- The paper introduces SAT-Graph RAG which integrates a formal legal ontology with structural and temporal segmentation for deterministic retrieval.
- It employs a multi-layered knowledge graph that models hierarchical components, language versions, and legislative actions for precise versioning.
- The framework facilitates auditable provenance reconstruction and efficient impact analysis, as demonstrated on the Brazilian Constitution.
Ontology-Driven Graph RAG for Legal Norms: Structural, Temporal, and Deterministic Retrieval
Introduction
The paper presents the Structure-Aware Temporal Graph RAG (SAT-Graph RAG), an ontology-driven framework for Retrieval-Augmented Generation (RAG) in the legal domain. It addresses the limitations of standard RAG systems, which are typically temporally-naïve and structurally flat, by explicitly modeling the hierarchical, diachronic, and causal structure of legal norms. The approach is grounded in a formal, LRMoo-inspired ontology, enabling deterministic, auditable, and context-rich retrieval for legal AI applications.
The SAT-Graph RAG framework is built upon a multi-layered ontological model that distinguishes between abstract legal Works, their hierarchical Components, Temporal Versions (CTVs), and Language Versions (CLVs). This separation allows for precise modeling of the evolution of legal texts over time and across languages.
The graph construction process begins with structure-aware semantic segmentation of legal texts, mapping each segment to its corresponding hierarchical component (e.g., Title, Chapter, Article). These components are instantiated as nodes in the knowledge graph, forming a backbone that mirrors the formal structure of the legal document.

Figure 1: Example of articulated text for Art. 12 of the Federal Constitution of Brazil (1988) with annotations indicating the types of hierarchical provisions/components.

Figure 2: Hierarchical semantic segmentation and typification of structural entities applied to a passage of the Brazilian Constitution, with Norms in green and Components in blue.
Textual content is linked to the most specific layer—Language Version nodes—ensuring that every retrievable text unit is unambiguously tied to both a semantic state and a linguistic expression.
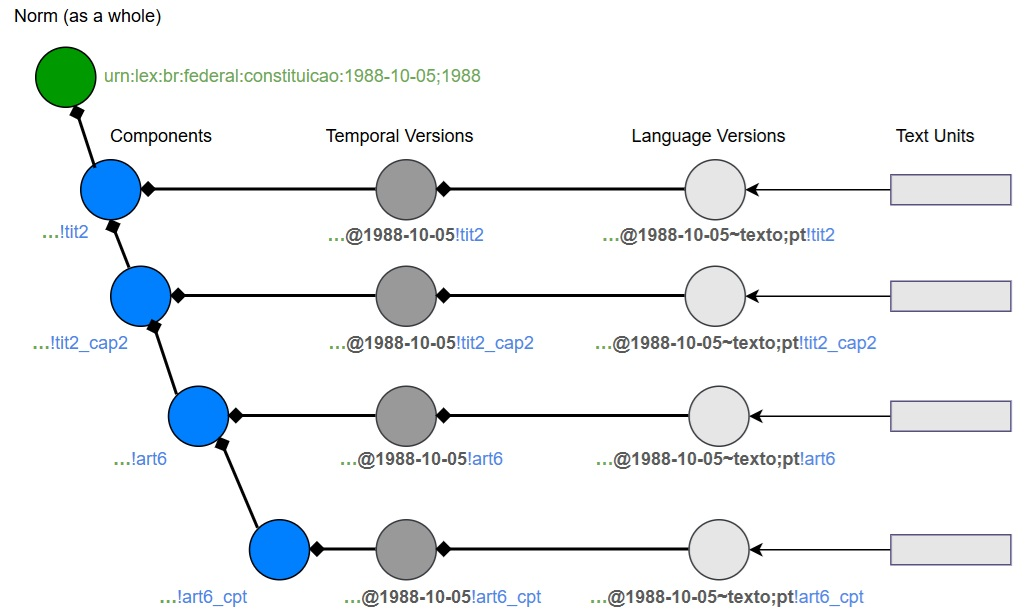
Figure 3: Multi-layered relationship in the graph: Norms have hierarchical Components, which have date-stamped Temporal Versions, which in turn have language-specific Language Versions. Text Chunks are linked to the CLVs.
