- The paper introduces ServerlessLoRA, a novel approach to minimize latency and cost in LoRA-based LLM inference.
- It employs pre-loading schedulers, dynamic batching, and GPU memory offloading to optimize resource management in serverless deployments.
- Performance evaluations show significant reductions in TTFT, monetary costs, and resource contention, ensuring scalable and efficient serverless inference.
Introduction
The paper "ServerlessLoRA: Minimizing Latency and Cost in Serverless Inference for LoRA-Based LLMs" introduces a novel approach to address inefficiencies and scalability issues in serverless inference systems for Low-Rank Adaptation (LoRA)-based LLMs. The authors identify three key problems: massive parameter redundancy, costly artifact loading latency, and resource contention during inference. ServerlessLoRA is proposed as a solution to overcome these challenges by sharing backbone models, pre-loading artifacts, and optimizing resource management in serverless deployments.
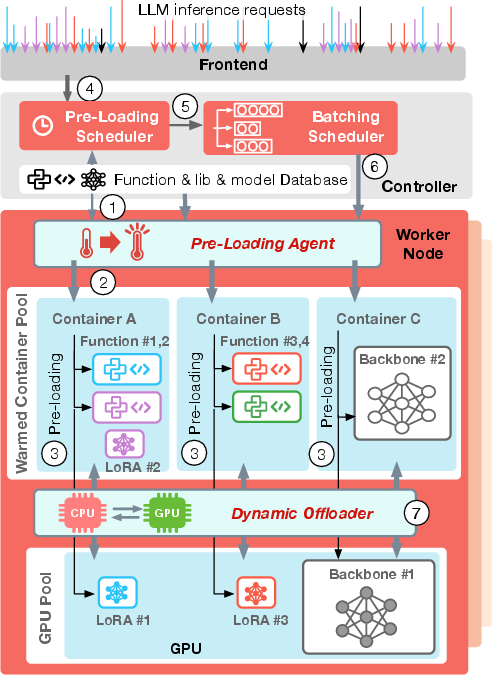
Figure 1: System overview.
Serverless LLM Inference
Serverless computing is highlighted for its advantages in LLM inference due to its ability to offer pay-as-you-go pricing, fine-grained resource usage, and rapid scalability. Unlike serverful architectures, which are less agile and resource-efficient, serverless platforms can dynamically allocate resources based on demand, saving costs and improving response times.
However, serving LoRA-based LLMs with serverless architectures poses unique challenges due to backbone model redundancy, leading to increased TTFT and costs. The sharing mechanism and handling of artifacts are crucial for serverless architectures aiming to manage the specific demands of LoRA models efficiently.
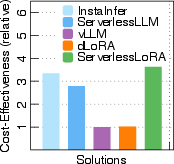
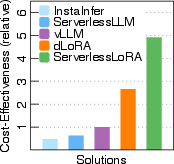
Figure 2: Cost-effectiveness of serverless and serverful solutions for one Llama2-7B base LLM.
System Architecture
ServerlessLoRA introduces several components to facilitate efficient LoRA inference. Key components include:
- Pre-Loading Scheduler: Determines optimal pre-loading of artifacts in GPU and container memory, leveraging idle resources, and maximizing performance while minimizing overhead.
- Batching Scheduler: Aggregates requests dynamically to optimize batch sizes, balancing between latency and throughput while managing resource contention effectively.
- Pre-Loading Agent: Implements pre-loading decisions and manages instances on worker nodes, ensuring efficient artifact handling and reducing cold-start latency.
- Dynamic Offloader: Manages GPU memory intelligently during bursts, offloading non-essential artifacts to maximize available resources for concurrent requests.
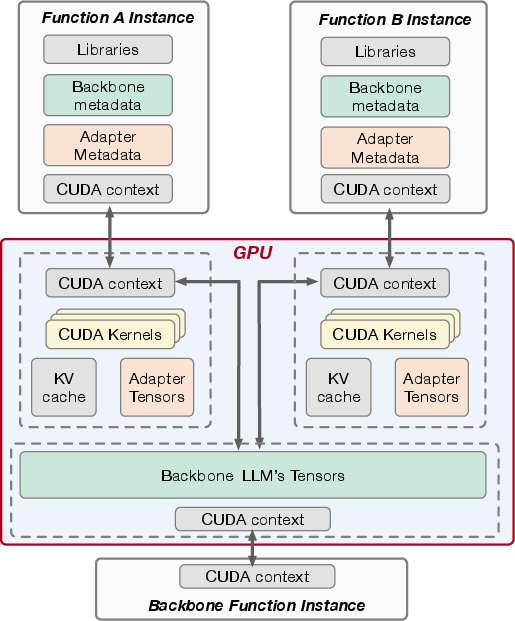
Figure 3: Backbone LLM sharing among function instances.
The evaluation metrics focus on TTFT, TPOT, monetary cost, throughput, and SLO violation rates. ServerlessLoRA is shown to significantly reduce TTFT and monetary costs compared to serverless and serverful baselines. The system's backbone sharing and pre-loading strategies ensure that resources are used efficiently, enabling substantial cost and latency reductions (Figure 4).
Moreover, ServerlessLoRA retains scalability by dynamically adjusting to workload demands without compromising responsiveness. It maximizes throughput without incurring high SLO violation rates, demonstrating robustness under varied computational loads.
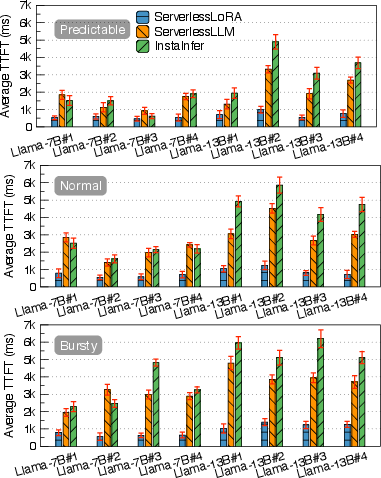
Figure 5: Average TTFT of the workloads at Predictable'',Normal'', and ``Bursty'' arrival patterns.
Implementation Details
ServerlessLoRA is implemented using Python and CUDA to facilitate backbone sharing via CUDA Inter-Process Communication (IPC). The serverless architecture adheres to isolation principles while allowing multiple function instances to utilize shared backbone memory efficiently. Pre-loading mechanisms and adaptive batching ensure that functions are ready to serve requests with minimal delay.
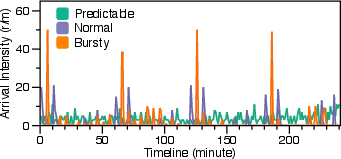
Figure 6: Trace example of Predictable'' (CoV leq1),Normal'' (1< CoV leq4), and ``Bursty'' request arrival pattern.
Conclusion
ServerlessLoRA represents a strategic evolution in serverless architecture for LoRA-based LLMs, addressing key inefficiencies and optimizing deployment costs effectively. By leveraging shared model resources and intelligently pre-loading artifacts, ServerlessLoRA enhances both latency and economic metrics. Its design significantly improves the feasibility of deploying specialized LLMs on serverless platforms, potentially transforming practical implementations across varied AI applications.