- The paper presents an efficient multimodal VLM that excels in OCR, mathematical reasoning, and multi-image tasks using a compact 2.8B parameter MoE language decoder.
- The paper details a hybrid training paradigm combining standalone ViT pre-training and joint image-text training phases, processing up to 4.4 trillion tokens.
- The paper demonstrates practical improvements in handling extended context lengths with a 128K window and optimized parallel processing for enhanced multimodal reasoning.
Kimi-VL Technical Report
Abstract and Introduction
The Kimi-VL report introduces an efficient open-source Mixture-of-Experts (MoE) vision-LLM capable of advanced multimodal reasoning across diverse domains. The model leverages only 2.8 billion parameters in its language decoder while demonstrating proficiency in a variety of challenging multimodal tasks, including OCR, mathematical reasoning, and multi-image understanding. Alongside its general-purpose VLM capabilities, Kimi-VL surpasses some state-of-the-art models such as GPT-4o in several aspects, particularly in processing extensive contexts through its 128K extended context window. These advantages position Kimi-VL as a promising tool in efficient multimodal thinking and reasoning.
Model Architecture
The core architecture of Kimi-VL consists of three integral components: MoonViT, an MLP projector, and a MoE LLM. MoonViT acts as a native-resolution vision encoder, adapted to handle varying image resolutions effectively by employing patch packing mechanisms similar to NaViT. The MLP projector facilitates the bridging of vision and language modalities, maintaining compatibility across computational operators used in language modeling. The MoE language decoder activates a compact parameter set to deliver efficient reasoning capabilities, showing significant improvements over traditional dense architectures in multimodal tasks.
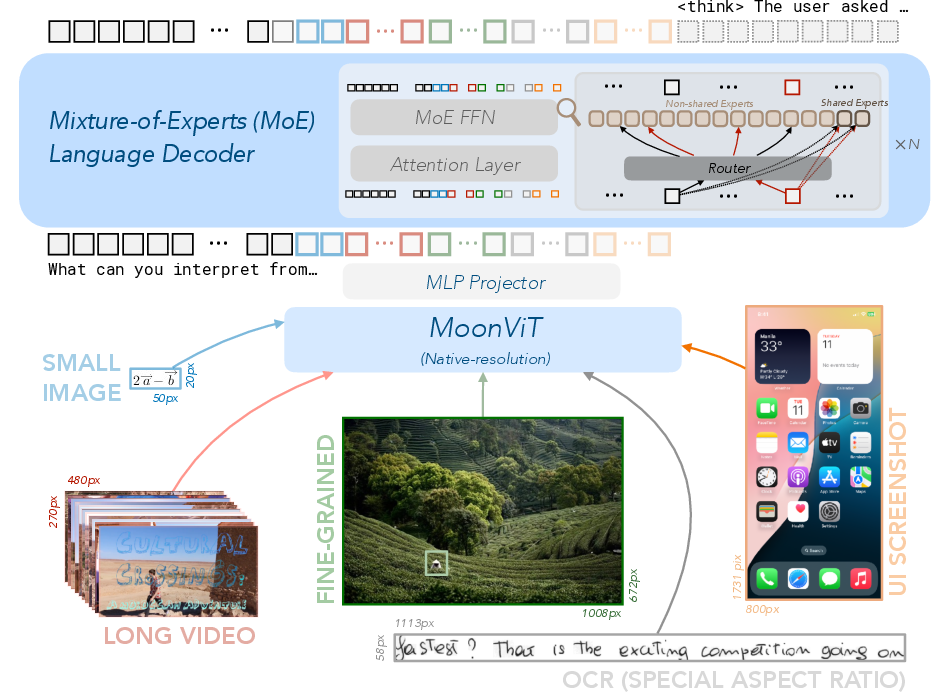
Figure 1: The model architecture of Kimi-VL, consisting of a MoonViT vision encoder, an MLP projector, and a Mixture-of-Experts language decoder.
Training Paradigms
Kimi-VL's training is divided into multiple stages, beginning with standalone ViT training and followed by joint pre-training to solidify language and multimodal understanding. Specifically, it integrates image-text pairs during ViT training using contrastive and cross-entropy losses, then proceeds with joint stages to fuse language comprehension with visual capabilities. The final training phases focus on long-context activation, optimizing for extended sequence processing by scaling the context length significantly.

Figure 2: The pre-training stages of Kimi-VL consuming a total of 4.4 trillion tokens, emphasizing joint training phases.
Kimi-VL demonstrates competitive performance across various benchmarks such as MMMU, MathVista, and InfoVQA, indicating its effectiveness in multimodal reasoning and understanding. The extended context window allows for nuanced comprehension of long-form inputs, contributing to substantial accuracy in document and video task evaluations. Moreover, Kimi-VL-Thinking, an advanced variant, further enhances reasoning through refined supervised fine-tuning and reinforcement learning techniques.
