- The paper presents Heimdall, which employs reinforcement learning via PPO to enhance verification accuracy, achieving up to 97.5% with repeated sampling.
- It utilizes step-by-step chain-of-thought reasoning along with Majority Voting for robust automatic verification of mathematical solutions.
- Experimental results demonstrate a significant accuracy boost from baseline models, underscoring its potential in improving AI reliability and dataset integrity.
Heimdall: Test-Time Scaling on the Generative Verification
Introduction
The paper "Heimdall: test-time scaling on the generative verification" (2504.10337) introduces Heimdall, a novel LLM trained for verification during the test-time scaling process of generative tasks. Verification remains a critical component within AI systems, enabling these systems to maintain and create knowledge effectively. Despite the extensive research on problem-solving capabilities with LLMs enhanced by CoT reasoning, the verification dimension lacks comprehensive exploration. Heimdall targets this gap by specifically improving the verification accuracy using reinforcement learning (RL), reaching a remarkable increase in verification accuracy on mathematical problems.
Methodology
Heimdall employs Proximal Policy Optimization (PPO) for reinforcement learning to enhance verification accuracy. The RL setup involves filtering specific problems to ensure effective data processing, focusing on contrasting cases, which expedites the learning process. The training method emphasizes solutions where Heimdall verifies solution correctness via step-by-step CoT reasoning. A specially designed prompt guides the model through verifying solution correctness, using forward and backward checking techniques, as illustrated in multiple verification scenarios.
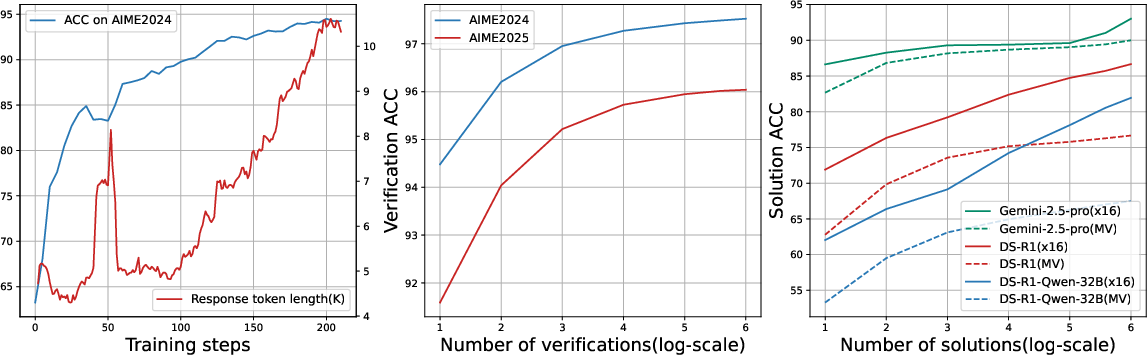
Figure 1: Scaling of Heimdall. Left: the verification accuracy scales with response length; Middle: accuracy scales with repeated sampling; Right: problem solving accuracy scales with the number of solutions.
The algorithm incorporates repeated sampling and Majority Voting for judgment augmentation, achieving significant improvements in verification accuracy. Through an iterative process, Heimdall effectively scales its verification ability with problem-solving scenarios, demonstrating superior performance over existing baseline models.
Results and Implications
Heimdall achieves impressive results, advancing verification accuracy from 62.5% to 94.5%, and further to 97.5% with repeated sampling. The implementation of Pessimistic Verification optimizes problem-solving by minimizing uncertainty and adjusting for compute constraints, enhancing solution accuracy significantly.
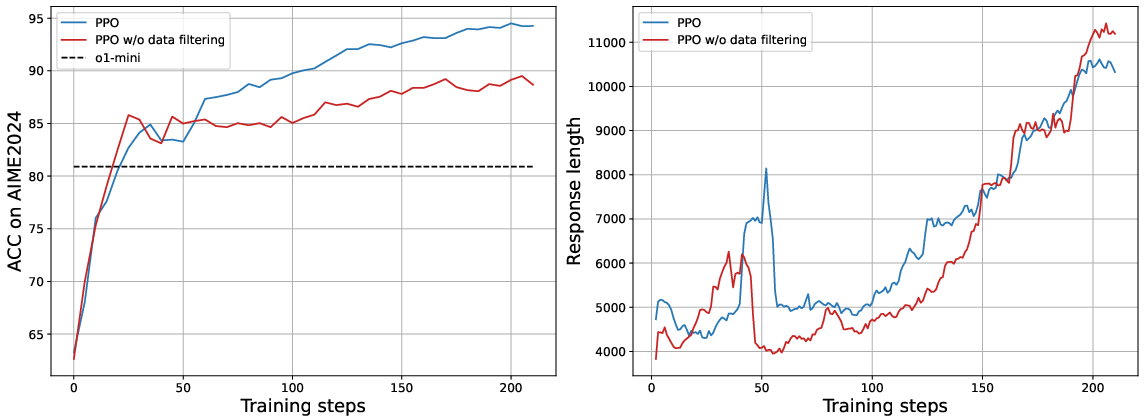
Figure 2: Accuracy and response length during RL training. Normal RL converges faster after filtering problematic datasets, shown in left and right plots respectively.
