Published 21 May 2025 in cs.LG, cs.AI, cs.CL, and stat.ML | (2505.15201v1)
Abstract: Reinforcement Learning (RL) algorithms sample multiple n>1 solution attempts for each problem and reward them independently. This optimizes for pass@1 performance and prioritizes the strength of isolated samples at the expense of the diversity and collective utility of sets of samples. This under-utilizes the sampling capacity, limiting exploration and eventual improvement on harder examples. As a fix, we propose Pass-at-k Policy Optimization (PKPO), a transformation on the final rewards which leads to direct optimization of pass@k performance, thus optimizing for sets of samples that maximize reward when considered jointly. Our contribution is to derive novel low variance unbiased estimators for pass@k and its gradient, in both the binary and continuous reward settings. We show optimization with our estimators reduces to standard RL with rewards that have been jointly transformed by a stable and efficient transformation function. While previous efforts are restricted to k=n, ours is the first to enable robust optimization of pass@k for any arbitrary k <= n. Moreover, instead of trading off pass@1 performance for pass@k gains, our method allows annealing k during training, optimizing both metrics and often achieving strong pass@1 numbers alongside significant pass@k gains. We validate our reward transformations on toy experiments, which reveal the variance reducing properties of our formulations. We also include real-world examples using the open-source LLM, GEMMA-2. We find that our transformation effectively optimizes for the target k. Furthermore, higher k values enable solving more and harder problems, while annealing k boosts both the pass@1 and pass@k . Crucially, for challenging task sets where conventional pass@1 optimization stalls, our pass@k approach unblocks learning, likely due to better exploration by prioritizing joint utility over the utility of individual samples.
"Pass@K Policy Optimization: Solving Harder Reinforcement Learning Problems" introduces Pass-at-k Policy Optimization (PKPO), which focuses on optimizing reinforcement learning in scenarios where multiple solution attempts are made. Traditional RL approaches assess isolated samples individually, often leading to under-utilization of sampling capacity and limited exploration. PKPO uses transformations on final rewards to optimize sets of samples jointly, aiming for a large maximum reward across sample sets.
PKPO introduces novel low variance unbiased estimators for the metric and its gradient in both binary and continuous reward settings. The method facilitates robust optimization beyond the special case k=n, enabling smoother transitions across varying sample sizes during training. This flexibility optimizes both individual performance and cumulative metrics.
Binary Rewards
In binary reward settings, the PKPO method measures the probability that at least one of k samples is successful:
=P[i=1⋁k[f(xi)=1]]=E[1−i=1∏k(1−f(xi))].
An unbiased estimator for this metric, ρ(n,c,k), relies on computing the probability that subsets of sample size k include a correct sample. This approach retains unbiasedness while providing a robust gradient estimation via:
∇=i=1∑nri∇θlogp(xi∣θ),
where ri rewards correct samples and encourages exploration even for incorrect ones.
Continuous Rewards
Transitioning to continuous rewards, PKPO generalizes to measure the expected maximum among sample rewards:
≡E[max({g(xi)}i=1k)].
This involves computing weights μi representing each sample subset's impact on the expected maximum reward. The transformation uses sorted rewards to efficiently compute unbiased estimators for both reward expectations and gradients.
Variance Reduction
To address estimator variance, PKPO incorporates variance reduction techniques using leave-one-out baselining, which calculates reduced contribution for subsets not including specific elements. This retains unbiasedness while dampening estimator variance further.
For larger sample sets where traditional baselining fails, the "leave one out minus one" approach is applied, reducing variance without introducing bias. This method’s computational efficiency is corroborated by experimental results demonstrating significant variance reduction compared to alternative estimators.
Experiments
One-Dimensional Toy Example
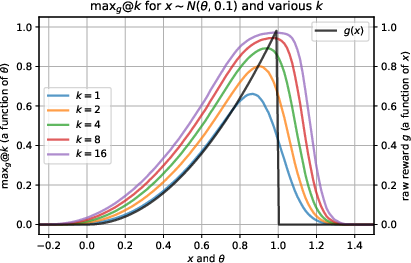
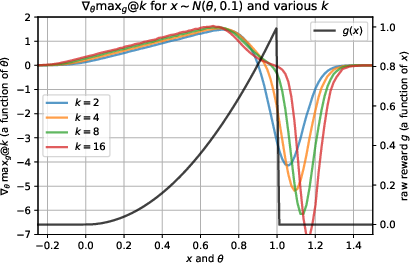
Experiments on basic toy scenarios illustrate the impact of varying k on reward transformations. Larger k, promoting risk tolerance, shifts optimal policy, enhancing exploration by allowing samples closer to the reward threshold.
Figure 1: Effect k has on optimal policy for a one-dimensional toy problem.
Reinforcement Learning on Gemma-2
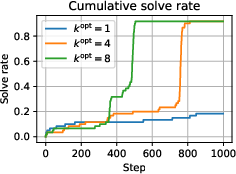
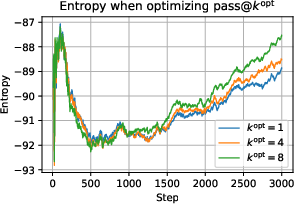
Testing PKPO on Gemma-2 within real-world scenarios confirms its efficacy. Increasing k correlates with improved cumulative solve rates and enhanced exploration.
PKPO's dynamic k adjustment showcases adaptability in training regimes, significantly unblocking learning across challenging task sets—a feat not as effectively accomplished by traditional methods.
Conclusions and Outlook
PKPO provides a nuanced RL approach leveraging reward transformations to optimize joint sample utility. By enabling more effective exploration, it unblocks learning where conventional methods plateau. The flexibility of varying k during training consolidates its advantage, particularly in complex problem sets. Future explorations may extend PKPO to other inference-time algorithms and refine baseline strategies, amplifying its applicability within AI research advancements.