- The paper proposes MPA as a unified framework to address observation and objective mismatches in closed-loop autonomous driving.
- It employs counterfactual data generation via a 3DGS simulator and a diffusion-based adapter to predict residual corrections for robust multimodal action selection.
- Experimental evaluations demonstrate significant improvements in Route Completion and HDScore, enhancing safety and generalization across diverse urban scenarios.
Model-Based Policy Adaptation for Closed-Loop End-to-End Autonomous Driving
End-to-End (E2E) autonomous driving has experienced substantial gains in perception-planning integration, yielding strong open-loop performance on urban benchmarks. However, a marked deficiency remains: E2E agents, when deployed in closed-loop settings, exhibit cascading error accumulation driven by both observation mismatch (the divergence between the training-time sensor input distribution and the evolved closed-loop input distribution) and objective mismatch (the disconnect between supervised learning objectives and the true long-horizon utility maximization). This induces severe distributional shift and substantially impedes generalization and safety.
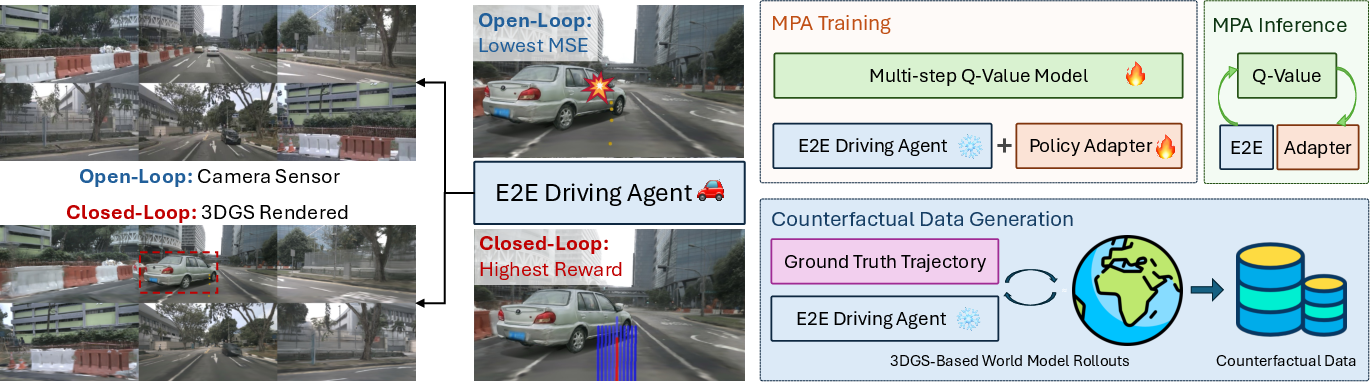
Figure 1: The left panel shows how closed-loop performance degradation arises from observation and objective mismatches. The right panel summarizes the MPA proposal: counterfactual data generation addresses observation mismatch, while model-based policy adaptation targets objective mismatch.
Given the limits of existing works—such as lacking counterfactual data in policy refinement phases or relying on simulators with low photorealism (e.g., CARLA)—the paper "Model-Based Policy Adaptation for Closed-Loop End-to-End Autonomous Driving" (2511.21584) systematically analyzes sources of closed-loop degradation. The authors propose Model-Based Policy Adaptation (MPA) as a unified framework directly remediating both mismatches in robust, closed-loop E2E autonomous driving.
Model-Based Policy Adaptation (MPA) Framework
The MPA pipeline consists of three principal stages:
- Counterfactual Data Generation: Pretrained E2E policies are employed within a geometry-consistent 3DGS-based urban driving simulator for rollouts, with behavioral augmentation (rotation, warping, and noise) generating diverse, out-of-domain samples. Artifacts are discarded using distance and reward filters to ensure physical plausibility.
- Diffusion-Based Policy Adapter: A diffusion model learns a residual policy on the counterfactual dataset, predicting corrections to the base policy’s output. This design captures the inherent multimodality in the action space due to behavioral perturbations.
- Multi-Principle Q-Value Model: A Q-function ensemble is trained to estimate cumulative rewards across interpretable driving principles (route completion, lateral distance, collision avoidance, speed compliance), supplying value-based action selection at test time.
At inference, the diffusion adapter proposes multiple trajectory candidates; the value model selects the one with the highest expected utility.
