MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers
Abstract: The Model Context Protocol has emerged as a transformative standard for connecting LLMs to external data sources and tools, rapidly gaining adoption across major AI providers and development platforms. However, existing benchmarks are overly simplistic and fail to capture real application challenges such as long-horizon reasoning and large, unfamiliar tool spaces. To address this critical gap, we introduce MCP-Universe, the first comprehensive benchmark specifically designed to evaluate LLMs in realistic and hard tasks through interaction with real-world MCP servers. Our benchmark encompasses 6 core domains spanning 11 different MCP servers: Location Navigation, Repository Management, Financial Analysis, 3D Design, Browser Automation, and Web Searching. To ensure rigorous evaluation, we implement execution-based evaluators, including format evaluators for agent format compliance, static evaluators for time-invariant content matching, and dynamic evaluators that automatically retrieve real-time ground truth for temporally sensitive tasks. Through extensive evaluation of leading LLMs, we find that even SOTA models such as GPT-5 (43.72%), Grok-4 (33.33%) and Claude-4.0-Sonnet (29.44%) exhibit significant performance limitations. In addition, our benchmark poses a significant long-context challenge for LLM agents, as the number of input tokens increases rapidly with the number of interaction steps. Moreover, it introduces an unknown-tools challenge, as LLM agents often lack familiarity with the precise usage of the MCP servers. Notably, enterprise-level agents like Cursor cannot achieve better performance than standard ReAct frameworks. Beyond evaluation, we open-source our extensible evaluation framework with UI support, enabling researchers and practitioners to seamlessly integrate new agents and MCP servers while fostering innovation in the rapidly evolving MCP ecosystem.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
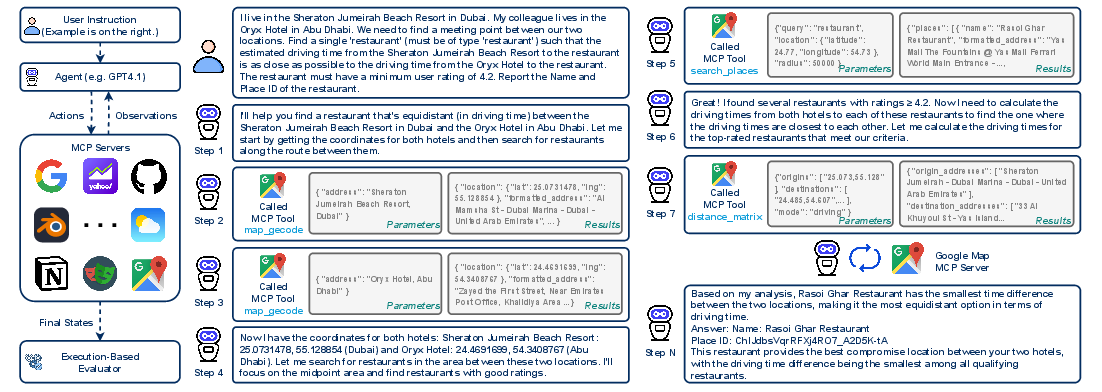
This paper introduces MCP‑Universe, a big “test suite” for checking how well AI assistants (LLMs, or LLMs) can use real tools in the real world. It focuses on MCP (Model Context Protocol), which is like a universal plug (“USB‑C for AI”) that lets AIs connect to many different apps and data sources. The goal is to see if today’s best AIs can plan, choose the right tools, and complete hard, realistic tasks—like finding the best driving route, reading live stock data, searching the web, managing code on GitHub, automating a web browser, or building 3D scenes.
What questions did the researchers ask?
The researchers asked simple but important questions:
- Can top AIs actually use real tools to finish real tasks, not just talk about them?
- How do AIs handle tasks that take many steps and produce very long “back-and-forth” histories?
- Can AIs figure out new tools they’ve never seen before?
- What’s a fair way to grade success when answers change over time (like flight prices or stock data)?
- Do fancy, enterprise agent systems do better than simple, popular agent setups?
How did they study it?
