- The paper introduces the ARCTraj dataset that captures temporally ordered human reasoning trajectories and object manipulations in abstract tasks.
- The paper presents a novel object-centric methodology with MDP transformation and action abstraction to enhance reinforcement learning and sequence modeling.
- The paper reveals that structured human reasoning, through observable selection biases and convergent strategies, improves policy stability and model performance.
ARCTraj: A Dataset and Benchmark of Human Reasoning Trajectories for Abstract Problem Solving
Introduction
ARCTraj addresses a long-standing deficiency in research on the Abstraction and Reasoning Corpus (ARC): the lack of temporally-resolved, object-centric human reasoning data. While ARC has catalyzed work on systematizing abstract reasoning, prior efforts have largely depended on static input-output supervision, which fails to elucidate intermediates of human-like reasoning. ARCTraj systematically records temporally-ordered sequences of object-level manipulations as humans solve ARC-AGI-1 training tasks, thus enabling explicit modeling of intermediate cognitive processes.
The dataset comprises approximately 10,000 human trajectories over 400 ARC-AGI-1 tasks, each annotated with metadata (user, task, timestamps, and success labels). These trajectories reflect symbolic reasoning steps such as spatial selection, object manipulation, and compositional strategy execution—providing structured supervision channels absent from prior data. ARCTraj includes a methodological framework for downstream integration: action abstraction, MDP formalism, and preprocessing for reinforcement learning (RL), sequence modeling, and generative modeling.
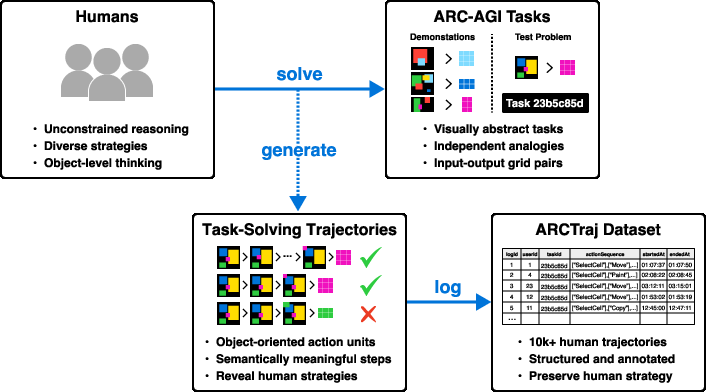
Figure 1: Overview of the ARCTraj data collection process in which user interactions with the O2ARC platform are captured as temporally-ordered, semantically-rich object-level reasoning trajectories.
Dataset Structure and Object-centric Encoding
ARCTraj logs each problem-solving attempt as a temporally-ordered sequence of categorically-labeled actions. Each action triplet ⟨category, object, operation⟩ is tied to a grid state and timestamp, aligning each reasoning step to a symbolic context (e.g., Selection, Coloring, Object-Oriented Move/Rotate/Flip). User-driven perceptual grouping ensures semantic consistency in object delineation, outperforming low-level pixel editing logs.
The dataset supports full replay, state comparison, and granular extraction for learning scenarios demanding Markovian state-action or symbolic sequence inputs.
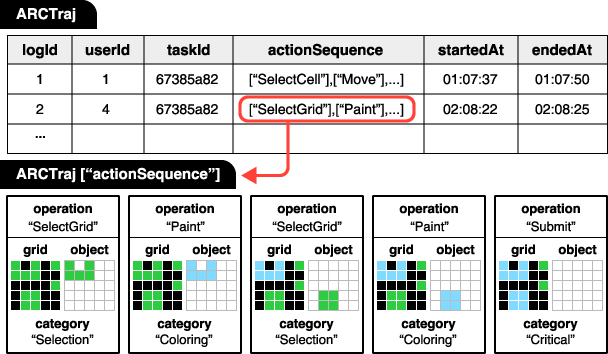
Figure 2: An example ARCTraj trajectory, where each state–action entry logs category, operation, grid, and object details, facilitating structured state-space analysis.
Comparative Analysis with Prior Human ARC Datasets
Relative to H-ARC and ARC-Interactive-History, ARCTraj achieves stronger abstraction by encoding object-centric operations and explicitly segmenting selection actions. While H-ARC records merged pixel actions, ARCTraj’s structure reflects strategy formation, intention, and composition at the object level (37.7% object-related actions when selection is excluded versus H-ARC’s 0.9%).
