- The paper introduces a cognition-inspired segmentation framework that decomposes recognition into conceptual understanding followed by spatial perception.
- It uses a generative vision-language model and concept-aware enhancer to fuse semantic features with visual cues for robust segmentation.
- Experimental results show significant gains across datasets, highlighting its versatility in both vocabulary-free and open vocabulary segmentation.
Cognition-Inspired Open Vocabulary Image Segmentation Framework
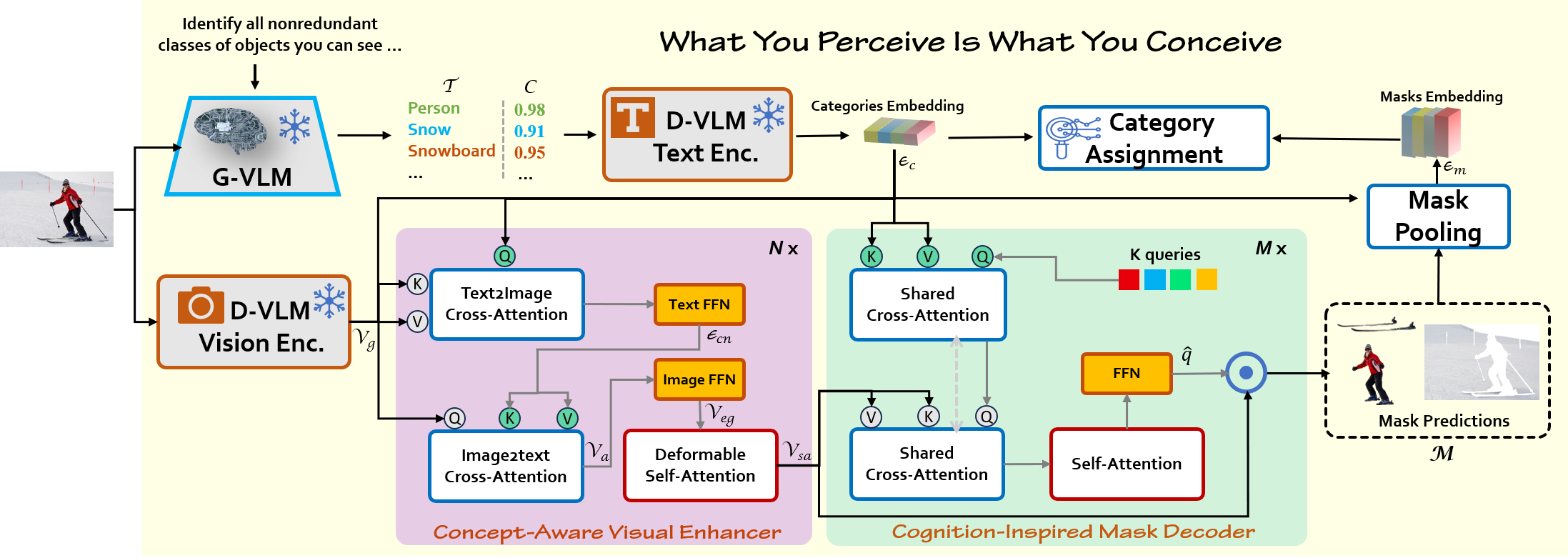
The paper introduces a novel Cognition-Inspired Framework designed for open vocabulary image segmentation, drawing inspiration from the human visual recognition process. The core idea is to mimic how humans first develop a conceptual understanding of an object and then perceive its spatial extent. This framework addresses the limitations of existing methods that often struggle with aligning region segmentation and target concepts, especially when dealing with dynamically adjustable, predefined novel categories at inference time. The proposed framework demonstrates enhanced flexibility in recognizing unseen categories and achieves significant improvements in segmentation performance across various datasets.
Key Components of the Framework
The Cognition-Inspired Framework emulates the human visual recognition process, encapsulated as "What You Perceive Is What You Conceive," and comprises three core components:
Implementation Details
The implementation details of the Cognition-Inspired Framework are as follows:
- The model utilizes a frozen ConvNeXt-Large visual backbone from OpenCLIP, trained for 50 epochs on the COCO Panoptic dataset.
- The Concept-Aware Visual Enhancer consists of N=6 stacked layers, while the Cognition-Inspired Mask Decoder consists of M=9 stacked layers.
- Training involves a combination of binary cross-entropy loss (Lpixel), Dice loss (Ldice), and cross-entropy loss (Lcls), with hyperparameters λ1=2.0, λ2=5.0, and λ3=5.0 to balance the different loss terms.
