments. Through extensive experimentation, we demonstrate that Semantic ID prefix ngram not only addresses embedding instability but also significantly improves tail id modeling, reduces overfitting, and mitigates representation shifts. We further highlight the advantages of Semantic ID prefix ngram in attention-based models that contextualize user histories, showing substantial performance improvements. We also report our experience of integrating Semantic ID into Meta production Ads Ranking system, leading to notable performance gains and enhanced prediction stability in live deployments.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making recommendation systems (like those that choose which ads or videos to show you) more stable and smarter. It introduces a better way to give “IDs” to items (ads, products, videos) called Semantic ID. This method groups similar items together based on their meaning, not just random numbers. The authors also present a new trick, called “prefix n‑gram,” that uses the structure inside these IDs to boost accuracy and stability even more.
What questions did the researchers ask?
They focused on simple, practical questions:
- How can we stop item representations in recommendation models from changing unpredictably over time?
- Can we help “tail” items (the many items that get only a few views) learn from popular, similar items?
- Can we make predictions more stable when lots of new items appear and old items disappear?
- Will a meaning-based ID system improve real-world ad ranking performance at scale?
How did they study it? (Methods in everyday language)
First, here are the three big problems they face in real systems:
- Too many items: There are far more items than the model can store separately.
- Popularity imbalance: A tiny group of “head” items gets most views, while a huge number of “tail” items gets very few.
- Constant change: Items come and go quickly, so the model’s memory keeps shifting.
Most systems deal with “too many items” by using random hashing:
- Imagine a big shelf with limited slots. Random hashing tosses items into random shared slots. Different items end up sharing the same space (a “collision”).
- This can scramble learning: when different items share a slot, the model gets mixed signals and the meaning of that slot keeps changing.
The authors replace this with Semantic ID:
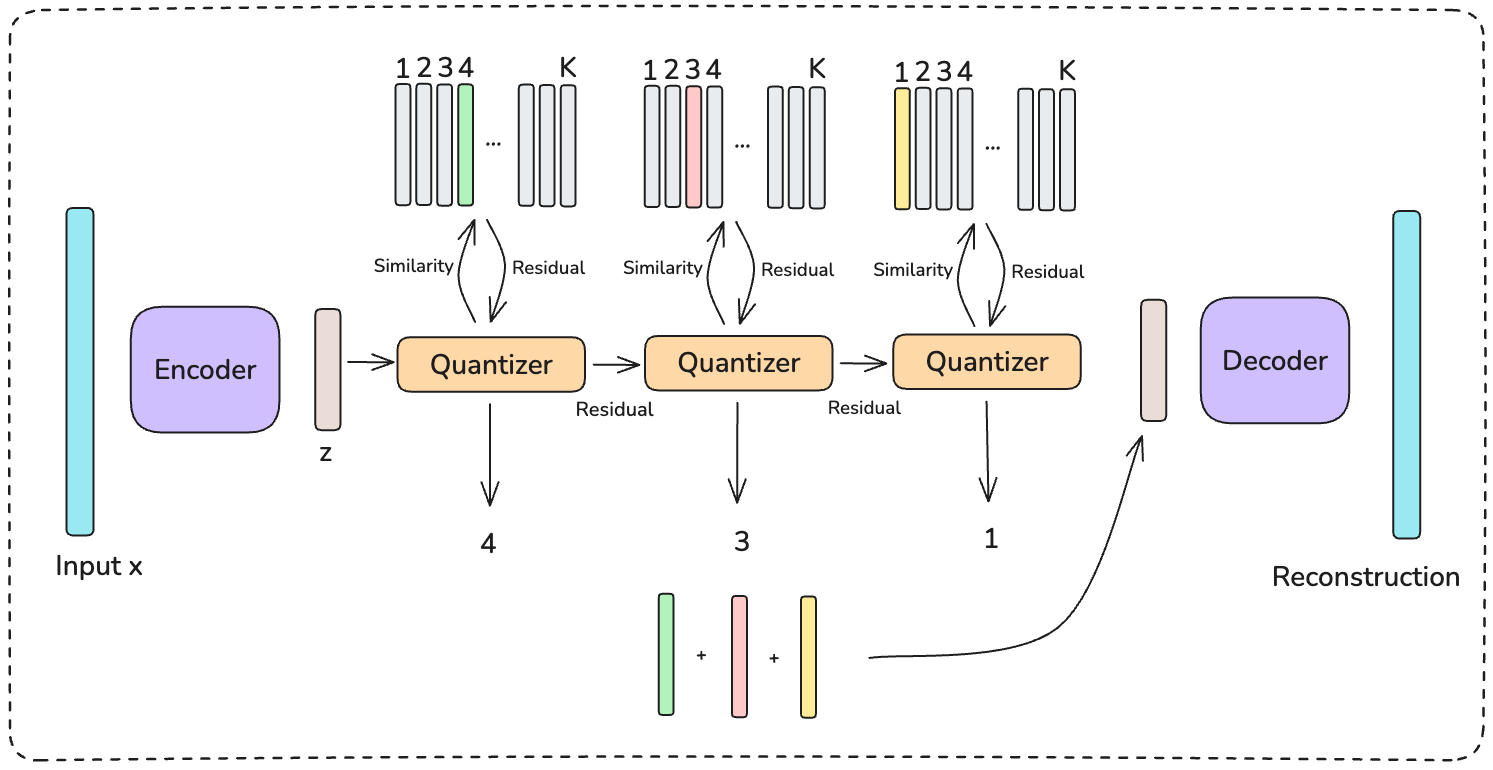
- Step 1: Understand content. They turn each item’s text, image, or video into a content embedding (a numeric summary of meaning).
