- The paper introduces a reward algorithm that uses pairwise comparisons to incentivize concise and correct responses.
- It leverages a dual approach for verifiable and fuzzy tasks by applying length penalties and quality-based rewards.
- Experimental results in DeepScaleR and DAPO settings show reduced response lengths while preserving model performance.
Self-Adaptive Chain-of-Thought Learning
Introduction
The evolution of reasoning models significantly intersects with the implementation of Chain of Thought (CoT) reasoning frameworks, guiding enhancements in both performance and adaptability. Despite substantial advancements, a prevalent challenge lies in the inefficiency of CoT mechanisms, particularly in situations where simple questions elicit unnecessarily elaborate responses, thereby undermining operational efficacy. Traditional approaches to length penalization, focused predominantly on applying penalties based on response length itself, fail to consider the intrinsic complexity variance of problems—a pivotal oversight that may lead to compromised performance on intricate problems. This paper proposes an innovative reward algorithm that addresses these limitations, constructing a reward system through strategic length and quality comparisons. Through theoretical foundations, the work demonstrates that models can achieve solution correctness while ensuring conciseness, effectively promoting a self-adaptive mechanism where models “think when needed.”
Methodology
Reward Construction
The proposed methodology pivots around pairwise comparisons within a reinforcement learning context, underpinned by theoretical assumptions. By utilizing pairwise reward structures, the technique evaluates all possible sample combinations, assigning rewards based on relative performance metrics between samples. Key assumptions include the superiority of correct responses over incorrect ones and the preferential reward for shorter correct responses within verifiable tasks. In this framework, incorrect responses uniformly receive lesser rewards compared to their correct counterparts, and shorter correct answers are awarded more than longer ones.
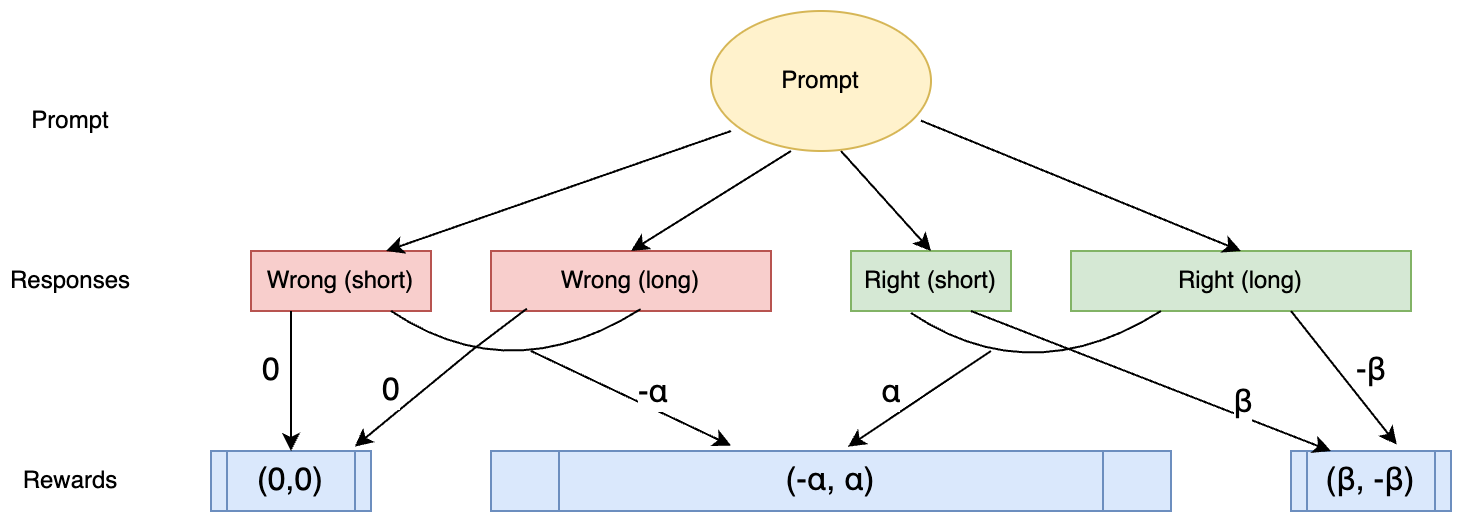
Figure 1: Verifiable task comparison scenarios.