Notably, ARCTraj demonstrates greater cross-trajectory convergence (43.7% shared grids vs. 11.4% in H-ARC)—implying that human solvers, when provided with semantically meaningful actions, converge on similar intermediate representations. Despite fewer participants, ARCTraj achieves deeper and denser trajectory coverage per task.
ARCTraj provides a basis for analyzing human attention biases, color source attribution, and shared intentions during abstract problem solving:
- Selection Biases: Human attention clusters on local, compact, regular regions (1×1 to 3×3), with a pronounced preference for spatial and perceptual salience.
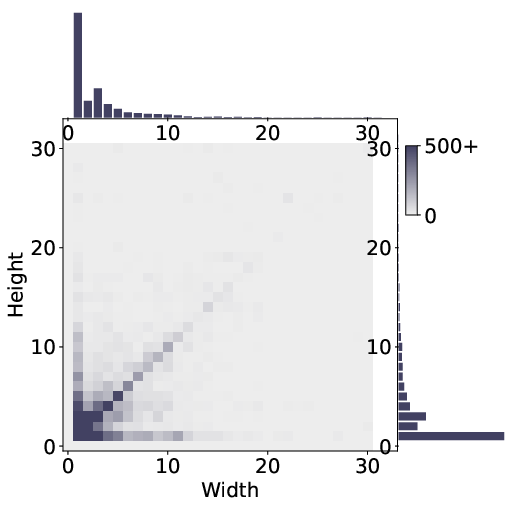
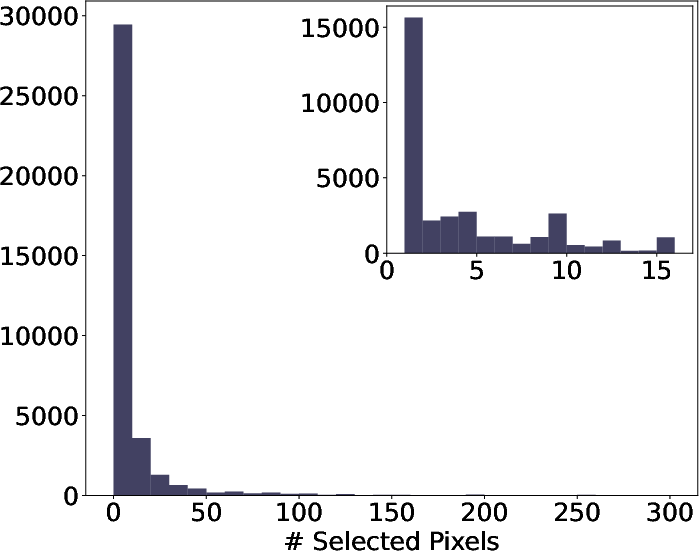
Figure 3: Distributional analyses reveal that humans preferentially select square- and bar-like regions of limited extent, emphasizing the dominance of local, salient reasoning foci.
Unified Reasoning Pipeline for Downstream Learning
ARCTraj enables a generalized pipeline: task-to-MDP conversion, symbolic action abstraction, and downstream mapping for RL (e.g., ARCLE), generative models (e.g., LDCQ, GFlowNet), and sequence learners (e.g., Decision Transformers). Object-centric structural abstraction facilitates Markovian modeling, while intention and selection cues can be injected as auxiliary knowledge, driving explainable and sample-efficient learning models.