The model elegantly supports multilingual corpora by associating new Language Versions with pre-existing Temporal Versions, avoiding duplication of structural information.
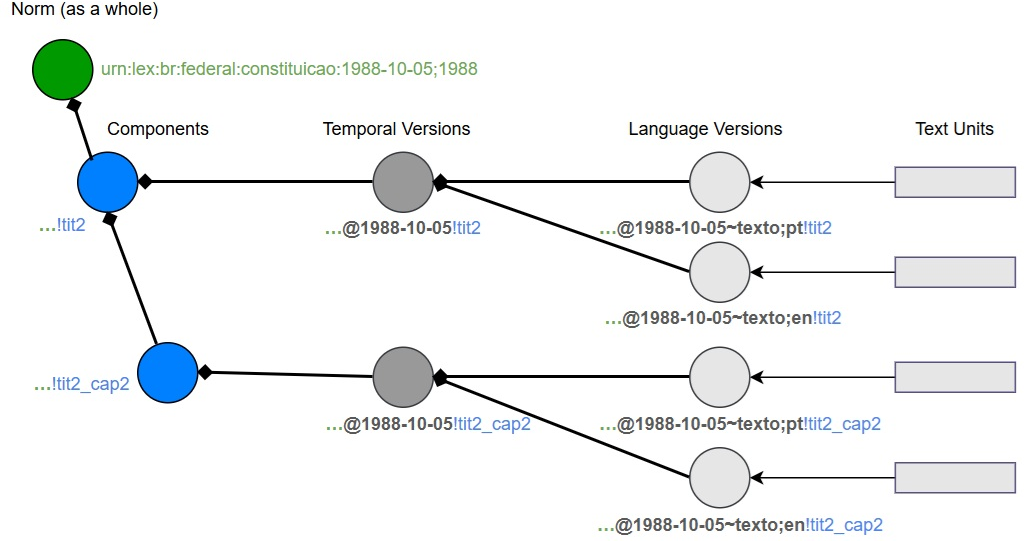
Figure 4: Representation of multilingual content (Portuguese and English) linked to the same temporal and structural backbone.
Temporal Aggregation and Efficient Versioning
A key innovation is the aggregation model for propagating changes. When a