- The model is optimized using AdamW with a learning rate of 1e−4 and a weight decay of $0.05$.
- During inference, the framework supports two modes: Vocabulary-Free Mode, which relies solely on concepts generated by the G-VLM, and Open Vocabulary Mode, which reweights category predictions using G-VLM-generated concepts.
Experimental Results
The paper presents extensive experimental results that validate the effectiveness of the proposed framework.
Vocabulary-Free Segmentation
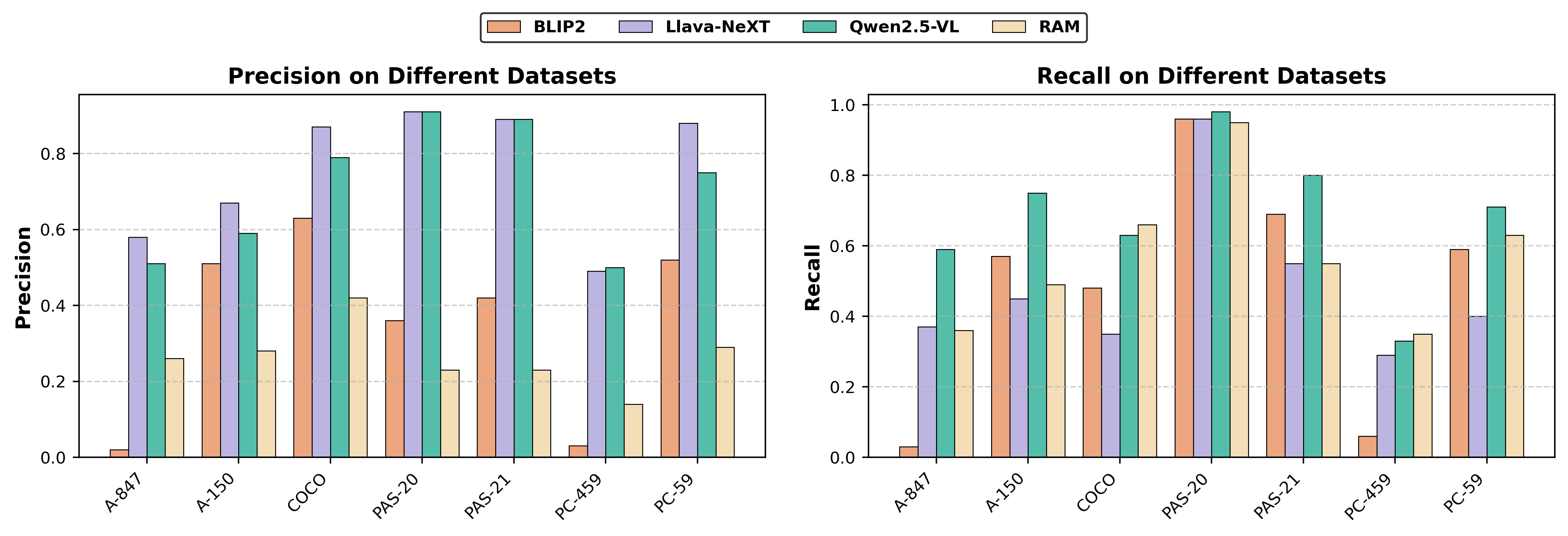
One notable aspect of the Cognition-Inspired Framework is its support for vocabulary-free segmentation, which eliminates the need for manually defined categories. The framework leverages the G-VLM to generate relevant concepts, enabling segmentation without predefined vocabularies. The results demonstrate that the framework can generalize effectively across diverse scenarios, highlighting its versatility and adaptability.
Analysis of Visual Features
The paper includes a qualitative analysis of the visual features learned by the framework. By visualizing K-means clustering results, the authors demonstrate that the Concept-Aware Visual Enhancer effectively captures contextual cues and maintains semantic consistency, even in cluttered or low-contrast scenarios. The enhanced visual features exhibit stronger spatial structure aggregation and more semantically coherent representations compared to the original global visual features.

Figure 3: Visualization of K-means clustering of visual features with and without the Concept-Aware Visual Enhancer.
Conclusion
The Cognition-Inspired Framework represents a significant advancement in open vocabulary image segmentation. By mimicking human cognitive processes, the framework overcomes the limitations of conventional models and achieves state-of-the-art performance across various benchmarks. The framework's ability to perform vocabulary-free segmentation enhances its adaptability in real-world scenarios, making it a promising approach for future research and applications in computer vision.