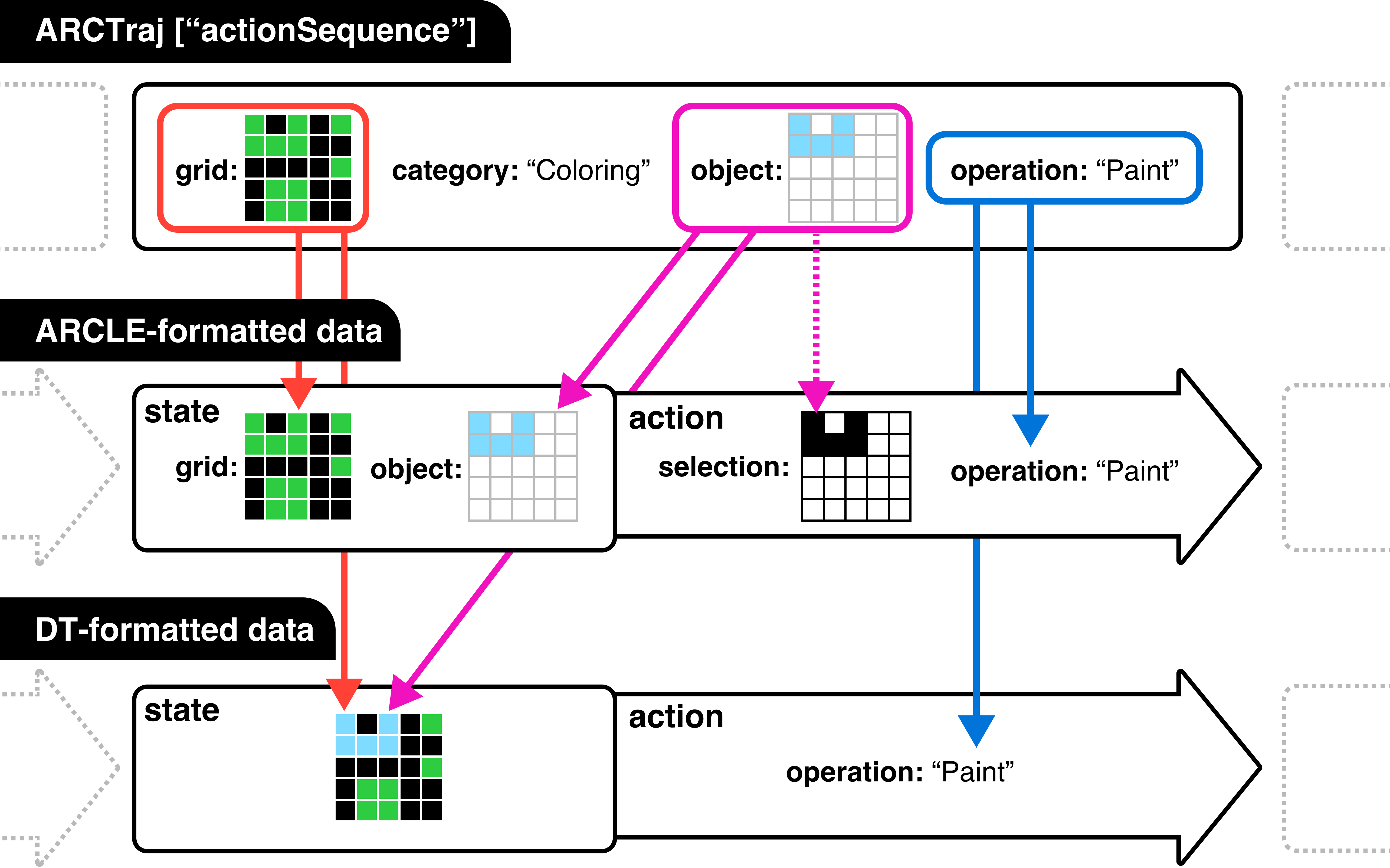
Figure 5: Demonstrates how ARCTraj preprocessing generates state-action sequences compatible with various downstream learning architectures.
Empirical Implications for ARC Solvers and General AI
ARCTraj enhances RL sample efficiency and policy stability via imitation learning and reward shaping, as evidenced by PPO and World Model approaches leveraging the data. Latent diffusion models (LDCQ) utilize the compactness and semantic structuring of ARCTraj-encoded actions, enabling robust trajectory generation. GFlowNets benefit from ARCTraj by balancing exploitation of high-quality trajectories and diverse exploration of the solution space. For Decision Transformers, intention and object annotations facilitate higher-level policy learning, improving generalization and trajectory coherence.
Strong empirical results are observed: Decision Transformers with intention cues obtain 6–8 percentage point accuracy gains, and GFlowNet models trained with selection priors yield increased diversity and coverage of structurally valid solutions.
Theoretical and Practical Directions
ARCTraj provides actionable priors for extrapolating systematic cognitive regularities into AI system design, such as attention scheduling, compositional abstraction, and intention alignment. Explicit modeling of selection and transformation regularities bridges System 2-inspired AI with human-inductive bias, addressing implementation gaps in program synthesis and abstract visual reasoning. The dataset’s object-centric MDP framework is extensible to other high-level reasoning domains (robotics, symbolic manipulation, and transformation learning).
Future research can formalize shared reasoning grammars, annotate intention clusters for few-shot analogical induction, and extend color/element lineage tracking. Predictive intention modeling and phase-based attention dynamics offer new avenues for adaptive curriculum design and collaborative human–AI agents.
Conclusion
ARCTraj sets a new standard for dynamic, interpretable datasets in symbolic reasoning and abstract problem solving. Its structured, temporally-ordered object-level action logs provide direct, actionable supervision for cognitive AI models and enable empirical investigation of the mechanistic basis of human generalization on ARC-like tasks (2511.11079).
