- The paper introduces MCP-RADAR, a new benchmark evaluating LLMs' tool use via 507 tasks spanning six domains.
- It applies multi-dimensional metrics such as answer correctness, operational accuracy, and resource efficiency to mirror real-world scenarios.
- The study identifies common tool-use and reasoning errors, offering insights to improve both LLM architectures and tool integration.
Introduction
The paradigm shift from passive text generation to proactive reasoning within LLMs has introduced new challenges and opportunities in AI capabilities. This shift is underscored by the Model Context Protocol (MCP), which standardizes interactions between LLMs and external tools, facilitating more dynamic usage and integration. Despite MCP's widespread adoption, existing benchmarks inadequately measure LLMs' proficiency in tool use. The paper "MCP-RADAR: A Multi-Dimensional Benchmark for Evaluating Tool Use Capabilities in LLMs" (2505.16700) introduces a comprehensive benchmark, MCP-RADAR, targeting this gap by evaluating LLM performance in tool utilization across various domains.
Methodology
The MCP-RADAR benchmark assesses tool use capabilities by introducing a dataset of 507 tasks across six domains: mathematical reasoning, web search, email, calendar, file management, and terminal operations. The evaluation framework moves beyond traditional binary success metrics by incorporating quantitative measures across multiple dimensions: answer correctness, operational accuracy, and resource efficiency. This approach allows for an assessment that more closely emulates real-world scenarios using authentic MCP tools and high-fidelity simulations.
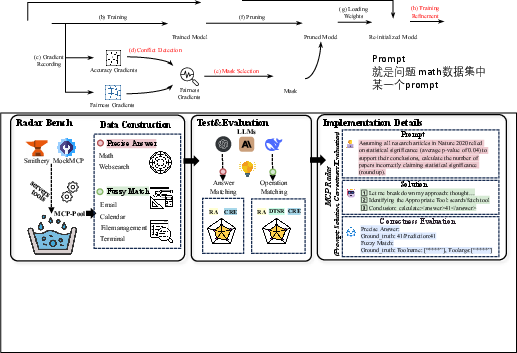
Figure 1: Overview of MCP-RADAR's methodology and domains.
Data Generation
The dataset construction for MCP-RADAR involves two distinct task categories: Precise Answer and Fuzzy Match. Precise Answer tasks require a definitive ground-truth value, while Fuzzy Match tasks involve executing a correct sequence of operations. For Precise Answer tasks, data was sourced and filtered from existing academic datasets to ensure robustness and relevance. Fuzzy Match tasks involved programmatically generating interaction scenarios using a controlled tool environment, ensuring realistic tool interaction schemas.

Figure 2: The process of data generation for MCP-RADAR tasks.
Experimental Setup
Ten leading LLMs were evaluated using the MCP-RADAR benchmark, leveraging the OpenRouter API for standardized interfacing. Models were provided with detailed system prompts and tasked with solving problems using a suite of MCP tools within a maximum of 10 dialog rounds. The focus was on assessing both the accuracy of tool use and computational efficiency, with a detailed comparison of performance metrics across models.
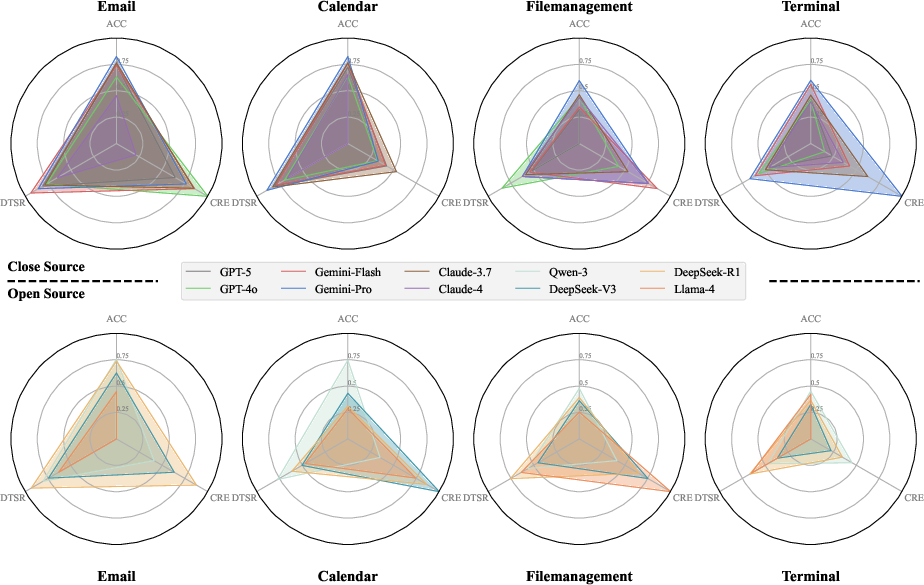
Figure 3: Model performance comparison across tasks; longer edges indicate superior performance.
