- The paper presents Thinkless, a novel hybrid approach that dynamically selects between detailed and concise reasoning using control tokens.
- It introduces the Decoupled Group Relative Policy Optimization (DeGRPO) algorithm to balance mode selection and response accuracy.
- Experimental results show up to a 90% reduction in lengthy reasoning while maintaining or enhancing accuracy on benchmarks.
Thinkless: LLM Learns When to Think
Introduction
The paper addresses the challenge of optimizing the reasoning efficiency of LLMs by proposing a hybrid model, Thinkless, which dynamically determines whether to pursue detailed or concise reasoning based on task complexity and model capability. This approach aims to mitigate computational inefficiencies of reasoning LLMs in instances where complex reasoning is unnecessary.
Methodology
Hybrid Reasoning Framework
Thinkless utilizes special control tokens, > and <short>, to guide the model in selecting either long-form or short-form reasoning. The core of this framework is the Decoupled Group Relative Policy Optimization (DeGRPO) algorithm designed to balance the learning objectives related to mode selection and response accuracy.
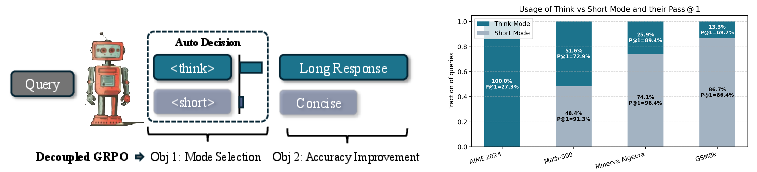
Figure 1: Thinkless learns a hybrid LLM capable of adaptively selecting between thinking and non-thinking inference modes, directed by two special tokens, <think> and <short>. At the core of our method is a Decoupled Group Relative Policy Optimization, which decomposes and balances the mode selection on the control token and accuracy improvement on the response tokens.
Training Process
The training involves two phases: an initial supervised distillation phase, where the model learns to produce both reasoning styles, followed by a reinforcement learning phase using DeGRPO. In the supervised stage, the model is primed using paired data that reflects both reasoning modes, aligning its outputs with control tokens.
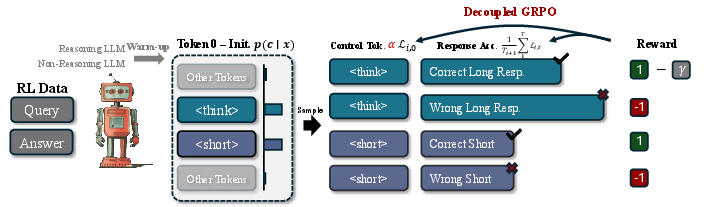
Figure 2: ThinkLess trains a hybrid model that adaptively selects reasoning modes based on task complexity and model capacity. The process begins with distillation, enabling the model to follow control tokens (<think> or <short>) for guided reasoning. This is followed by reinforcement learning using Decoupled GRPO, which separates training into two objectives: optimizing the control token for effective mode selection and refining the response to improve answer accuracy.
Decoupled GRPO Implementation
DeGRPO is essential for preventing mode collapse, a phenomenon where a model may excessively favor one reasoning style. By independently normalizing control and response tokens, DeGRPO ensures balanced updates, mitigating biases introduced by token length discrepancies in training data.
Experimental Results
Empirical evaluations on various benchmarks, including MATH-500 and GSM-8K, demonstrate Thinkless's ability to significantly reduce the incidence of lengthy reasoning processes by up to 90%, while maintaining or even improving model accuracy.

Figure 3: Distribution of the model’s probability of emitting <think> on MATH-500. The samples with the highest, medium, and lowest probabilities are highlighted. The example with almost 0 thinking score mainly involves straightforward computation, and the query with 1.0 probability relies more on understanding and logical reasoning.
Implications and Future Directions
The proposed framework offers a pathway to more efficient inference in reasoning models, reducing computational costs and improving user experience in scenarios where quick answers are satisfactory. Future research might explore scalability to broader domains and leverage additional strategies like model merging to further enhance performance.
Conclusion
Thinkless presents an innovative approach to hybrid reasoning in LLMs, offering substantial efficiency gains by learning when to deploy complex reasoning strategically. The methodological advancements provided by DeGRPO significantly enhance the decision-making capability within LLMs, proving effective across a variety of testing scenarios. Despite existing challenges, Thinkless's framework provides a robust foundation for future exploration in adaptive reasoning.