- The paper introduces ARC-AGI-2, a refined benchmark that overcomes ARC-AGI-1 limitations by increasing task complexity and reducing brute-force approaches.
- It employs rigorous human calibration and controlled evaluations to establish reliable performance baselines, ensuring tasks mirror authentic human reasoning.
- Results reveal significant gaps between current AI systems and human performance, guiding the advancement of compositional generalization in AI models.
ARC-AGI-2: A New Challenge for AI Reasoning Systems
ARC-AGI-2 represents an evolution of the Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI), a benchmark introduced in 2019 by Fran\c{c}ois Chollet. It seeks to assess the fluid intelligence of AI systems through abstract reasoning tasks, aiming to overcome the limitations identified in its predecessor, ARC-AGI-1. This essay examines the substantial changes, rigorous evaluation processes, and anticipated contributions to the AI community brought by ARC-AGI-2.
Historical Context and Motivation
The original ARC-AGI focused on general reasoning skills, independent of extensive prior knowledge. Unlike traditional AI benchmarks, it evaluated fluid intelligence through unique tasks solvable without domain-specific information or memorization. Despite its innovative approach, empirical evidence showed that ARC-AGI-1 had limitations including susceptibility to brute-force strategies, a lack of consistent human performance baselines, and saturation below human-level intelligence. These issues necessitated the development of a more sophisticated benchmark, ARC-AGI-2.
Key Modifications and Features
ARC-AGI-2 maintains the fundamental principles of its predecessor but incorporates refinements aimed at enhancing task complexity and ensuring robust evaluation.
Expanded Task Difficulty and Complexity: New tasks are deliberately designed to minimize susceptibility to brute-force techniques while demanding deliberate thinking from human test-takers. The benchmark includes more unique tasks that enhance complexity through larger grids, increased object counts, and multi-concept interactions.

Figure 1: ARC-AGI-2 task id: e3721c99.
Human Calibration and Consistent Evaluation: Comprehensive human testing under controlled conditions provides a reliable baseline against which AI systems can be compared. Participants from diverse backgrounds confirm the general accessibility of tasks, establishing a meaningful human performance standard.
Testing and Validation Process: Tasks are subjected to rigorous human trials, ensuring at least two participants solve each within a few attempts. This results in curated subsets for public, semi-private, and private evaluation, each calibrated for consistent human-facing difficulty.
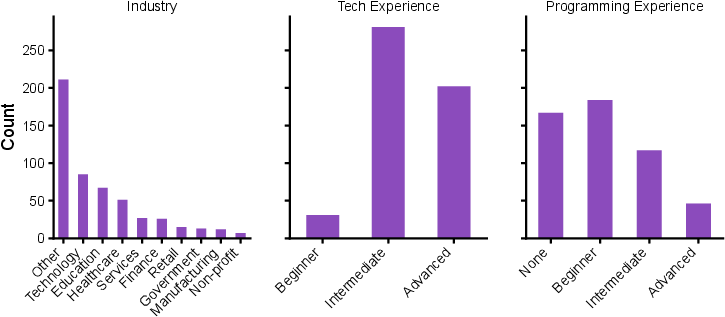
Figure 2: Study participants by self-reported industry and experience.
ARC-AGI-2 is designed to offer finer-grained signals that differentiate AI systems based on genuine reasoning abilities. It evaluates models using specific metrics and conditions that mimic the challenges humans face, emphasizing adaptability and problem-solving skills.
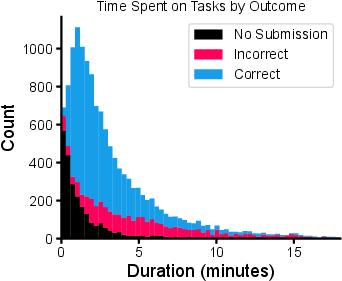
Figure 3: Outcome and time spent on all task test pair attempts across all participants.
Current State-of-the-Art Performance: Testing baseline models across ARC-AGI-2 reveals notable gaps in AI performance compared to human baselines. Scores indicate that the benchmark effectively challenges existing systems, pushing the frontiers of AI research.
Key Challenges in ARC-AGI-2
The benchmark introduces scenarios that require complex compositional reasoning, context-driven decision-making, and symbol definition within tasks. Each increases the cognitive load, driving innovation in model design and adaptation strategies.
Compositional Generalization: Combining multiple transformation rules within a single task challenges AI systems to adapt by integrating higher-order cognitive processes.

Figure 4: Number of human participants that correctly solved ARC-AGI-2 task test pair subsets. Note that Public Eval, Semi-Private Eval and Private Eval filtered out tasks which less than 2 people solved.
Implications and Future Directions
ARC-AGI-2 serves as a robust tool for evaluating progress towards AGI. It fosters an environment for developing adaptive AI systems capable of human-like reasoning and intelligent task execution. Through challenges that require dynamic adaptation, ARC-AGI-2 paves the way for breakthroughs in understanding and enhancing general intelligence in machines.
Conclusion
ARC-AGI-2 is a pivotal development in the continuous pursuit of advancements in AI reasoning systems, aiming to extend the benchmark's utility. By addressing known limitations and encouraging novel approaches to compositional generalization, it offers a refined framework for measuring AI progress towards more generalized capabilities.