component is amended, only the affected child receives a new Temporal Version; parent components aggregate the latest available versions of their children, reusing unchanged CTVs. This avoids redundancy and enables efficient, deterministic reconstruction of the law's state at any point in time.
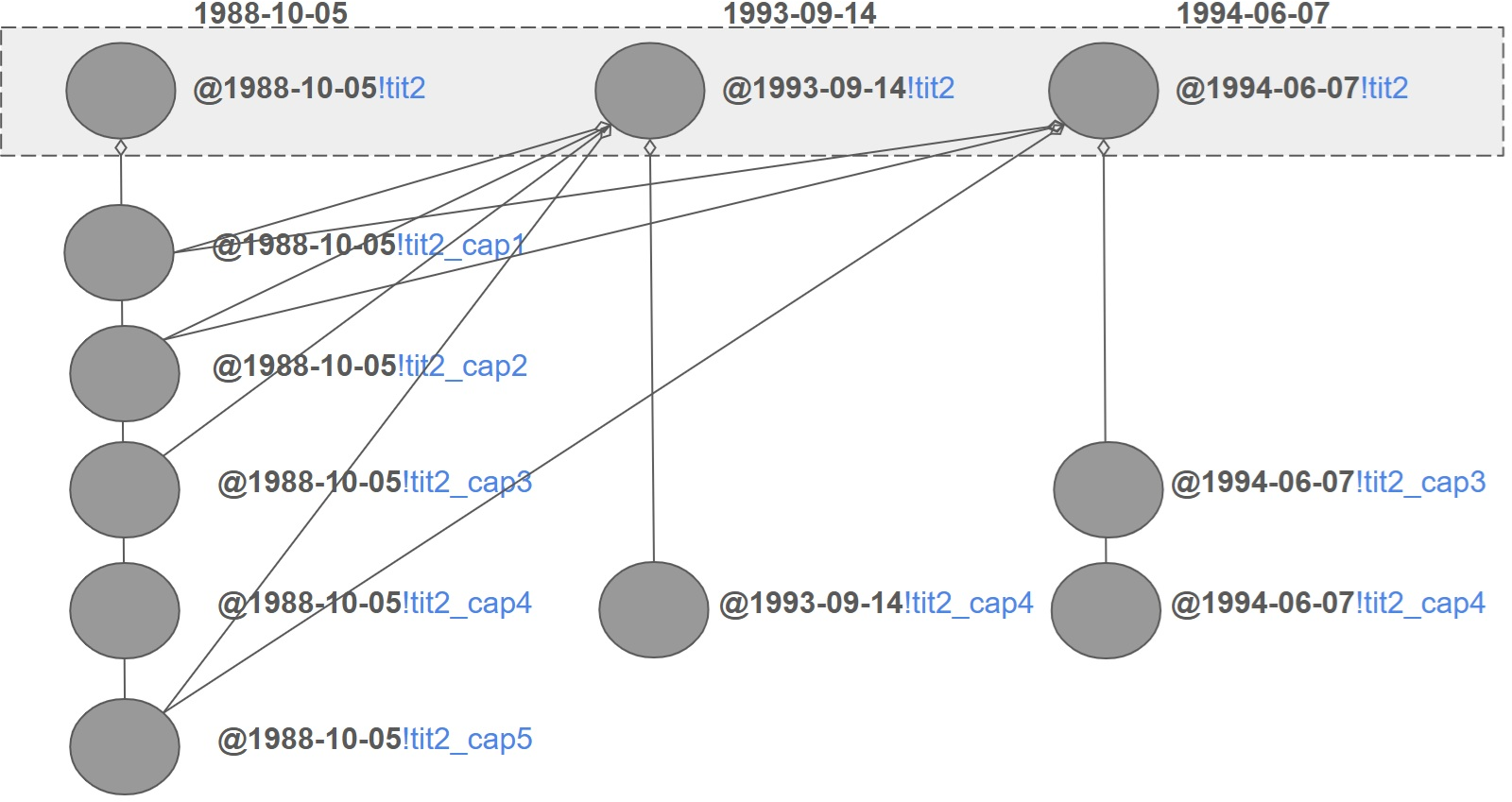
Figure 5: New Temporal Versions of "tit2" (Title II) derived from new CTVs of some children, with unchanged child components reusing their most recent CTVs.