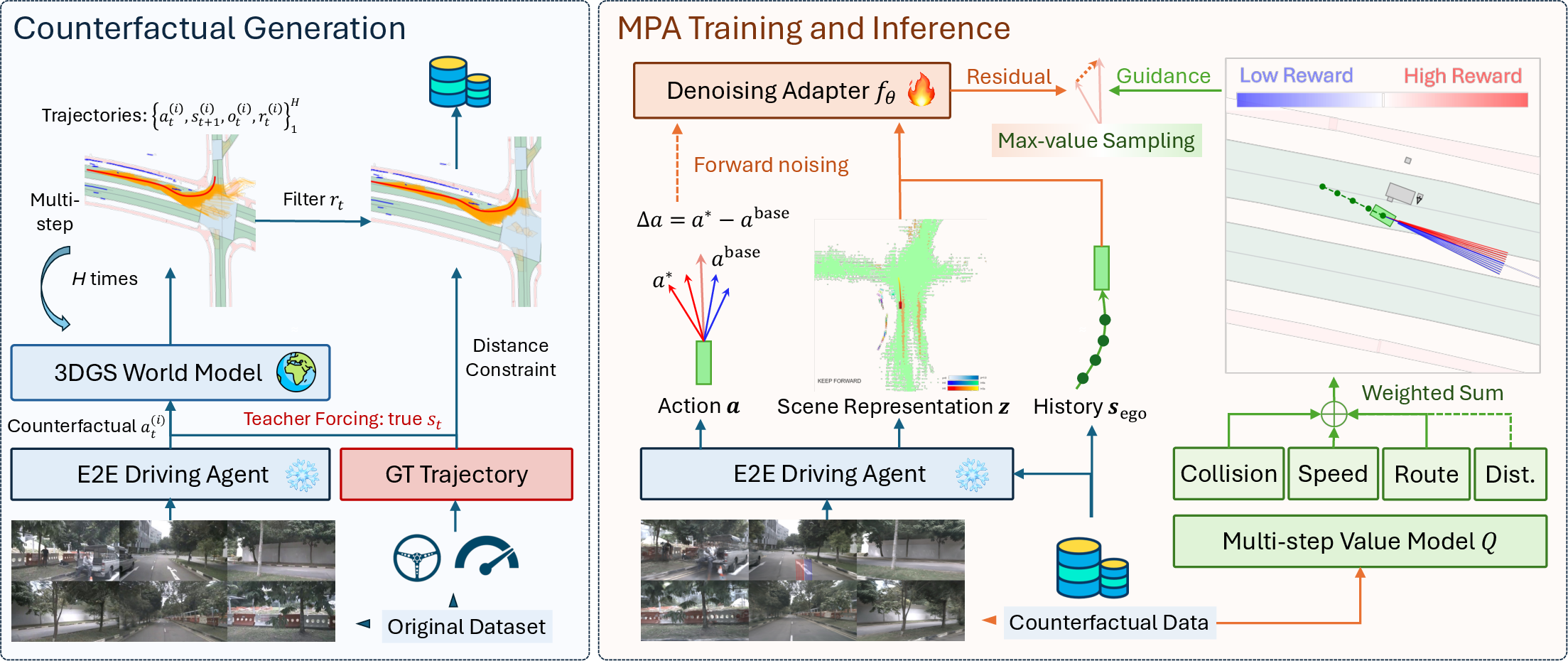
Figure 2: The MPA pipeline—counterfactual data generation (left) creates diverse rollouts, which are then used to train the diffusion-based adapter and Q-value modules (right).
Figure 3: Geometry-consistent 3DGS-based simulation enables high-fidelity counterfactual sample generation.
Architecture and Training
The policy adapter comprises a latent 1D U-Net denoiser, conditioned on visual encodings, agent dynamics history, and the base policy trajectory. Residual actions are modeled with a Gaussian noise schedule to ensure robustness against multimodal perturbations. Q-value networks—each trained with their own reward principle—share a ResNet-based visual encoder with frozen weights and separate trajectory encoders.
At training, beam search and reward-based candidate selection allow tractable exploration within augmented behavior spaces, and cross-principle cumulative reward estimation for Q-function supervision ensures that the learning signal aligns with long-term driving utility.