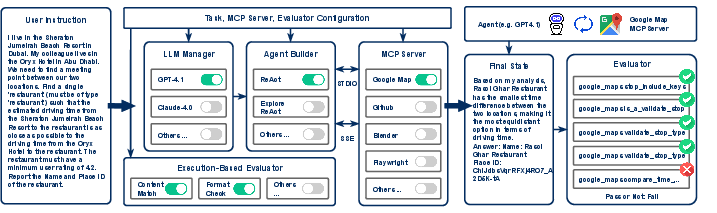
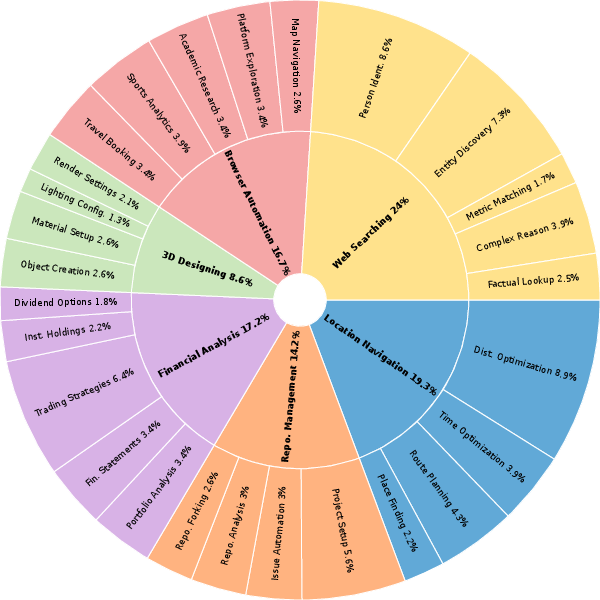
The team built a benchmark (a standardized test) with 231 tasks across 6 areas, connected to 11 real MCP servers—so the AI talks to actual services, not toy simulations. The six areas are:
- Location Navigation (Google Maps)
- Repository Management (GitHub)
- Financial Analysis (Yahoo Finance)
- 3D Design (Blender)
- Browser Automation (Playwright)
- Web Searching (Google Search + web content fetch)
They measured success using “execution‑based” checks—meaning the AI has to really do the thing, not just say it did. Because many tasks use live data, they didn’t ask another AI to judge answers (that can be biased or outdated). Instead, they built three types of automatic graders:
- Format evaluators: Did the AI follow the required output format?
- Static evaluators: Is the answer correct when the truth doesn’t change over time?
- Dynamic evaluators: Is the answer correct right now, based on live data (like today’s stock price)?
They tested many well‑known AIs using popular agent strategies like ReAct (think–act–observe loops), and also tried agent variations, such as:
- A summarizer to shorten very long tool outputs.
- An exploration phase where the AI practices using the tools before attempting the real task.
- Different agent frameworks (including enterprise ones like Cursor and the OpenAI Agent SDK).
What did they find?
The main results are clear and surprising:
- Even the best models struggled. The top score was GPT‑5 at about 44% success. Grok‑4 reached about 33%, and Claude‑4.0‑Sonnet about 29%. That means more than half the tasks failed even for the strongest AIs tested.
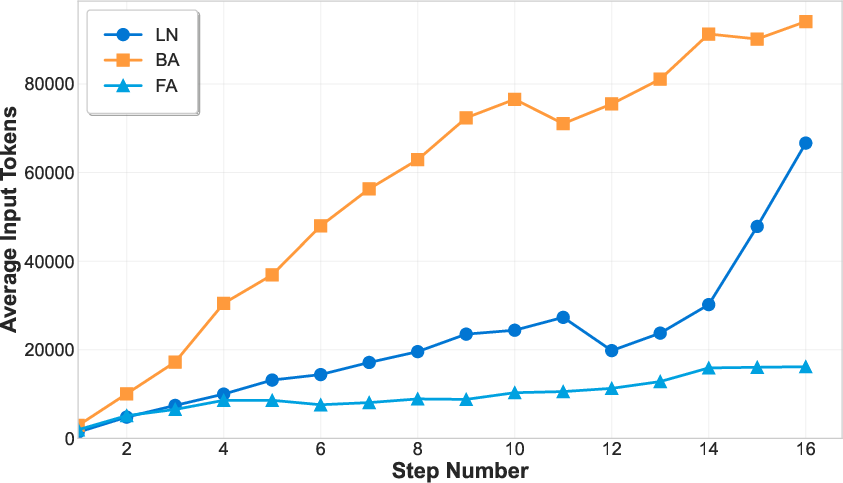
- Long tasks create “long context” problems. As the AI takes more steps and tools return big outputs (like full web pages or long data tables), the conversation gets so long that models lose track or run out of space.
