- The paper presents Seed1.5-VL, a multimodal model that combines a 532M-parameter vision encoder with a 20B MoE LLM to attain state-of-the-art results on numerous benchmarks.
- The methodology details native-resolution feature extraction, dynamic frame-resolution sampling for video, and a three-stage pre-training process followed by reinforcement learning.
- The model demonstrates robust capabilities in visual grounding, OCR, and video reasoning, though it faces challenges in fine-grained visual perception and complex spatial reasoning.
Seed1.5-VL: Advancing Multimodal Understanding and Reasoning
This technical report introduces Seed1.5-VL, a vision-language foundation model designed to enhance general-purpose multimodal understanding and reasoning. Composed of a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM with 20B active parameters, Seed1.5-VL achieves state-of-the-art performance on 38 out of 60 public benchmarks, demonstrating its capabilities across a wide range of tasks.
Architecture and Encoding Methods
The Seed1.5-VL architecture includes a vision encoder, an MLP adapter, and an LLM. The vision encoder, SeedViT, is designed for native-resolution feature extraction and consists of 532 million parameters. The overall architecture is shown in (Figure 1).
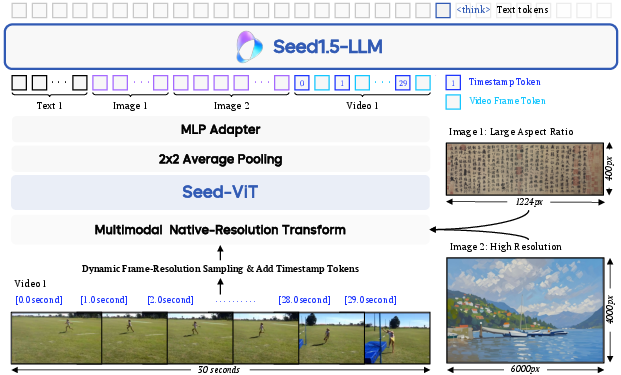
Figure 1: The architecture of Seed1.5-VL, illustrating the interaction between SeedViT, the MLP adapter, and the LLM.
Seed-ViT accommodates input images of varying dimensions, initially undergoing bilinear interpolation to adjust resolutions to the nearest multiple of 28×28 pixels. This is followed by segmenting each image into non-overlapping patches of 14×14 pixels. The architecture applies average pooling over adjacent 2×2 feature patches, and a two-layer MLP processes these pooled features before input to the LLM. The vision encoder employs 2D RoPE for positional encoding.
For video encoding, Seed1.5-VL uses Dynamic Frame-Resolution Sampling to optimize sampling across temporal (frame) and spatial (resolution) dimensions. Under this strategy, videos are processed as sequences of image frames, with the frame sampling frequency adjusted based on content complexity and task requirements. To explicitly ground each frame within the video's timeline, timestamp tokens are prepended to each frame. The spatial dimension is governed by dynamically adjusting the resolution allocated to each selected frame, managed within a maximum budget of 81,920 tokens per video.
Pre-training Data and Training
The Seed1.5-VL pre-training corpus contains 3 trillion tokens, categorized based on target capabilities, including generic image-text pairs, OCR, visual grounding, 3D spatial understanding, video, STEM, and GUI data. A targeted pre-processing framework addresses the imbalance between common and rare visual knowledge acquisition from image-alt-text pairs. Named entities exhibiting low corpus frequency are identified as instances of rare visual knowledge, and alt-texts corresponding to underrepresented domains are duplicated.
The VLM pre-training methodology is structured into three stages: alignment of the vision encoder with the LLM by training the MLP adapter, knowledge accumulation and mastering visual grounding and OCR capabilities, and creation of a balanced data mixture across different tasks and domains. AdamW optimizer is used in all three stages' training. The training loss for the majority of data sub-categories exhibits adherence to a scaling relationship, and the training loss achieved on specific data sub-categories can serve as a predictor for performance on related downstream tasks.