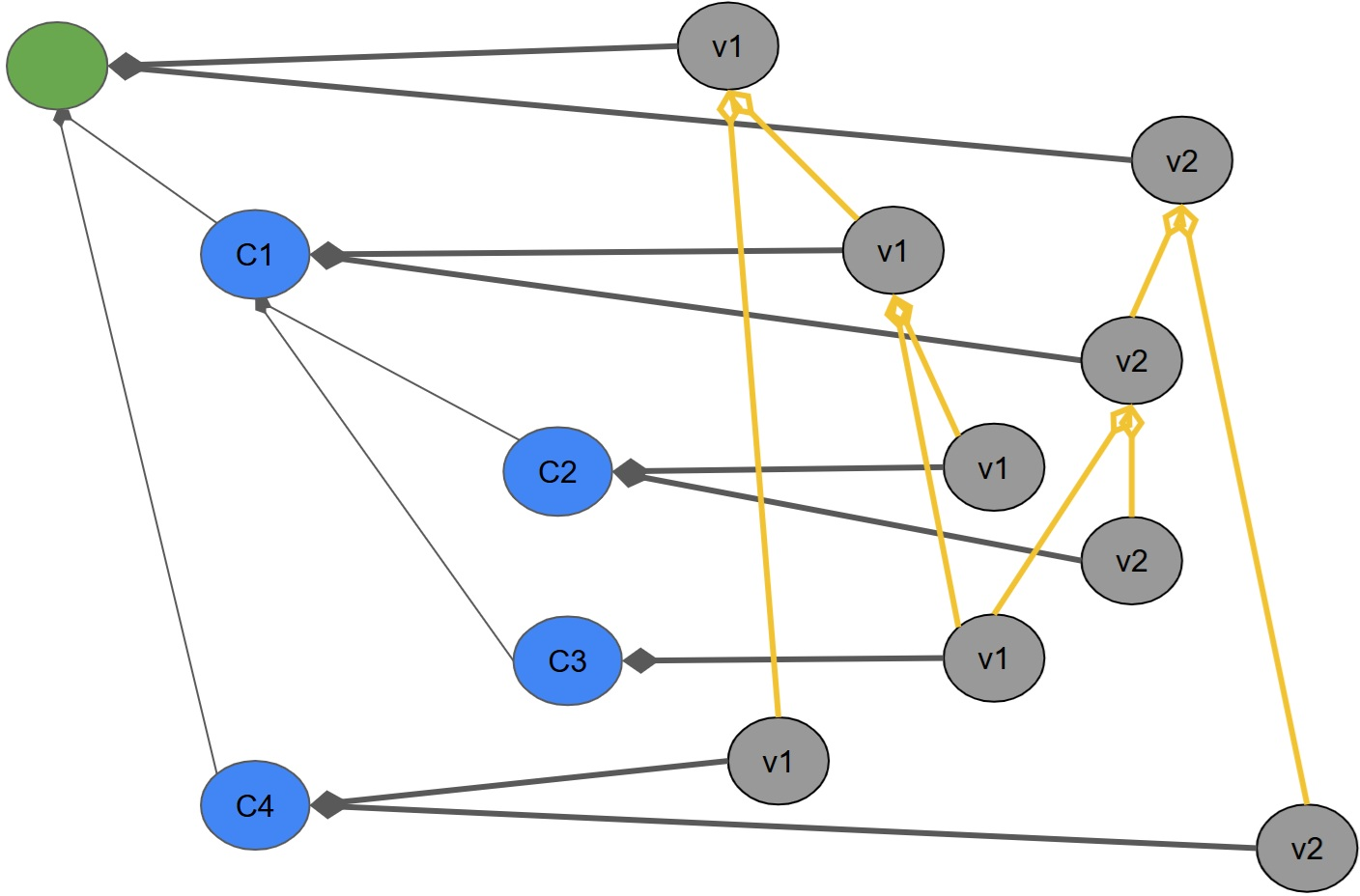
Figure 6: Aggregation relationships between Temporal Versions, showing reuse of child CTVs by multiple parent CTVs at different times.
Legislative events (amendments, repeals, enactments) are modeled as Action nodes, making causality explicit and queryable. Each Action node is associated with a descriptive Text Unit, enabling semantic search over legislative history and provenance.