- Unknown tools are hard. AIs often misuse tool inputs (for example, giving the same start and end date when pulling stock prices), which causes errors.
- Performance varies a lot by domain. For example, financial tasks were easier for some models, but location navigation and repository management were notably tough across the board.
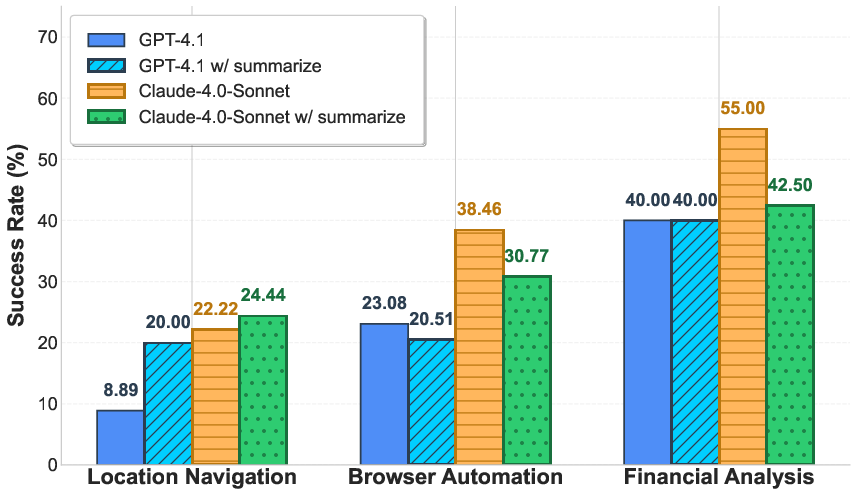
- Summarizing tool outputs helped sometimes (e.g., maps), but could also hurt (e.g., finance and browser tasks), because important details got lost.
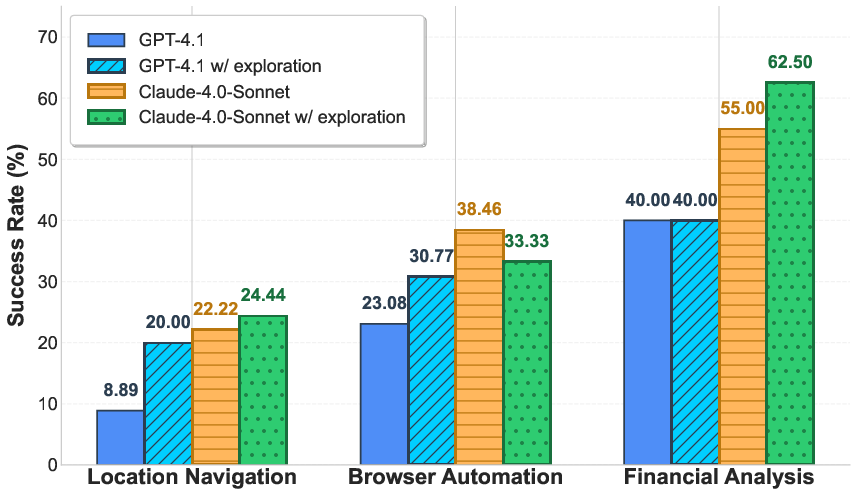
- Letting the AI explore tools first helped in some cases (like browser automation for some models), but not consistently. There’s no one trick that fixes everything.
- Adding extra, unrelated tools made things worse. When the AI sees a bigger “toolbox” full of distracting tools, it gets more confused and succeeds less often.
- Enterprise agents didn’t always win. For example, Cursor didn’t beat a standard ReAct setup overall with the same model. On the other hand, pairing OpenAI’s o3 model with the OpenAI Agent SDK worked better than o3 with plain ReAct—so matching the right model and agent framework matters.
Why this is important:
- It shows a big gap between what AIs can do in simple chat demos and what they can do in messy, real applications.