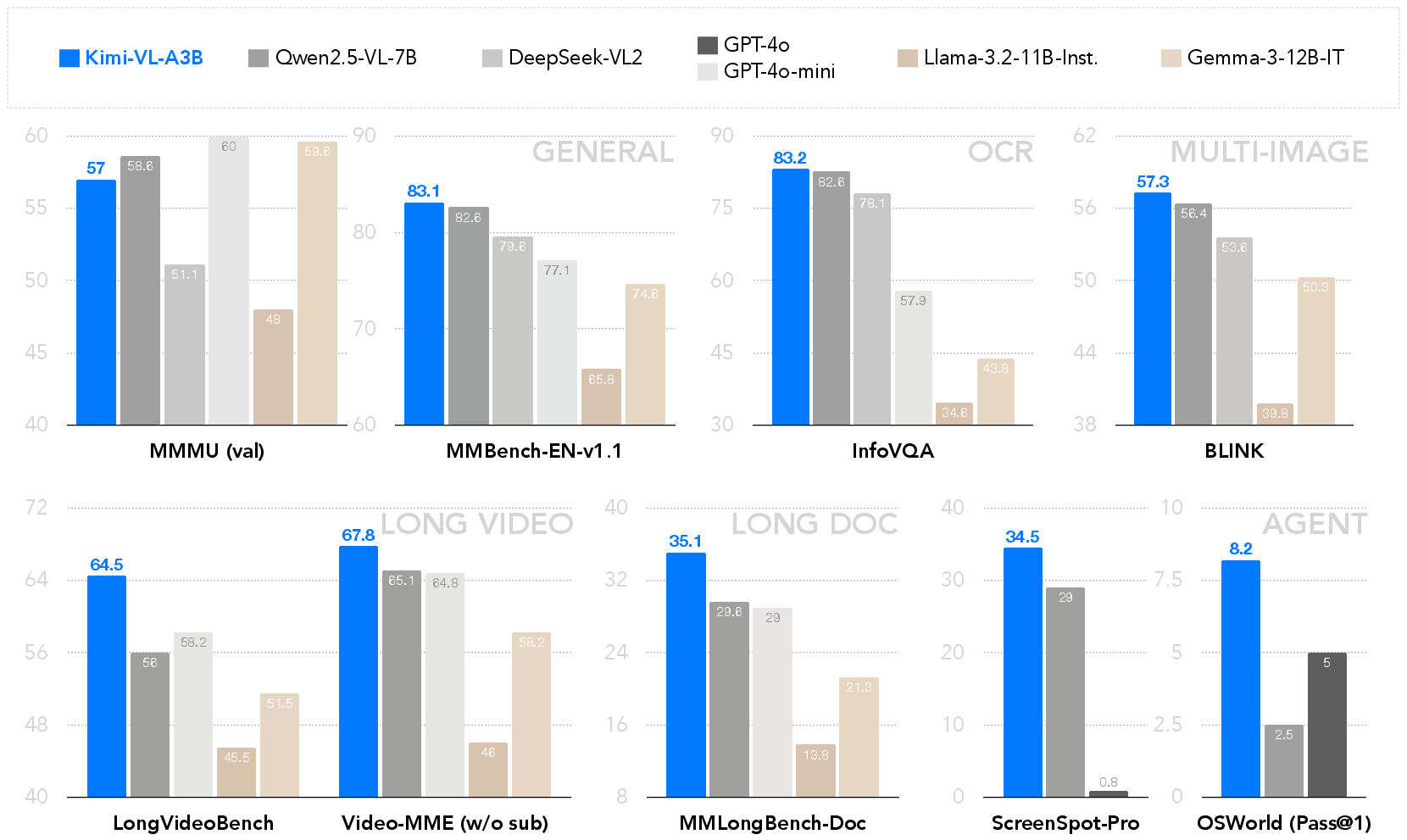
Figure 3: Highlights of Kimi-VL performance across general, OCR, multi-image, long video, document, and agent benchmarks.
Infrastructure and Optimization
The infrastructure supporting Kimi-VL emphasizes efficiency through parallel processing strategies including data, expert, pipeline, and context parallelism. These strategies significantly improve throughput, facilitating large-scale training operations with optimal resource utilization. Enhanced Muon optimization ensures robust data handling and parameter updating, contributing to seamless integration of multimodal inputs during training processes.
Conclusion
This report presents Kimi-VL as a highly efficient, multimodal VLM model, designed to excel in complex reasoning scenarios across various domains. Despite its optimized architecture, challenges regarding handling domain-specific or long-context tasks persist but are manageable with further scaling and algorithm refinement. Kimi-VL represents a substantial advancement in multimodal AI, setting the stage for future research and applications that require sophisticated understanding across image, text, and video modalities.