Heimdall's verification framework optimally collaborates with solver models, drastically improving accuracy—as evidenced from the uplift from DeepSeek-R1-Distill-Qwen-32B’s baseline results from 54.2% to 83.3% with an extended compute budget. Moreover, when incorporated with more advanced solver models such as Gemini 2.5 Pro, Heimdall reaches 93% accuracy, aligning with current state-of-the-art techniques.
The paper further showcases Heimdall’s utility in an automatic knowledge discovery system where it successfully identifies erroneous data within a synthetic dataset. This highlights Heimdall’s potential in ensuring dataset integrity and its broader implications in sustainable AI training paradigms.
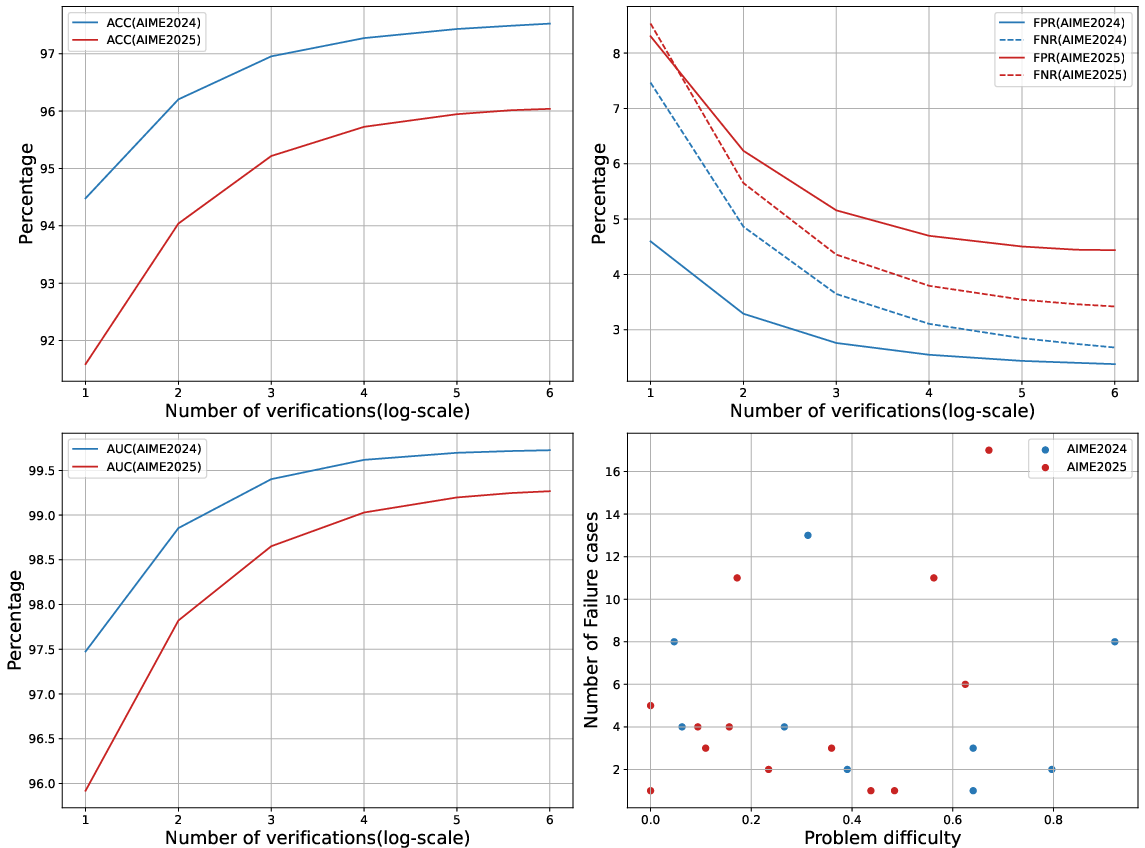
Figure 3: The inference-time scaling of verification on AIME datasets showcasing accuracy enhancement with verification multiplicity.
Discussion and Future Work
The extension of Heimdall into domains such as coding and proof verification is a promising future endeavor. Current results demonstrate Heimdall’s excellent generalization capability; however, integrating more diverse datasets could further reinforce its adaptability. Additionally, the creation of high-fidelity synthetic datasets remains a substantial challenge; the application of Heimdall in this domain could provide a pathway to improved data quality through rigorous verification mechanisms.
Simultaneously, the exploration of autonomous knowledge generation processes poses new challenges, potentially benefitting from an AI-driven inquisitive capability harmonized with Heimdall’s verification acumen. These explorations may well align with breakthroughs in both theoretical and applied AI research, reinforcing the robustness of autonomous systems driven by LLMs.
Conclusion
Heimdall substantiates a methodological leap in generative verification, leveraging reinforcement learning to refine CoT reasoning capabilities for competitive tasks. With innovations like Pessimistic Verification, it fosters synergistic collaboration between problem-solving solvers and verification, positioning verification as an instrumental component in enhancing AI’s problem-solving repertoire. The paper reinforces the significance of verification in embedding reliability within autonomous AI systems, paving pathways for future exploration in transparent and verifiable AI processes.

