- The paper introduces DualDiff, a dual-branch diffusion model that integrates occupancy ray sampling and numerical scene representations for enhanced scene fidelity.
- It leverages Semantic Fusion Attention to synchronously fuse multi-modal data, achieving state-of-the-art performance in FID and 3D object detection on the nuScenes dataset.
- The work improves synthetic training data realism and accuracy, offering practical benefits for downstream autonomous driving tasks like object detection and segmentation.
DualDiff: Enhancing Scene Reconstruction for Autonomous Driving
Introduction
The paper introduces a novel method, DualDiff, a dual-branch diffusion model designed to improve multi-view driving scene generation for autonomous driving applications. Unlike traditional methods that rely primarily on 3D bounding boxes and binary maps for constraining the scene, DualDiff employs a dual-branch architecture leveraging Occupancy Ray Sampling (ORS) and numerical driving scene representations, aiming for a more comprehensive control over both foreground and background elements. This paper proposes a Semantic Fusion Attention (SFA) mechanism to align and integrate features across different modalities, ultimately achieving higher fidelity scene reconstruction with enhanced generation of tiny objects through a foreground-aware masked (FGM) loss.
Methodology
Dual-branch Architecture
DualDiff's architecture features two distinct branches focused respectively on foreground and background generation. The foreground branch utilizes ORS, a semantic-rich 3D representation, which effectively samples features along camera-originated rays to offer a condensed capture of the scene. In parallel, numerical driving scene representations are employed, providing fine granularity through vectorized maps and bounding boxes, ensuring detailed and balanced scene representation. The dual-branch configuration facilitates comprehensive integration of these inputs, enhancing scene reconstruction fidelity.
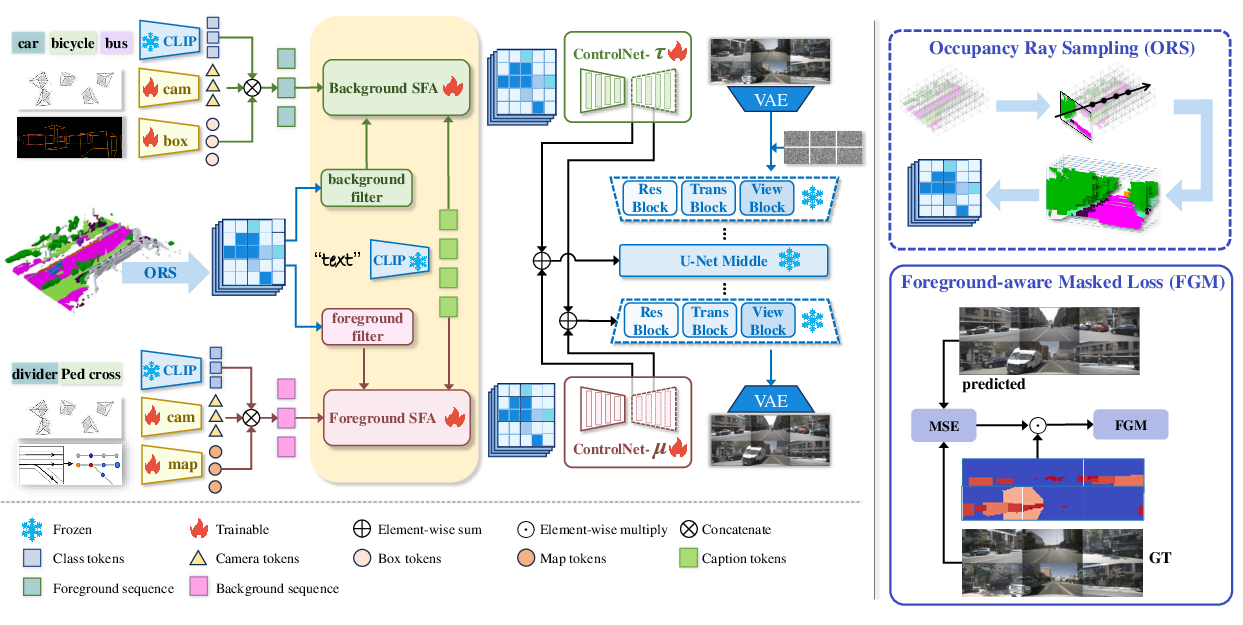
Figure 1: Overview of DualDiff for multi-view image generation. We use occupancy ray sampling (ORS) and numerical driving scene representation.