- Step 2: Group by meaning using RQ‑VAE. Think of RQ‑VAE as a smart compressor that gives each item a code made of several parts, like an address:
- First part: broad group (e.g., “food”).
- Next part: more specific (e.g., “pizza”).
- Next part: even more specific (e.g., “pizza in English”).
- This creates a hierarchical code: c1, c2, c3, … where each deeper part gives finer detail. Items with similar content get similar codes (often sharing the first parts).
Making the codes useful with “prefix n‑grams”:
- The model can’t use every full code because there are too many combinations.
- Prefix n‑grams feed the model the first 1 part, then the first 2 parts, then the first 3 parts, etc. Example:
- c1
- (c1, c2)
- (c1, c2, c3)
- This lets the model learn from broad similarities (c1) and get more detail (c1,c2), (c1,c2,c3) when helpful. It’s like knowing “this is food,” “this is pizza,” and “this is English‑language pizza content,” all at once.
How they tested it:
- They compared three approaches on Meta’s ad ranking data: 1) Individual Embeddings (one ID per item, not realistic at huge scale). 2) Random Hashing (common in industry). 3) Semantic ID with prefix n‑grams (their method).
- They measured performance using “Normalized Entropy” (NE). Lower NE = better predictions.
- They looked at results for head, torso, and tail items; and for new items that never appeared during training.
- They also checked how well the method works with attention models (like Transformers) that read a user’s recent history and decide which past actions matter most.
What did they find?
Here are the key takeaways, with a short explanation of why each matters:
- Better for tail and new items:
- Semantic ID helped the long tail (the many items with few views) and “cold-start” new items the most.
- Why it matters: Tail and new items usually suffer because the model hasn’t seen them much. With Semantic ID, they can “borrow” knowledge from similar items.
- More stable over time:
- Semantic ID reduced the problem where meanings drift as items come and go.
- Why it matters: Stability builds trust. Advertisers and users get more consistent results.
- Prefix n‑grams beat other ways of using the codes:
- Using the hierarchical prefixes (c1; c1,c2; c1,c2,c3; …) clearly outperformed flat or partial mappings.
- Why it matters: It proves the hierarchy (coarse-to-fine meaning) helps the model learn and share knowledge effectively.
- Works especially well with attention models on user history:
- With Semantic ID, attention models focused more on the most relevant recent actions and less on noise or padding.
- Why it matters: Better “attention” leads to better recommendations.
- Real-world production gains at Meta:
- About 0.15% improvement in a top online metric for the ads ranking system—a big deal at Meta’s scale.
- 43% reduction in prediction differences for exact duplicate items (“A/A variance”), meaning the system behaves more consistently.
- Swapping items within the same Semantic ID prefix caused smaller drops in click rate, showing prediction similarity matches semantic similarity.
Why does this matter?
- Fairer and smarter recommendations: Tail and new items don’t get ignored—they can learn from semantically similar popular items.
- More consistent behavior: The model’s “memory” of what an ID means doesn’t get scrambled by random collisions or fast-changing item lists.
- Better use of user history: Attention models can focus on what truly matters in someone’s recent behavior.
- Real-world impact: Even small percentage gains mean better experiences for users and better results for advertisers when billions of recommendations are served.
What’s the potential impact?
- For platforms: More stable, scalable systems that handle huge catalogs with less randomness and fewer surprises.
- For creators and advertisers: More reliable delivery and better performance for niche or newly launched content.
- For users: Recommendations that feel more relevant and consistent over time.
- For research and engineering: A strong case for using meaning-based, hierarchical codes (like Semantic ID with prefix n‑grams) instead of random hashing in large recommendation systems.
Collections
Sign up for free to add this paper to one or more collections.