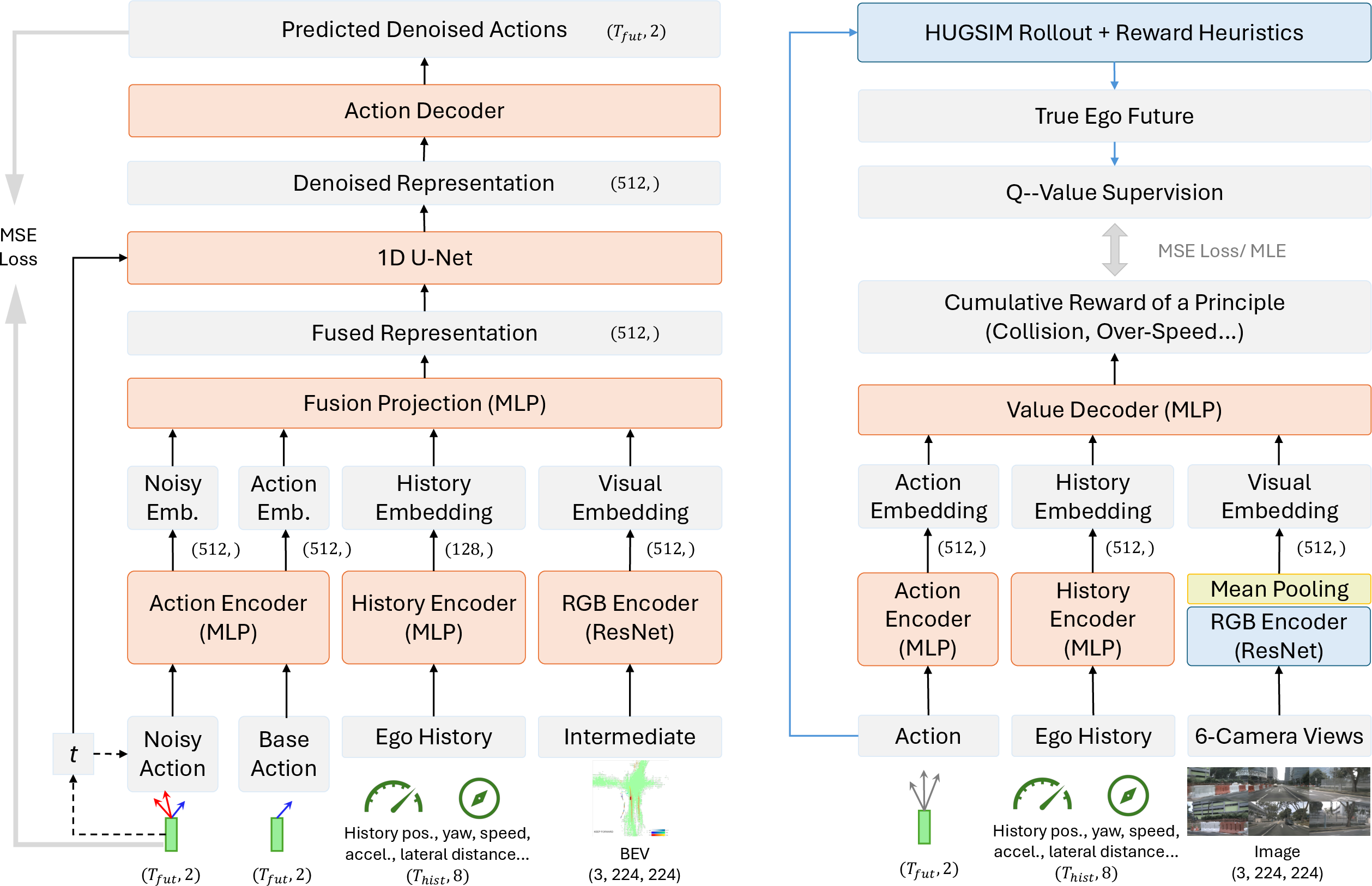
Figure 4: Architectural schematic of the policy adapter (left) and Q-value model (right), both integrating multi-sensor, historical, and action-stream context.
Experimental Evaluation
Experiments leverage the nuScenes dataset and the photorealistic HUGSIM closed-loop simulator. MPA is instantiated atop three baselines: UniAD, VAD, and Latent TransFuser, which are strong camera-based E2E policies. Evaluation is performed in-domain, out-of-domain (unseen city), and in adversarial safety-critical situations.
Key metrics include Route Completion (RC), Non-Collision (NC), Driveable Area Compliance (DAC), Time-To-Collision (TTC), Comfort (COM), and aggregate HDScore.