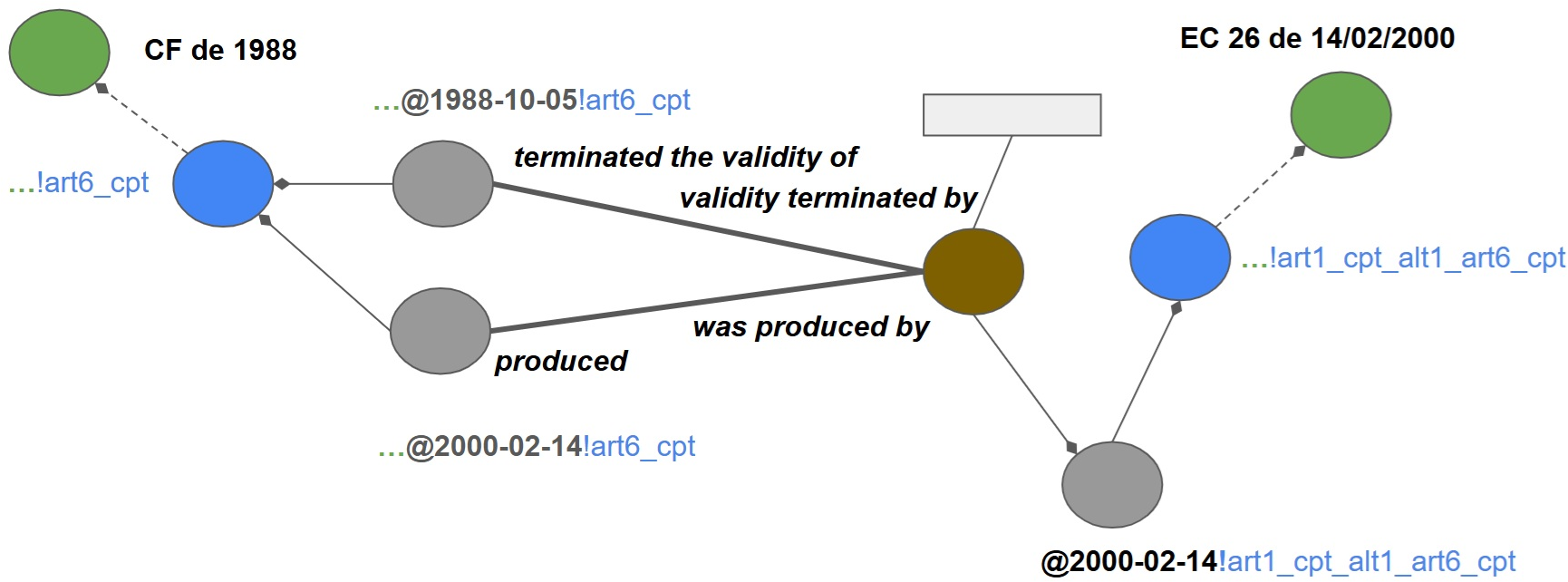
Figure 7: Legislative Action in the knowledge graph, showing how an amendment terminates the validity of an old CTV and produces a new one.
Structured metadata and informative relationships are also textualized into dedicated Text Units, supporting multi-aspect retrieval and enabling queries over both content and context.
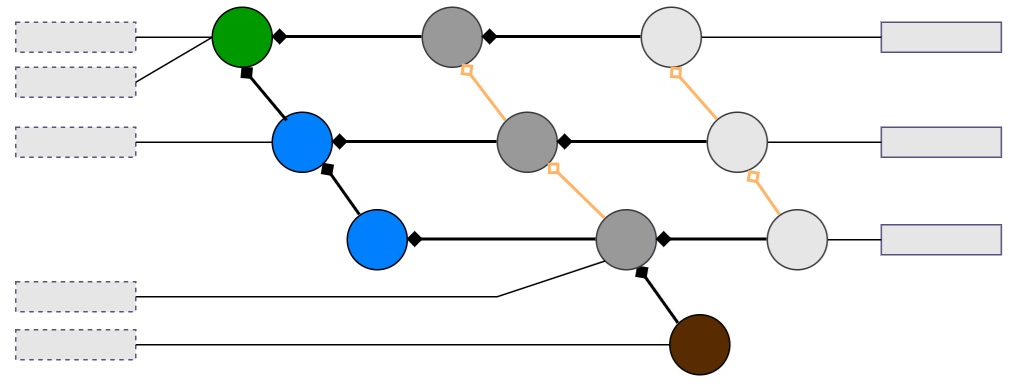
Figure 8: Knowledge graph illustrating Text Units derived from Language Versions (content) and other entities (Norm, Component, Temporal Version, Action) representing metadata and relationships.
Structure-Aware and Thematic Retrieval
The framework leverages curated communities intrinsic to legal documents: internal hierarchy (structural communities) and external thematic classification (topical communities). Theme nodes group Norms and Components by legal topics, each with a human-authored description, enabling cross-document, topically-coherent retrieval.
