- The paper introduces novel diagnostic datasets, ConditionedMath and PuzzleTrivial, to assess and quantify reasoning rigidity in LLMs.
- It proposes a contamination ratio metric and an early detection algorithm to measure deviations from intended reasoning paths.
- Experimental results reveal that base models often exceed reasoning-optimized ones, underscoring challenges in adapting to uncommon instructions.
Diagnosing Instruction Overriding in Reasoning Models
The paper "Reasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models" explores the phenomenon of reasoning rigidity exhibited by LLMs specifically trained for complex reasoning tasks, such as mathematics and logic puzzles. Reasoning rigidity refers to the tendency of these models to default to familiar solution templates, thereby overriding specific user instructions even when the conditions are fully understood.
Introduction
LLMs have been applied to a variety of complex problem-solving tasks, including mathematical reasoning and puzzle-solving. However, despite their advanced capabilities, these models frequently exhibit a form of cognitive bias known as reasoning rigidity. This bias causes the models to ignore or override explicit conditions in favor of well-trodden reasoning paths, leading to erroneous conclusions.
The challenge posed by reasoning rigidity is distinct from hallucinations or prompt brittleness, as it relates to a model's failure to adhere to unfamiliar or atypical conditions. To study this behavior, the authors introduce a diagnostic set consisting of modified mathematical and puzzle-based benchmarks that require models to deviate from familiar reasoning strategies.
Diagnostic Dataset: ConditionedMath and PuzzleTrivial
The authors present two specialized datasets designed to evaluate reasoning rigidity:
- ConditionedMath: This dataset is derived from existing mathematical benchmarks like AIME and MATH500. It consists of problems with carefully introduced variations that require unfamiliar solution trajectories (Figure 1). This challenges the models to detect and adapt to new constraints rather than relying on preconceived reasoning patterns.
- PuzzleTrivial: This dataset includes logic puzzles that have been subtly altered to simplify the required reasoning or to introduce new constraints. The modifications are intended to evaluate the models' ability to follow straightforward logic rather than revert to familiar templates.

Figure 1: Dataset Construction Pipeline of ConditionedMath, highlighting two steps to create valid, meaningfully different, and solvable questions.
Analysis of Reasoning Patterns
Through systematic evaluation using the introduced datasets, the authors identify three modes of contamination in model reasoning:
- Interpretation Overload: Models reinterpret straightforward instructions in multiple ways, leading to contradictions.
- Input Distrust: Models assume errors in the input, complicating the reasoning process unnecessarily.
- Partial Instruction Attention: Models selectively attend to parts of the instruction, often ignoring key elements.
These modes cause deviations from the intended reasoning paths, resulting in failures to comply with user-specified constraints.
Contamination Ratio and Detection
The authors propose a metric called the contamination ratio to quantify the extent of reasoning contamination. This ratio measures the proportion of reasoning steps in which the model defaults to familiar patterns over the provided instructions. Additionally, they introduce an early detection algorithm to facilitate the identification of contamination in cases where ground-truth labels are unavailable (Figure 2).
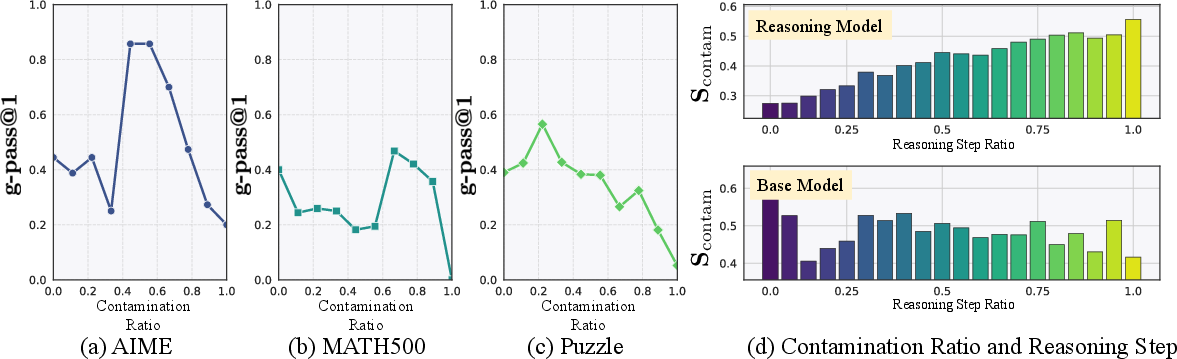
Figure 2: Patterns associated with contamination ratio, indicating how contamination affects reasoning accuracy.
Experiments and Observations
Experimental results indicate that base models often outperform their reasoning-optimized counterparts on modified datasets. This counterintuitive outcome suggests that reasoning models are more susceptible to rigidity. Base models, in contrast, are better at adhering to explicit instructions when the initial understanding of the problem is correct.
The authors also explore mitigation strategies such as budget forcing and prompt hinting but observe mixed effectiveness. While some adjustments yield performance improvements, others do not consistently overcome the rigidity issue.
Conclusion
The study underscores the need for improved understanding and mitigation of reasoning rigidity in LLMs. The diagnostic datasets and tools introduced provide a valuable foundation for future research aimed at enhancing model adherence to user instructions. The findings highlight the complexity of reinforcing reasoning capabilities in AI systems and emphasize the necessity for more robust training paradigms.
Developing models that can reliably deviate from familiar patterns when warranted remains a critical goal. Continued investigation into the cognitive biases manifest in model reasoning will be essential for advancing AI capabilities in domains requiring precise adherence to diverse and dynamic constraints.