- It highlights what needs improvement: handling long contexts, learning tools reliably, and planning across many steps.
What does this mean going forward?
This benchmark gives researchers and developers a tough, realistic playground to improve AI agents. Because MCP‑Universe uses real tools, live data, and strict automatic grading, it helps:
- Design better agents that can handle long conversations, summarize without losing key information, and learn new tools quickly.
- Build reliable systems for businesses that need AIs to actually complete tasks, not just talk about them.
- Encourage the community to add new tools and tasks easily (the framework is open‑source and extensible).
In simple terms: if we want AI assistants that can truly “do things” in the real world—book trips, manage code, analyze markets, or automate web work—we need tests like MCP‑Universe. This paper shows where today’s AIs fall short and points the way to making them more capable, trustworthy helpers.
Practical Applications
Immediate Applications
Below are concrete applications that can be implemented now using the paper’s benchmark, framework, and insights.
- Benchmark-driven agent selection and procurement (Industry: software, finance, e-commerce, enterprise IT)
- What: Use MCP-Universe to compare LLMs and agent frameworks (e.g., ReAct vs. enterprise agents) on realistic tool-use tasks (GitHub, Google Maps, Yahoo Finance, Playwright, Google Search).
- Tools/products/workflows: “AgentFit” dashboards for vendor evaluation; RFP addenda requiring MCP-Universe scores per domain; red-team runs using dynamic evaluators to test time-sensitive performance.
- Assumptions/dependencies: Access to MCP servers and API keys; cost and rate limits; consistent evaluation seeds and timestamps.
- Pre-deployment regression and CI for agentic systems (Industry: software, DevOps/MLOps)
- What: Integrate MCP-Universe’s execution-based evaluators into CI/CD to catch regressions when LLM versions, prompts, or MCP server APIs change.
- Tools/products/workflows: “Benchmark-in-CI” plugin; nightly regression suites; failure triage via unified interaction logs; change budgets for tool-interface updates.
- Assumptions/dependencies: Stable staging sandboxes for GitHub/Playwright tasks; deterministic seeds for comparability; version-pin MCP server specs.
- Agent workflow hardening against unknown-tools errors (Industry: software tooling, platforms)
- What: Adopt the paper’s exploration phase before exploitation to reduce tool-interface misuse (e.g., date range constraints in Yahoo Finance).
- Tools/products/workflows: “Exploration Coach” module that auto-derives tool affordances; preflight schema validation and typed parameter hints.
- Assumptions/dependencies: Safe sandboxes to explore tools; rate-limit aware design; guardrails to prevent destructive actions in live repos/sites.
- Context-budgeting and summarization hooks (Industry: software, analytics; Academia)
- What: Add summarization agents and context-pruning heuristics for long-horizon, multi-turn tool sessions (Maps, Playwright, Finance).
- Tools/products/workflows: “Context Budgeter” that monitors token growth per step; server-specific summarizers (HTML-to-DOM facts, itinerary facts, OHLC aggregates); per-domain ablation in MCP-Universe.
- Assumptions/dependencies: Summarizers tuned per domain to avoid loss of critical state; observability for token usage and truncation events.
- Live performance monitoring for time-varying tasks (Industry: travel, fintech, news/media)
- What: Use dynamic evaluators to continuously verify agents handle real-time data (flight prices, weather, live stock data, live issue counts).
- Tools/products/workflows: Production “canary” checks with MCP-Universe dynamic evaluators; performance SLOs tied to live success rates.
- Assumptions/dependencies: Reliable access to live data sources; alerting and fallback strategies; caching for cost control.
- Tool API quality assurance for MCP server providers (Industry: developer platforms, SaaS)
- What: Validate clarity and robustness of MCP tool specs using standardized tasks; identify ambiguous parameters and brittle defaults.
- Tools/products/workflows: “ToolCheck” that runs MCP-Universe task subsets against new server versions; changelog-based compatibility gates.
- Assumptions/dependencies: Versioned schemas and typed parameters; backward-compatibility policies; test tenants for 3rd-party APIs.
- Curriculum and labs for agent tool-use (Academia; Education; Training)
- What: Course modules and workshops that teach long-horizon tool-use, debugging unknown tools, and execution-based evaluation.