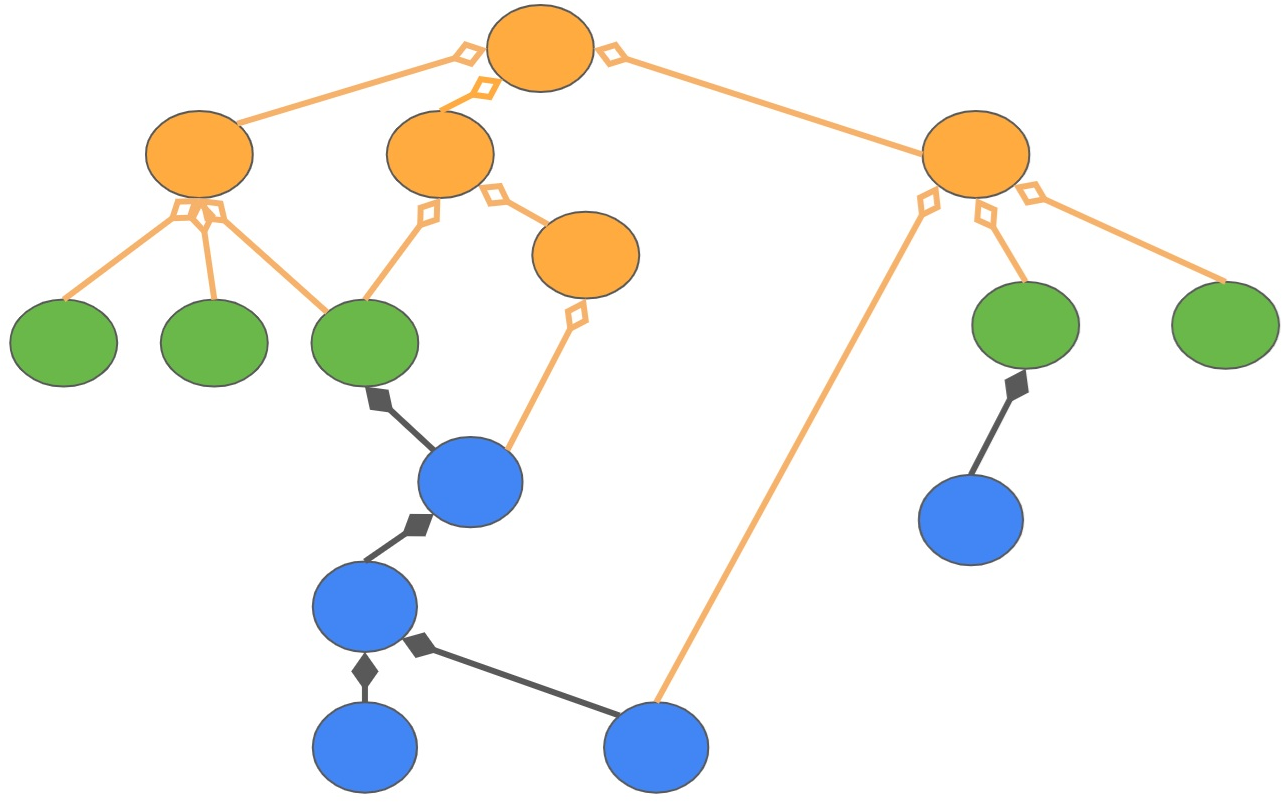
Figure 9: Inter-norm and component aggregation by legal Theme entities, representing higher-level communities in the knowledge graph.
Users can select a scope (Theme, Norm, Component, or Version) to filter retrieval, transforming search from a flat corpus-wide operation to semantic navigation within a contextually relevant subgraph.