Furthermore, in fuzzy task settings, where ground truth is unavailable, responses are evaluated comparatively. The assumptions extend to these scenarios with conditions dictating that superior answers must receive higher rewards, irrespective of their length, though length penalties remain impactful.
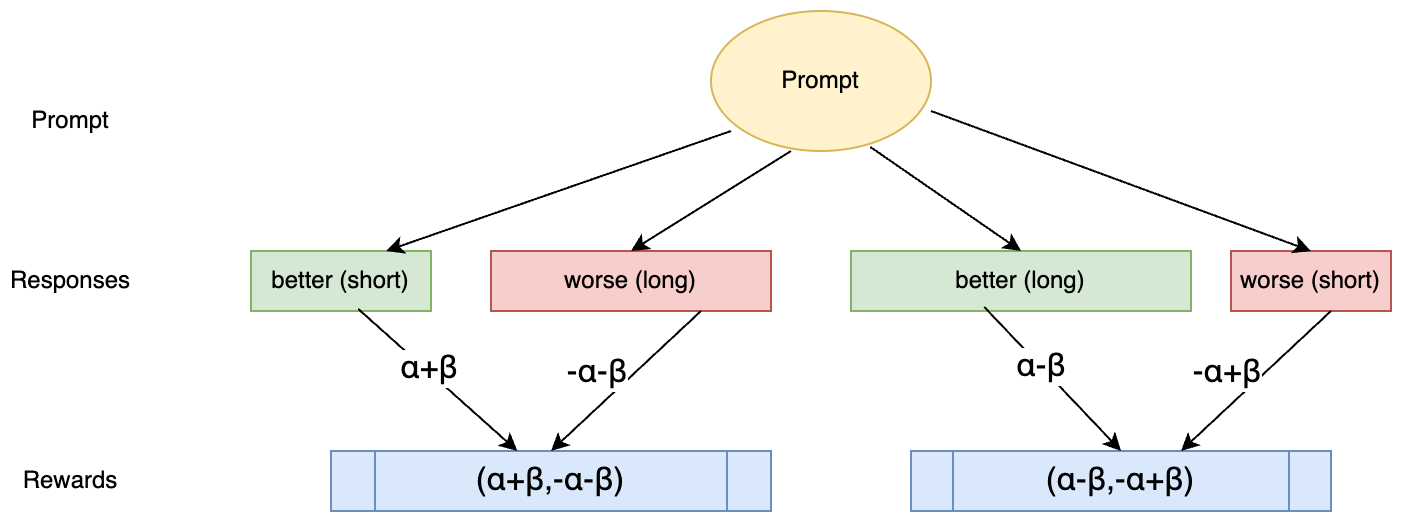
Figure 2: Fuzzy task comparison scenarios.
Implementation in Verifiable Tasks
For verifiable tasks where each response can be categorized as correct or incorrect, the method delineates several pairwise scenarios:
- Correct versus incorrect answers: Correct responses gain an α reward while incorrect responses suffer a penalty.
- Length-based comparison among correct answers: Shorter correct responses are rewarded with β, while the longer ones are penalized.
These scenario rules guide the cumulative reward calculation across all samples, promoting concise, accurate responses while maintaining a clear reward hierarchy that reflects both correctness and efficiency.
Implementation in Fuzzy Tasks
In fuzzy task environments, comparison is driven by qualitative assessment complemented by length-based penalties. Two comparative scenarios are defined:
- Short better response versus long worse response.
- Long better response versus short worse response.
Figure 2: Fuzzy task comparison scenarios.
The fuzzy task reward formulations ensure that better answers retain a reward advantage, even after length penalties are applied, thereby encouraging concise quality responses without overemphasizing verbosity.