Numerical results:
Ablation studies on the adapter (removal results in a 20% drop in route completion) and reward guidance principles (e.g., omitting collision-avoidance Q induces premature terminations) establish the necessity and orthogonality of each MPA module.
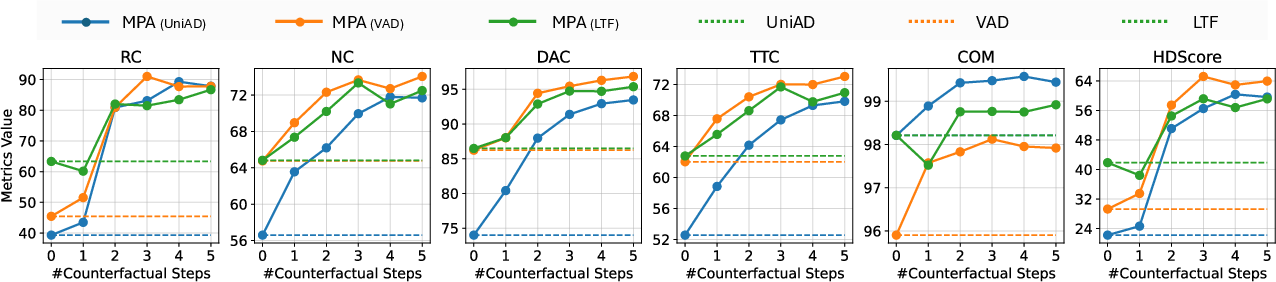
Figure 6: Longer counterfactual rollout horizons in dataset generation yield clear improvements in all core closed-loop metrics, confirming the value of extended supervision for Q-model learning.
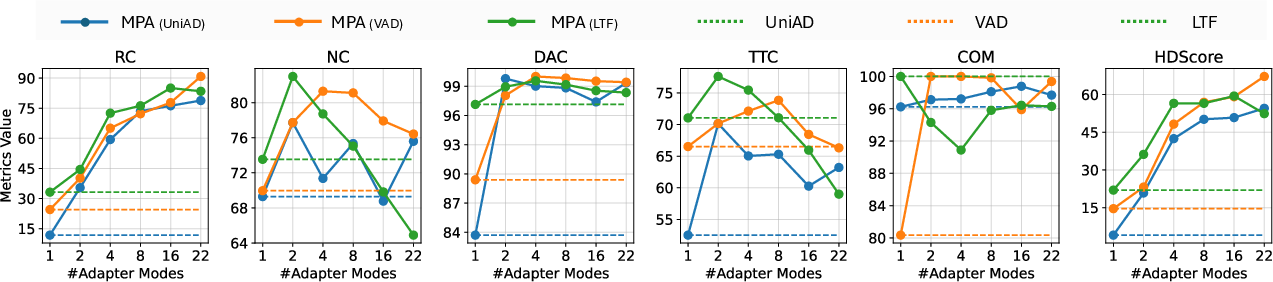
Figure 7: Increasing the mode capacity in the adapter architecture raises performance metrics—underscoring the benefit of enhanced multi-modality in correction policies.
Implications and Theoretical Insights
MPA establishes a scalable, modular framework for reward-aligned closed-loop policy refinement on top of any vision-based E2E agent, requiring no online RL finetuning (as in RAD) and integrating learned value models at inference. The use of geometry-consistent, high-fidelity counterfactual rollouts and principled multi-Q-guidance directly aligns test-time decisions with practical driving utility and safety objectives—bridging the fundamental supervised-to-RL deployment gap.
The architecture’s modularity supports rapid extension to novel urban domains, safety constraints, and reward/constraint design variations, with robust generalizability demonstrated empirically.
Limitations and Future Directions
MPA currently assumes (i) the rollouts remain sufficiently near-manifold for 3DGS fidelity, and (ii) explicit decoupling between policy and value network optimization. As new large foundation models and richer simulators become available, integrating foundation model reasoning and RL-based online policy improvement atop MPA’s architecture are promising research directions. Deployment to more severe real-world distribution shifts and in-the-loop human interaction scenarios constitute next steps.
Conclusion
The MPA framework delivers a principled solution to chronic closed-loop failure modes in E2E autonomous driving. By orchestrating high-fidelity counterfactual augmentation, multi-modal residual adaptation, and test-time Q-guided decision selection, MPA advances the robustness, safety, and generalizability of E2E agents in challenging urban contexts. Its modularity and plug-in nature position it as a foundation for future closed-loop policy adaptation efforts.