Semantic Fusion Attention
The Semantic Fusion Attention (SFA) module is crucial for cross-modal feature integration, updating ORS features with spatial modalities like bounding boxes and vectorized maps, along with semantic textual cues. By applying self-attention and gated mechanisms, SFA enriches visual features with spatial and semantic information, ensuring that the generated scenes are both geometrically consistent and contextually accurate.
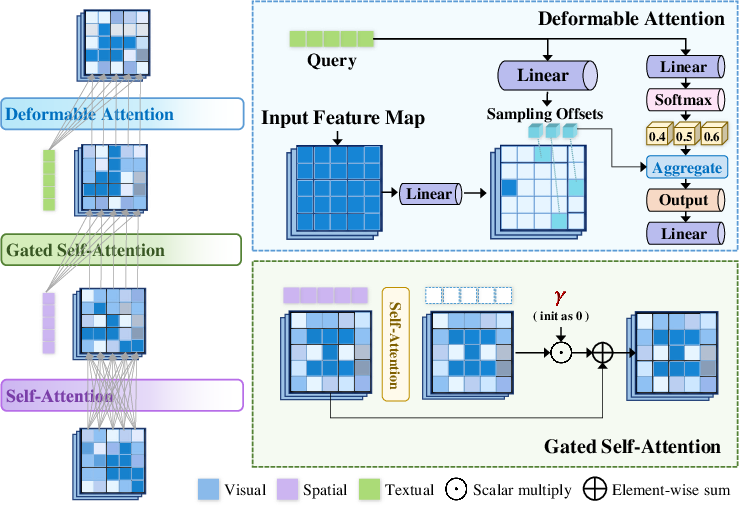
Figure 2: Illustrations of our proposed Semantic Fusion Attention (SFA), which sequentially fuses ORS features with multi-modal information.
Results and Evaluation
DualDiff achieves state-of-the-art performance across several evaluation metrics, including the Fréchet Inception Distance (FID) and tasks related to BEV segmentation and 3D object detection, as evidenced by the results on the nuScenes dataset. The introduction of the ORS representation and the dual-branch configuration has led to a significant reduction in FID, indicating enhanced realism of the generated driving scenes.
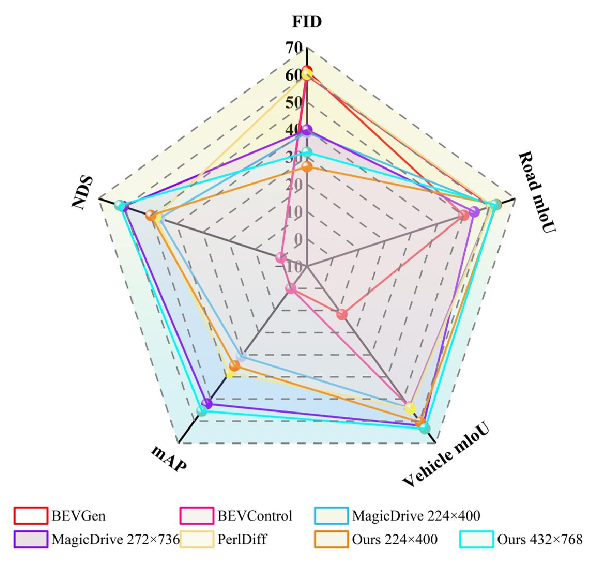
Figure 3: We have achieved state-of-the-art performance in several evaluation metrics compared to other custom or base models.
Additionally, the integration of SFA and FGM loss results in superior handling of tiny objects, critical for tasks requiring high precision in scene details.
Implications and Future Directions
The advances presented in DualDiff have practical implications for autonomous driving systems, notably improving the realism and accuracy of synthetic training data. This model potentially enhances downstream tasks such as object detection and semantic segmentation by providing more precise scene details and generating data that bridges the domain gap present in synthetic-to-real scenarios.
Looking ahead, future research could explore extending this dual-branch approach to other domains, examining its effectiveness in non-3D spaces or with alternative sensing data. Further developments could also seek to refine the integration mechanisms within SFA, exploring additional modalities or more sophisticated multi-modal interactions to further improve the fidelity and applicability of generated scenes.
Conclusion
DualDiff represents a significant contribution to scene generation in autonomous driving contexts, leveraging a novel dual-branch architecture and advanced cross-modal integration techniques to achieve improved accuracy and fidelity. These advancements not only address existing challenges in scene complexity representation but also lay the groundwork for future enhancements in simulation and real-world application of autonomous driving technologies. Across various metrics, DualDiff sets a new benchmark, underlining its potential to enhance the development and training processes within the autonomous vehicle domain.

Figure 4: Reconstruction scene in daylight, where our model generates the bus in distance and the lamp pole correctly.