- The paper presents a hybrid approach combining diffusion models with supervised learning to improve multimodal trajectory prediction and control precision.
- It features a hierarchical Transformer-based architecture with bidirectional cross-attention for robust sensor fusion and structured latent space modeling.
- Experimental evaluations on CARLA and NAVSIM benchmarks demonstrate significant improvements in driving score, route completion, and safety metrics compared to traditional methods.
DiffE2E: Rethinking End-to-End Driving with a Hybrid Action Diffusion and Supervised Policy
The paper introduces DiffE2E, a novel framework for end-to-end autonomous driving utilizing a hybrid approach combining diffusion models with supervised learning. The method addresses the central challenges of multimodal behavior modeling and generalization in complex driving scenarios, offering improved robustness and performance over traditional supervised learning techniques.
Introduction
End-to-end autonomous driving frameworks aim to map sensory inputs directly to control commands, circumventing error propagation issues inherent in traditional modular systems. Despite advancements, supervised learning-based policies often struggle with suboptimal solutions due to the multimodal nature of driving behaviors, as well as a decline in performance when faced with data distribution shifts in open scenarios. DiffE2E proposes a hybrid approach using diffusion models to capture a richer distribution of future trajectories and supervised learning to enhance control precision.
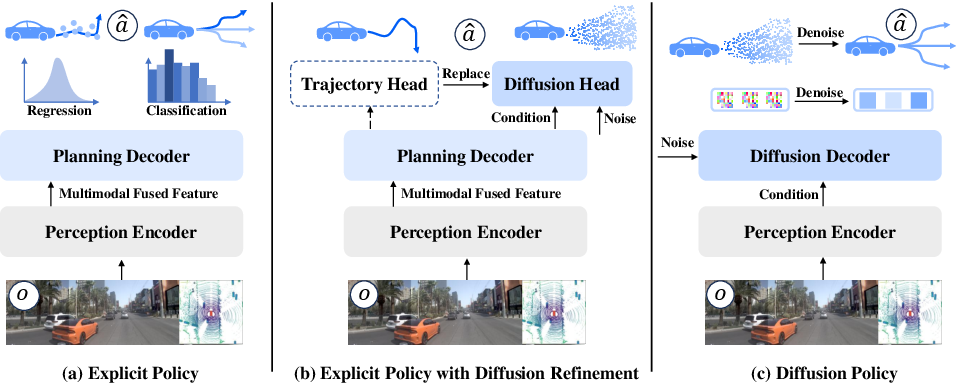
Figure 1: Comparison of end-to-end training paradigms showcasing the role of diffusion in policy generation.
Framework Architecture
DiffE2E comprises a hierarchical bidirectional cross-attention perception module paired with a hybrid diffusion-supervision decoder based on the Transformer architecture. This architecture allows for structured latent space modeling where diffusion captures multimodal trajectory distributions, while supervision focuses on control element refinement.
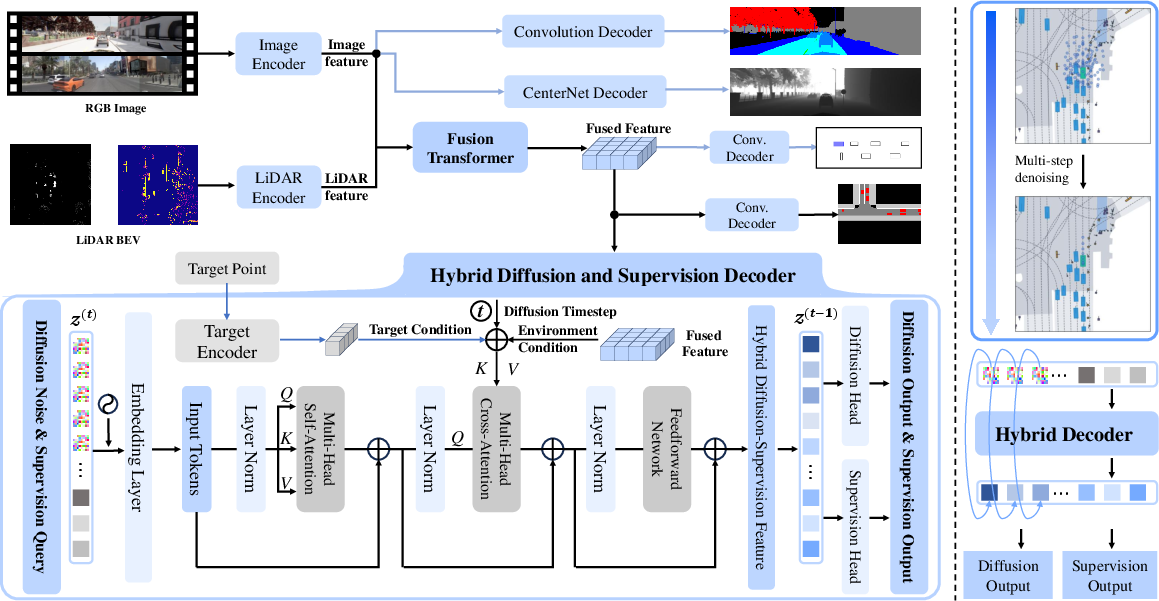
Figure 2: Overall architecture of DiffE2E, highlighting the integration of Transformer-based perception and hybrid decoder modules for enhanced trajectory generation.