Results
The evaluation revealed a recurring capability gap where models frequently chose semantically plausible but functionally incorrect tools, indicating a superficial understanding of task requirements. Closed-source models generally exhibited superior performance, especially in mathematical reasoning tasks, although open-source models showed competitive accuracy at the cost of higher computational resource consumption. The holistic radar chart analysis highlights trade-offs between accuracy and efficiency, identifying Gemini-2.5-Pro as a standout performer among closed-source models, while Qwen demonstrated balanced performance among open-source models.
Error Analysis
The study identifies three primary error categories: Tool-Use Errors, Reasoning Errors, and Information Synthesis Errors. Tool-Use Errors involve direct invocation failures, while Reasoning Errors reflect high-level planning lapses. Information Synthesis Errors pertain to processing and handling tool outputs effectively. These failures indicate core challenges in current LLM architectures, suggesting directions for future enhancements.
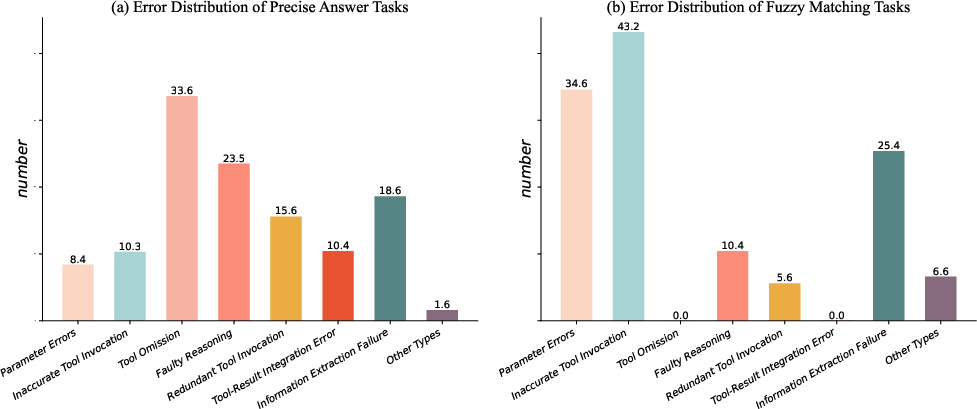
Figure 4: Error distribution by task type, illustrating common failure modes.
Implications and Future Work
This research provides actionable insights for improving LLM development and MCP tool design. Enhancements in proactive tool invocation and decompositional reasoning are critical for advancing LLM capabilities. Tool developers are encouraged to optimize tool descriptions and design atomic tools to facilitate improved model performance. Further exploration into addressing error modes and enhancing reasoning capacities in LLMs will be vital for their evolution within the MCP framework.
Conclusion
The MCP-RADAR benchmark represents a substantial advancement in evaluating LLMs' tool use capabilities, offering a robust framework applicable to the broader LLM ecosystem. The study establishes a standardized methodology that aids AI developers and researchers in assessing and evolving LLMs as dynamic reasoning agents. The continued refinement of MCP protocols and tools, alongside advancements in LLM architectures, will forge pathways for more sophisticated and reliable AI systems.