- Tools/products/workflows: Ready-to-run MCP-Universe “labs” across domains; grading via format/static/dynamic evaluators; reproducible traces for discussion.
- Assumptions/dependencies: Classroom API credits; snapshot tasks for stable grading windows; clear policies on real-data use.
- Internal risk and reliability audits for agent deployments (Industry: regulated sectors—finance, healthcare-adjacent research)
- What: Use execution-based scoring (not LLM-as-a-judge) to quantify failure modes in content correctness vs. format adherence; track domain-specific weaknesses.
- Tools/products/workflows: Reliability scorecards per domain; incident postmortems using captured traces; thresholding to gate new features.
- Assumptions/dependencies: Data governance for stored traces; redaction tooling; secure storage for API credentials.
- Repository automation readiness checks (Industry: software engineering)
- What: Validate agents’ ability to perform repo tasks (issue triage, branch checks, automation setup) before enabling write permissions.
- Tools/products/workflows: “Dry-run GitOps” in MCP-Universe with branch-check evaluators; staged promotion from read-only to write on green scores.
- Assumptions/dependencies: Sandbox repos; permission scoping; rate limits; rollback policies.
- Browser automation task tuning for operations teams (Industry: ops/support, growth/marketing)
- What: Use Playwright domain tasks to tune agents for booking, analytics, and research; measure improvements tied to concrete success criteria.
- Tools/products/workflows: Task libraries per workflow; site-specific prompt adapters; session-state capture for troubleshooting.
- Assumptions/dependencies: Stable target site layouts; anti-bot considerations; session management and compliance.
- Market-facing benchmarking as product transparency (Industry: AI vendors; Policy)
- What: Publish MCP-Universe scores across domains and evaluator types to give customers objective, execution-grounded performance claims.
- Tools/products/workflows: Public scorecards; third-party audits running the open-source framework; time-stamped, reproducible reports.
- Assumptions/dependencies: Disclosure agreements; comparable compute and configuration; standardized task snapshots.
- Power-user evaluation of personal AI assistants (Daily life; Prosumer)
- What: Compare assistants for travel planning, research, and portfolio lookups on a small curated subset; pick the agent with best real task completion.
- Tools/products/workflows: “Personal Benchmark Pack” with simplified tasks and a UI; periodic retesting as models update.
- Assumptions/dependencies: Minimal setup for non-experts; API costs; clear disclaimers that today’s success rates are modest in some domains.
Long-Term Applications
These applications require further research, scaling, safety/UX work, or ecosystem maturity.
- MCP-native enterprise agents for end-to-end process automation (Industry: finance, logistics, customer ops, ITSM)
- What: Robust agents that chain multiple MCP servers (CRM, ERP, ticketing, analytics, navigation) with verified outcomes.
- Tools/products/workflows: Multi-server orchestration with tool selection/routing; stateful plans; human-in-the-loop checkpoints governed by evaluators.
- Assumptions/dependencies: Stronger long-context handling; safe action guards; audited data access; domain-tuned exploration policies.
- Adaptive tool-learning agents (meta-learning over unknown tools) (Academia; Industry: platforms)
- What: Agents that infer tool affordances and constraints on-the-fly and generalize across new MCP servers with minimal supervision.
- Tools/products/workflows: Exploration-exploitation curricula; automated hypothesis testing for tool parameters; self-generated tool cards.
- Assumptions/dependencies: Safe sandboxes; budgeted exploration; reward shaping via execution-based evaluators.
- Memory and state abstractions for long-horizon tool use (Academia; Software)
- What: Structured persistent state (graphs, typed scratchpads, procedural memory) that compresses context without losing operable details.
- Tools/products/workflows: Domain-specific state serializers (HTML→semantic DOM facts; finance→indicator tables; maps→route graphs); retrieval policies.
- Assumptions/dependencies: Model training or adapters for structured I/O; rigorous ablations on MCP-Universe long-context tasks.
- Auto-evaluator generation and maintenance (Academia; Tooling)
- What: Semi-automated synthesis of evaluators from task specs and schemas to keep pace with evolving tools and data sources.
- Tools/products/workflows: LLM-assisted evaluator drafts with static analysis and sandboxed execution; regression on known gold cases.