Perception Module
The perception module aligns multi-sensor inputs (LiDAR, camera) through cross-attention mechanisms, forming a comprehensive environmental representation crucial for subsequent decision-making. This structured perceptual foundation enables robust interpretation necessary for trajectory prediction.
Hybrid Decoder
The hybrid diffusion-supervision decoder simultaneously employs diffusion processes for trajectory diversity and explicit supervision for fine-grained control modeling. This collaboration facilitates dynamic feature interactions and structured output generation, promoting effective learning and adaptability in diverse scenarios.
Training Strategy
DiffE2E employs a collaborative training strategy integrating diffusion and supervised learning. The diffusion process is optimized using a reconstruction-based loss approach, whereas supervised learning employs multi-task strategies with weighted formulations to address specific control aspects such as speed prediction accuracy.
Experimentation
CARLA Simulator Evaluation
DiffE2E was evaluated using the CARLA simulator, demonstrating superior performance in the Longest6 benchmark with a Driving Score (DS) increase of 13.7% over the TF++WP baseline and near-optimal Route Completion (RC) scores. The visual results revealed DiffE2E's adaptability in dynamic traffic, effectively adjusting trajectories in novel situations.

Figure 3: Visualization in CARLA Simulator illustrating DiffE2E's trajectory adaptation in intersection scenarios.
NAVSIM Analysis
On the NAVSIM benchmark, DiffE2E achieved a PDMS score of 92.7, surpassing existing models by utilizing the diffusion-based approach for multimodal driving assessments. This performance remained consistently high across key metrics like No at-fault Collision, Drivable Area Compliance, and Time-To-Collision.
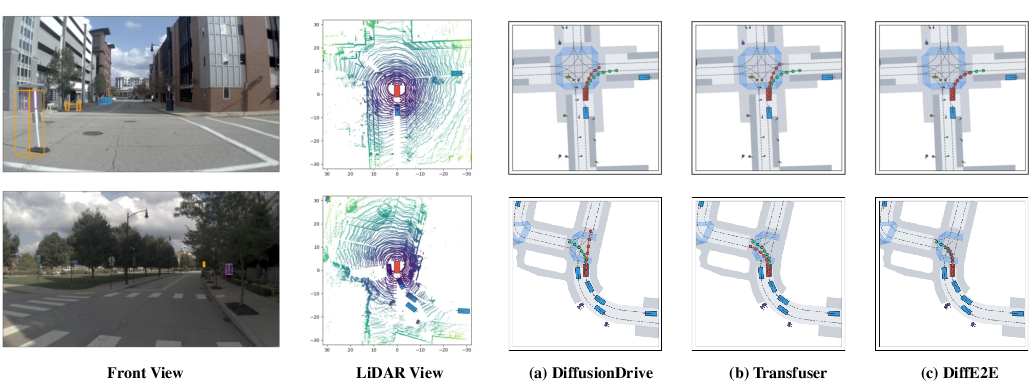
Figure 4: Visualization on Navtest benchmark validating DiffE2E's trajectory accuracy against real-world benchmarks.
Ablation Studies
Ablation studies confirmed the significance of each DiffE2E component, particularly emphasizing the importance of ego state and navigation command in model performance. Further analysis revealed optimal denoising step configurations that balanced efficiency and trajectory quality essential for real-time applications.
Figure 5: Ablation study of denoising steps on Navtest benchmark highlighting performance impact.
Conclusion
DiffE2E represents a substantial advancement in autonomous driving frameworks, integrating diffusion models for versatile trajectory generation with explicit policy supervision for control precision. Its success across closed-loop simulations and real-world benchmark tests showcases the potential for such hybrid implementations to improve future AI-driven autonomous systems, paving the way for enhanced multimodal decision-making capabilities.