Experimental Results
DeepScaleR Setting
Evaluation in the DeepScaleR setting demonstrates a marked reduction in response length while maintaining test accuracy levels comparable to conventional baselines. The 1.5B and 7B models exhibit consistent performance improvements in response efficiency.
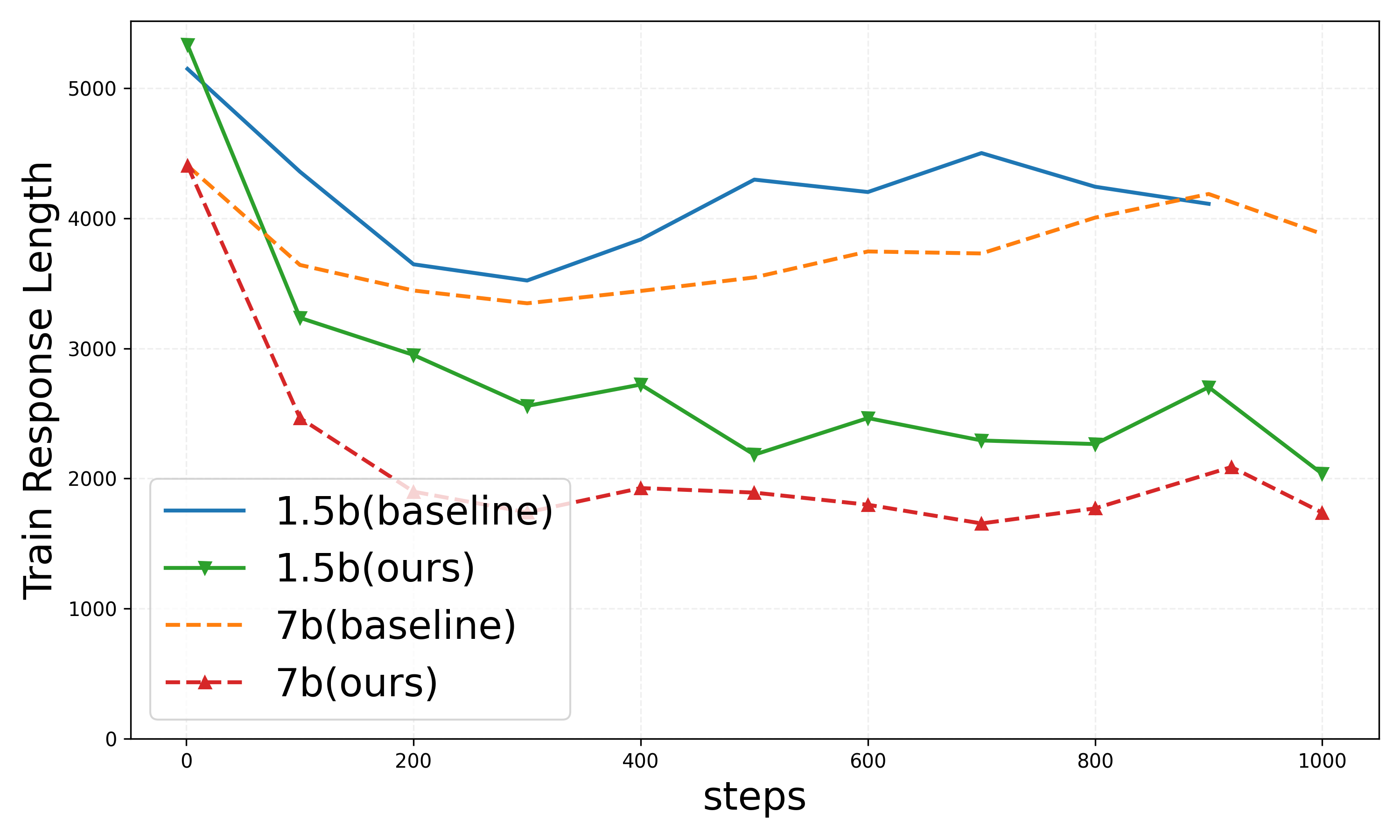
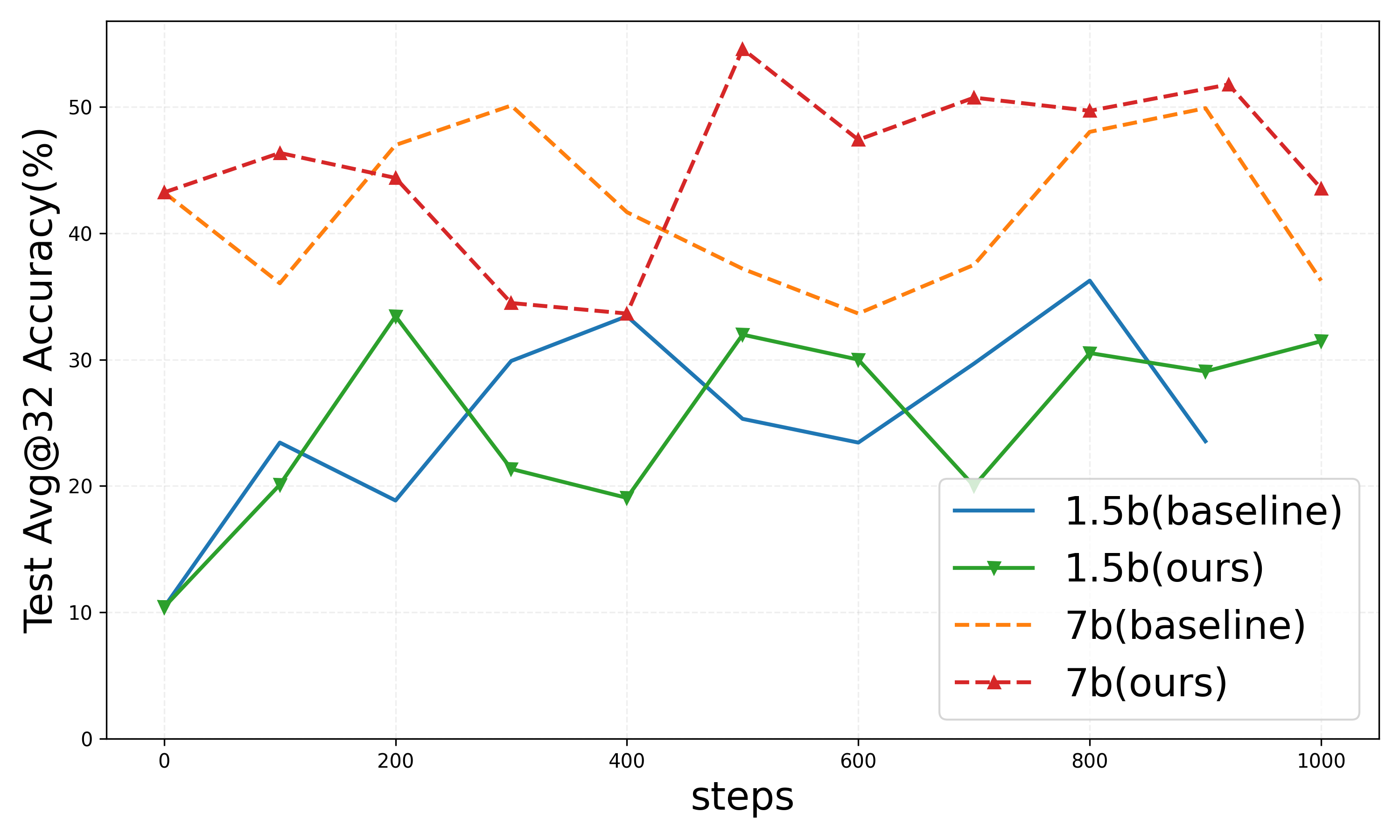
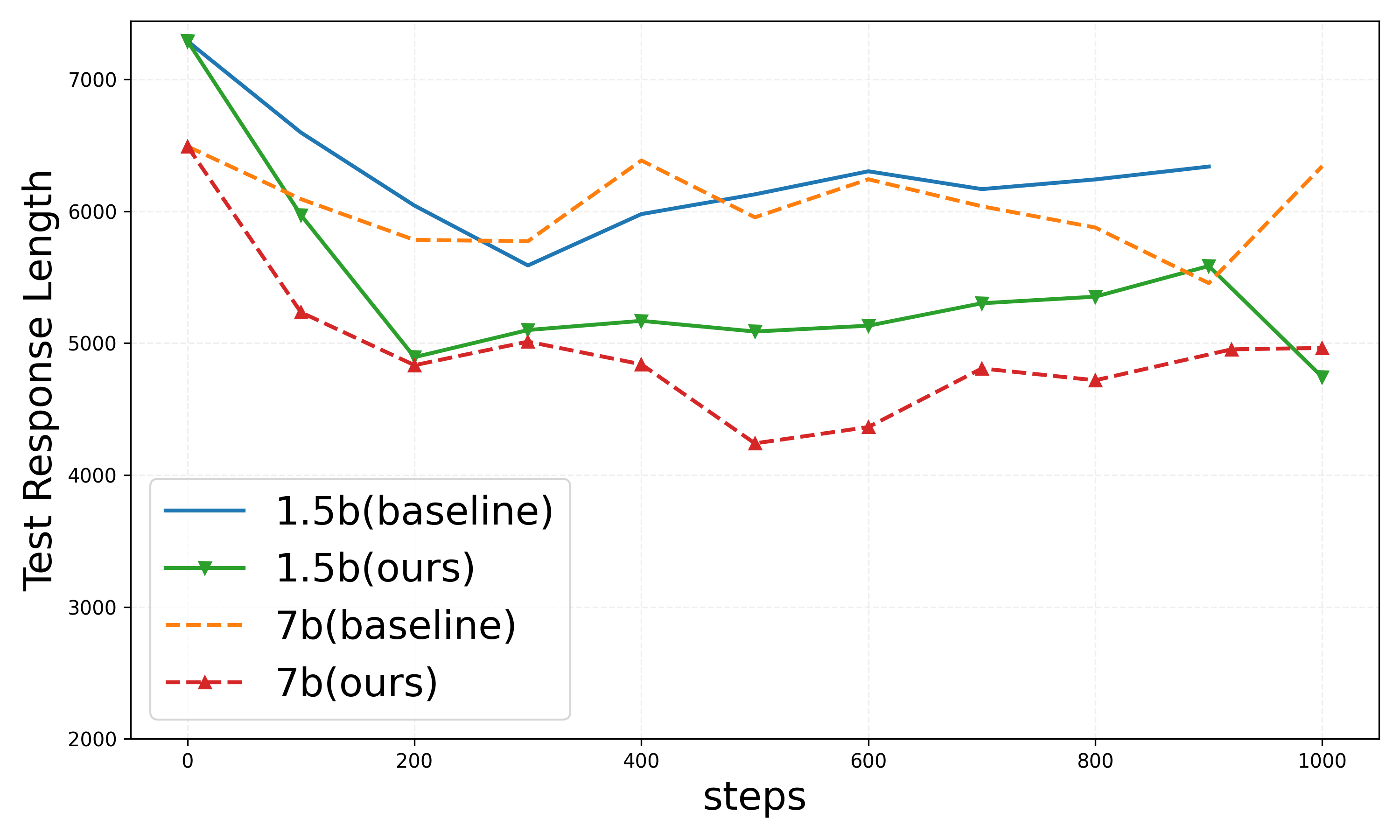
Figure 3: Results on DeepScaleR setting.
DAPO Setting
Within the DAPO configuration, similar trends are observed, with substantial reductions in both training and test response lengths, highlighting the method’s adaptability across diverse neural architectures and task environments.