Post-training and Reinforcement Learning
The post-training stage equips Seed1.5-VL with robust instruction-following and reasoning abilities through a combination of Supervised Fine-tuning (SFT) and Reinforcement Learning (RL), beginning with an SFT model trained on curated cold-start data. Post-training proceeds iteratively: the SFT model is progressively enhanced by distilling the RL model's learnings on diverse prompts. This iterative refinement continues until the prompt pool is exhausted and performance metrics converge. The overview of post-training for Seed1.5-VL is shown in (Figure 2).
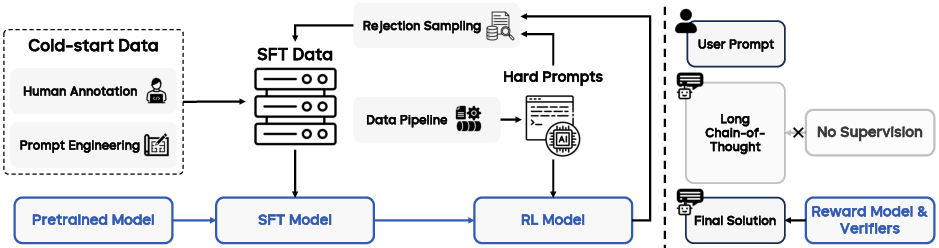
Figure 2: Post-training overview, showing the iterative update process combining rejection sampling and online reinforcement learning, focusing supervision on final outputs.
Our online reinforcement learning implementation employs a variant of the Proximal Policy Optimization (PPO) algorithm, with the reward signal derived from the probability assigned by a reward model to the generated answer tokens. Seed1.5-VL model is trained utilizing a hybrid RL framework, derived from a variant of the PPO algorithm. Our training is a combination of RLHF and RLVR.
Training Infrastructure and Evaluation
To accelerate and stabilize pretraining, training optimizations, including hybrid parallelism, workload balancing, parallelism-aware data loading, and robust training have been developed. We apply high-performance attention kernels for context parallelism, selective activation checkpointing and offloading, kernel fusion, and fine-grained communication overlapping.
Seed1.5-VL was evaluated on a comprehensive suite of public benchmarks, with quantitative results presented, followed by an assessment of performance on agentic tasks. The internal benchmark design and a comparison of the model against industry-leading models are detailed, followed by a discussion of model limitations.
GUI and Game Agent Benchmarks