- Assumptions/dependencies: Guarded execution; strong unit tests; human review loop to prevent evaluator leakage or drift.
- Sector-specific compliance harnesses (Policy; Industry: finance, healthcare, energy)
- What: Regulatory sandboxes that mandate execution-based evaluations for agents interacting with sensitive systems and real-time data.
- Tools/products/workflows: Compliance profiles (e.g., FINRA-like for finance, HIPAA-like for healthcare prototypes) built on MCP-Universe patterns.
- Assumptions/dependencies: Access-controlled test data; privacy-by-design trace storage; legal frameworks for auditability.
- Standardized certification for MCP servers and agents (Policy; Industry consortia)
- What: Certification labels indicating tool clarity, backward compatibility, and agent success across reference tasks and dynamics.
- Tools/products/workflows: “MCP-Ready” and “MCP-Reliable” badges; public registries; periodic recertification with dynamic evaluators.
- Assumptions/dependencies: Community governance; open test suites; reproducible infrastructure.
- Cross-domain orchestration platforms (Industry: RPA, integration platforms)
- What: Products that offer marketplace-like MCP server catalogs with benchmarked scores, cost/performance trade-offs, and plug-and-play routing.
- Tools/products/workflows: Tool marketplace with telemetry; auto-model routing by domain (e.g., finance vs. automation); cost-aware planning.
- Assumptions/dependencies: Standardized MCP descriptors; billing integration; privacy-preserving telemetry sharing.
- Domain expansion into safety-critical or physical systems (Industry: robotics, mobility, energy; Academia)
- What: MCP servers for IoT/robotics (simulation first), route planning with actuation, and energy system controls, all with execution-based scoring.
- Tools/products/workflows: Digital twins; closed-loop evaluators; intervention policies for safe halting.
- Assumptions/dependencies: High-fidelity simulators; stringent safety guardrails; staged deployment plans.
- Benchmark-driven model training/fine-tuning (Academia; Industry)
- What: Use interaction traces and evaluator outcomes to create robust training curricula for tool-use, long-horizon planning, and format compliance.
- Tools/products/workflows: Synthetic but evaluator-grounded data generation; reward-model training from execution signals; continual learning with drift monitoring.
- Assumptions/dependencies: Licensing for trace data; privacy scrubbing; prevention of evaluator overfitting.
- Automated task routing and portfolio-of-models execution (Industry: platforms, SaaS)
- What: Systems that route tasks to the model/agent pair with the best MCP-Universe profile per domain and evaluator type (format/static/dynamic).
- Tools/products/workflows: Policy engines for routing and fallback; confidence estimation from evaluator histories; cost/latency-aware selection.
- Assumptions/dependencies: Up-to-date scorecards; reliable meta-data about tasks and required tools; orchestration resilience.
- Human-in-the-loop UX patterns formalized by evaluators (Industry: product design)
- What: Interaction designs where evaluators gate when to ask users for clarifications, approvals, or corrections during tool use.
- Tools/products/workflows: “Evaluator-triggered checkpoints”; explainable error surfacing (e.g., date constraints violated); reversible operations.
- Assumptions/dependencies: Granular evaluator signals; UX research; accessibility and localization.
- Public sector technology guidance (Policy; Government)
- What: Procurement playbooks recommending execution-based evaluations (not LLM-as-a-judge) for AI agents that use external tools and live data.
- Tools/products/workflows: Reference MCP-Universe task packs per agency domain; audit logs as public records; transparency reports.
- Assumptions/dependencies: Funding for standardized testbeds; inter-agency data-sharing agreements; sustained maintenance.
Notes on feasibility across applications
- Many immediate deployments depend on API access, rate limits, and cost controls for Google Maps, Playwright, Yahoo Finance, GitHub, and search.
- Execution-based evaluators materially improve rigor but require sandboxing, stable schemas, and careful handling of time-varying ground truth.
- Current success rates indicate production agents should include human-in-the-loop and rollback/guardrail designs; fully autonomous operation is premature in several domains.
- Long-context and unknown-tool challenges imply domain-tuned summarization and exploration policies; one-size-fits-all strategies may degrade performance.
Collections
Sign up for free to add this paper to one or more collections.