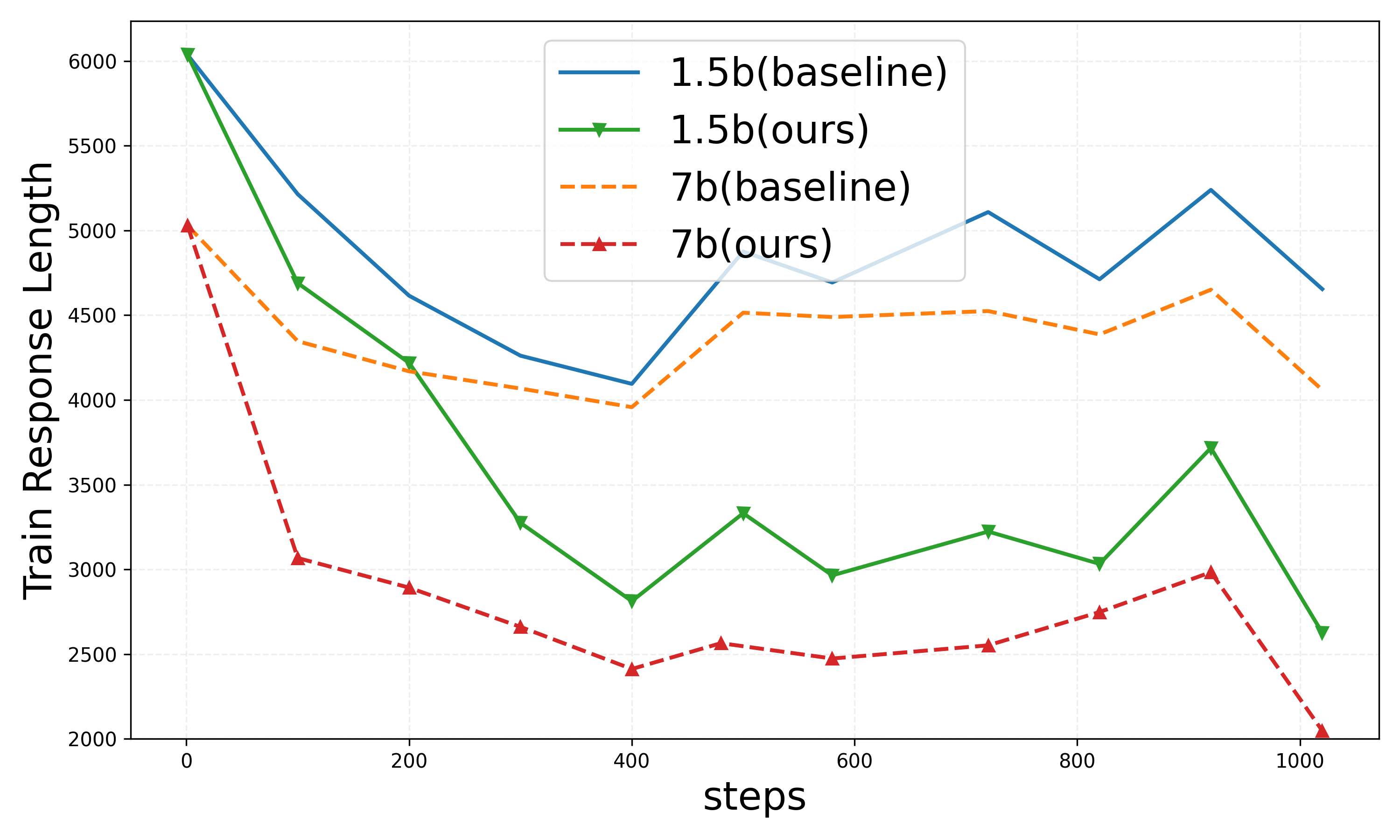
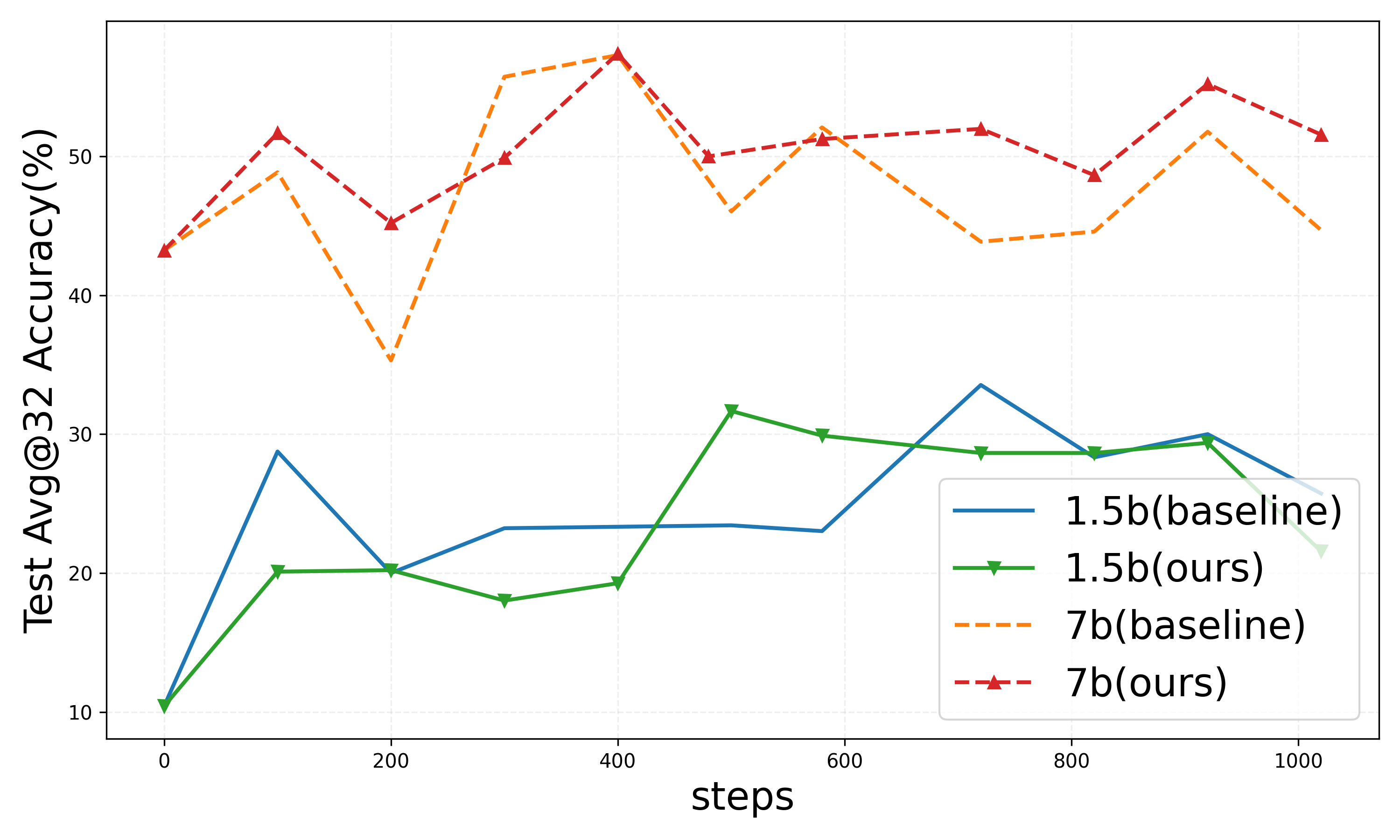
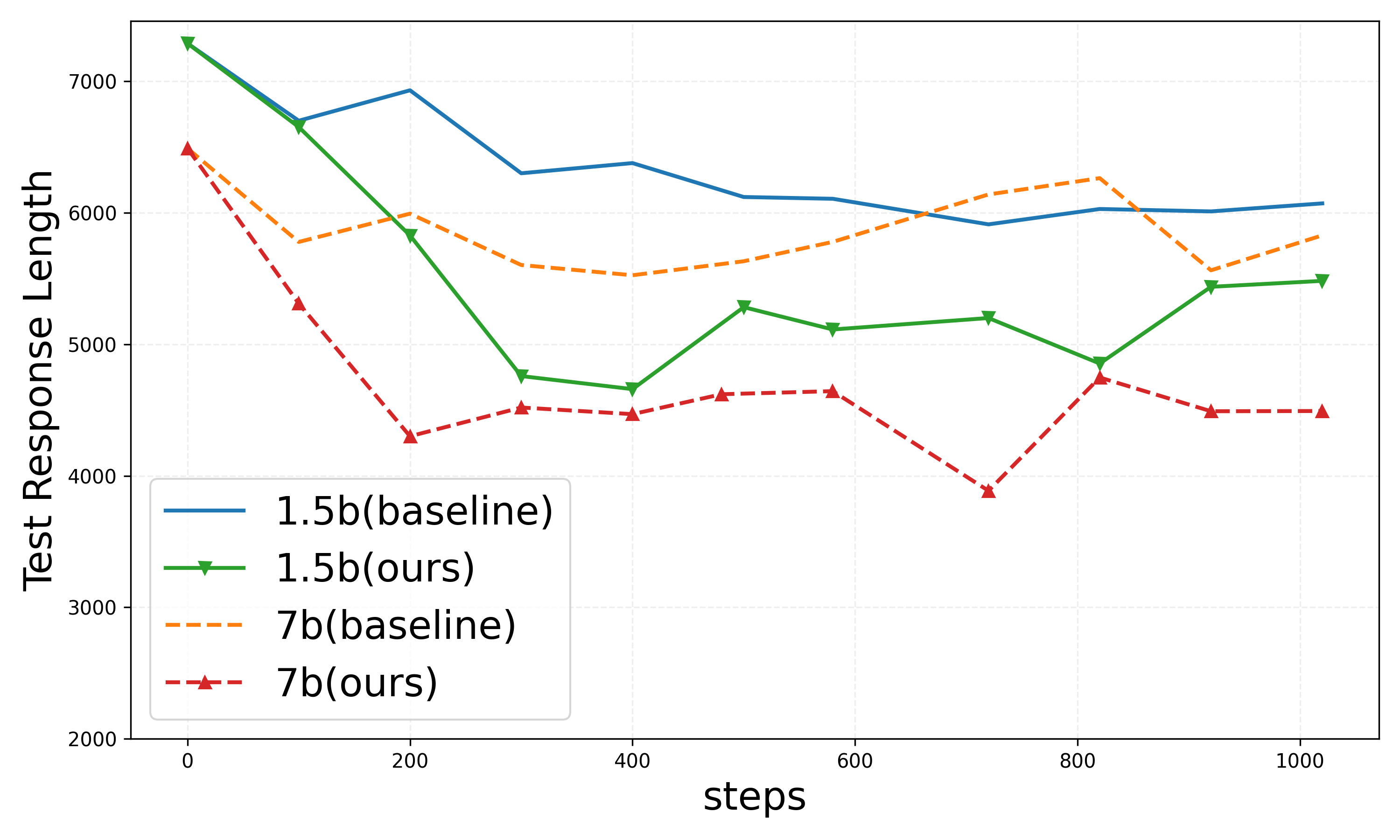
Figure 4: Results on DAPO setting.
Conclusion
The integration of self-adaptive CoT learning frameworks as proposed in this study facilitates a balanced approach to reasoning efficiency, leveraging pairwise rewards to maintain a high level of correctness alongside minimized response length. This methodology not only addresses inefficiency but proposes a comprehensive solution applicable across both verifiable and fuzzy task environments, offering a transformative perspective on reinforcement learning applications in reasoning models. The theoretical underpinnings ensure a robust adaptability and potency, paving the way for future explorations into efficient reasoning processes within LLMs.
In summary, the paper provides both a theoretical and practical framework for enhancing LLMs' reasoning efficacy, encouraging continued exploration and adaptation of these techniques to diverse reasoning domains.