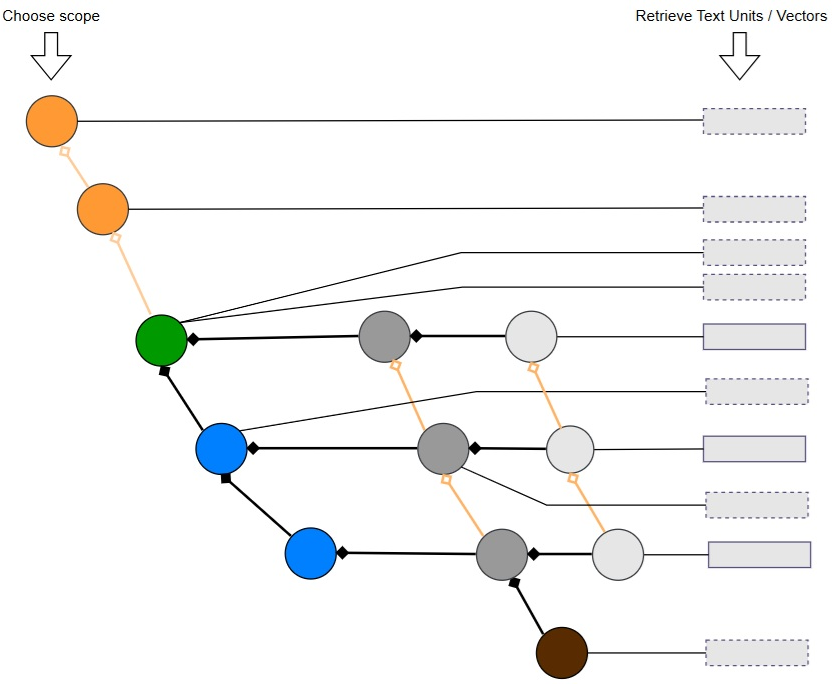
Figure 10: User selection of scope (Theme, Norm, Component, or Version) to filter retrieval of relevant Text Units from the knowledge graph.
Case Study: Brazilian Constitution
The framework is demonstrated on the Brazilian Federal Constitution of 1988, which has undergone extensive amendment. The case study illustrates three critical capabilities:
- Deterministic Point-in-Time Retrieval: The system retrieves the exact version of a provision valid on any historical date, using a planner-guided query strategy that canonicalizes structural and temporal constraints, traverses the graph to select valid CTVs, and retrieves the corresponding CLVs.
- Hierarchical Impact Analysis: The system aggregates legislative changes across structural sections (e.g., all amendments to Chapter II after 2010), leveraging the explicit hierarchy and Action nodes to produce structured summaries.
- Auditable Provenance Reconstruction: The system traces the full causal lineage of textual changes, assembling ordered chains of Action nodes and providing machine-readable provenance reports.

Figure 11: Original Version and subsequent Versions of Article 6 of the Brazilian Constitution generated by three Constitutional Amendments.
Unified, Deterministic Query Execution
A modular, planner-guided execution strategy supports all query patterns, centralizing constraint extraction, scope resolution, strategy selection, deterministic CTV selection, and fact-grounded generation. Operational defaults (embedding model, similarity function, temporal policy) are disclosed with each response, ensuring auditability and reproducibility.
Discussion: Implications, Scalability, and Evaluation
The SAT-Graph RAG framework offers deterministic, explainable retrieval for legal AI, supporting high-stakes applications where precision and auditability are paramount. Its scalability depends on principled data curation, incremental processing, and robust validation workflows. The approach generalizes to other domains with explicit structure and versioning, such as contracts and technical documentation.
Quantitative evaluation requires dedicated benchmarks measuring temporal precision, action-attribution accuracy, causal-chain completeness, and user-centered metrics. The development of annotated testbeds is advocated to enable reproducible comparison of temporally-aware legal retrieval systems.
Ethical deployment mandates transparency of internal policies, equitable access to high-quality legal data, and immutable audit logs for all graph updates.
Conclusion
The SAT-Graph RAG framework advances legal AI by integrating formal document structure, temporal versioning, and explicit causality into a unified, ontology-driven knowledge graph. It enables deterministic, auditable retrieval and higher-order analytical capabilities, addressing the critical limitations of standard RAG systems in the legal domain. The approach lays a robust foundation for trustworthy, explainable legal AI, with future work focused on formal ontology publication, benchmark development, and extension to other domains and hybrid models.