For GUI grounding, Seed1.5-VL demonstrates strong grounding performance, achieving $60.9$ on ScreenSpot Pro and $95.2$ on ScreenSpot v2, which outperforms both OpenAI CUA and Claude 3.7 Sonnet. As illustrated in the paper, Seed1.5-VL consistently outperforms previous models on several key benchmarks, setting new state-of-the-art results on OSWorld, Windows Agent Arena, WebVoyager, and Online-Mind2Web, among others. (Figure 3) depicts the inference-time scaling behavior in gameplay.
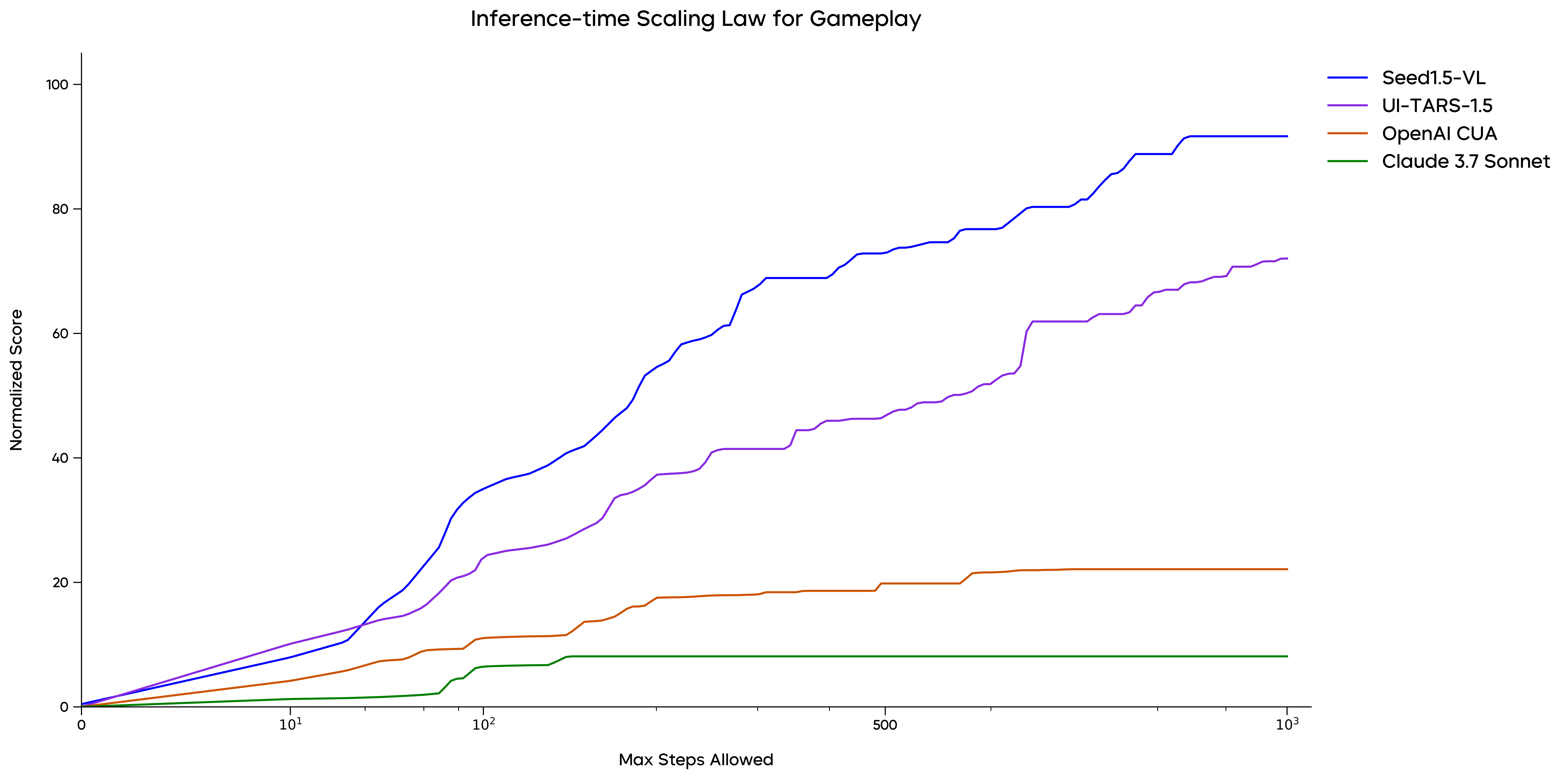
Figure 3: Inference-time scaling trend, showing consistent performance as interaction rounds increase in gameplay.
Limitations and Future Directions
Despite strong performance across many benchmarks, Seed1.5-VL exhibits certain limitations, particularly in fine-grained visual perception and complex reasoning. Seed1.5-VL struggles with accurately counting objects when they are irregularly arranged, similar in color, or partially occluded. Furthermore, similar to some contemporaries (e.g., OpenAI GPT-4o and Gemini 2.5 Pro), difficulties can arise in precisely interpreting complex spatial relationships, especially with varying perspectives.
Our scaling analysis indicates that model performance shows no sign of saturation, suggesting that increasing model parameters and training compute represents a promising immediate direction. Our ongoing research includes efforts towards unifying existing model capabilities with image generation (potentially enabling visual Chain-of-Thought) and incorporating robust tool-use mechanisms.
Conclusion
Seed1.5-VL is a multimodal foundation model demonstrating strong capabilities in reasoning, OCR, diagram understanding, visual grounding, 3D spatial understanding, and video understanding. Our scaling analysis indicates that model performance shows no sign of saturation, suggesting that increasing model parameters and training compute represents a promising immediate direction. Future research will focus on addressing limitations common to contemporary VLMs, such as robust 3D spatial reasoning, hallucination mitigation, and complex combinatorial search.