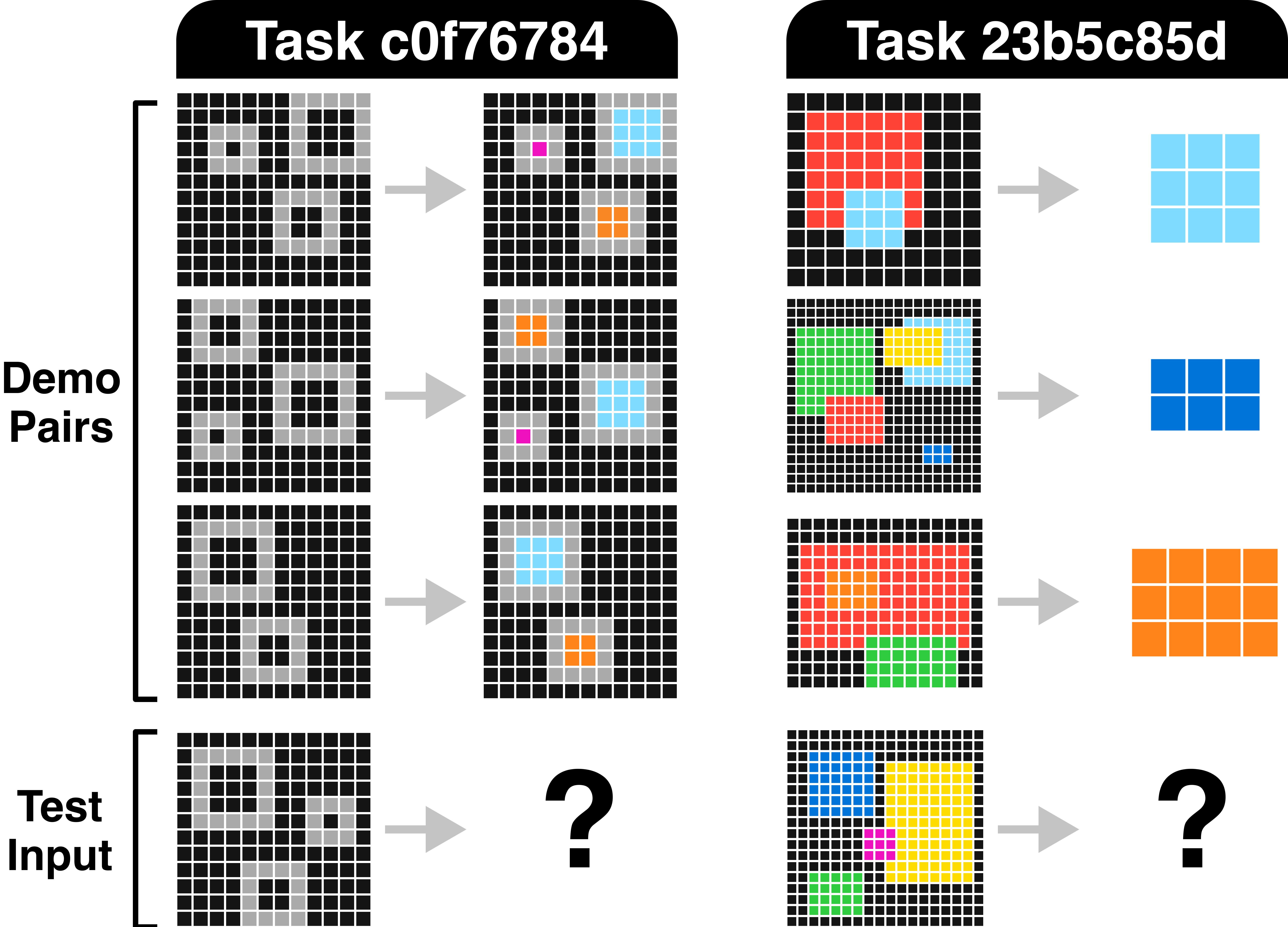
Figure 6: Two representative ARC tasks: (left) size-based hollow square filling, and (right) object selection and cropping—tasks that exemplify the compositional reasoning ARCTraj trajectories enable.
The dataset is foundational for human-aligned abstract reasoning research, supporting both behavioral analysis and next-generation solver development. Its methodological pipeline—MDP transformation, action abstraction, and trajectory-based supervision—sets a precedent for data collection and modeling across high-level cognitive domains.