- The paper demonstrates that current key-value cache systems, such as Redis, are inefficient for LLM prefix prefill workloads due to high metadata overhead.
- It identifies novel access patterns, including high temporal locality and initial token reusability, which can guide the design of more efficient caching systems.
- Experimental evaluations show that even optimized systems like CHIME and Sherman underperform by 10.3% and 5.5%, highlighting the need for specialized cache management solutions.
Efficient Key-Value Cache Management for LLM Prefix Prefilling
The paper "Towards Efficient Key-Value Cache Management for Prefix Prefilling in LLM Inference" investigates the inefficiencies in existing key-value store solutions when applied to LLM workloads, particularly focusing on the prefix prefill problem in LLM inference. This comprehensive analysis reveals novel access patterns associated with key-value cache (KVC) management and highlights the need for optimized systems to handle these unique workloads.
Introduction
LLMs utilize transformers with attention mechanisms that require significant memory, especially as context window sizes increase. This poses a challenge for efficient prefix prefill mechanisms, which are designed to cache frequently used input sequences to reduce redundant computations and delivery time for the first token (TTFT) during inference. The current systems, like Redis, CHIME, and Sherman, fail to cater to the unique access patterns of KVC workloads, impacting scalability and latency adversely.
Analysis of KVC Access Patterns
The research involved an analysis of publicly available KVC traces from applications like Mooncake to identify access patterns and reuse characteristics.
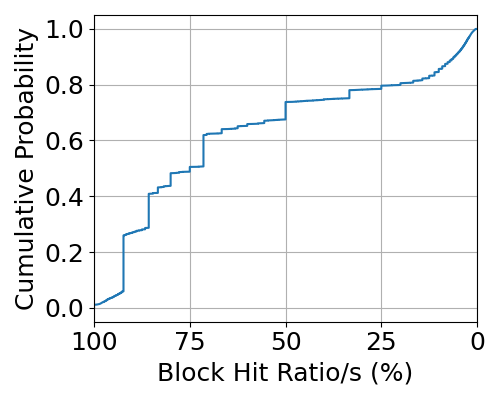
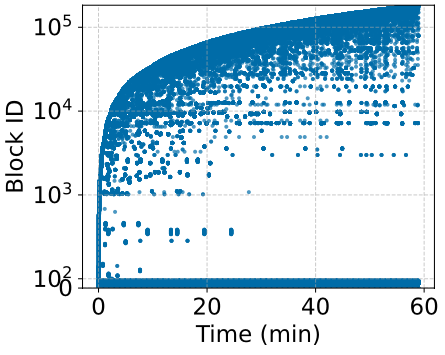
Figure 1: Block Reusability over 1-Hour Trace.
The study revealed:
- High Temporal Locality: Recent tokens exhibit substantial access locality, implying frequent reuse possibilities.
- Significant Initial Token Reusability: Initial tokens across multiple requests show high reusability, indicating opportunities for redundant computation avoidance.
- Mixed Access Patterns: KVC workloads involve high-sequence access with sporadic random block accesses. This challenges conventional caching systems as illustrated by the distinct patterns of sequential and random accesses in the study.
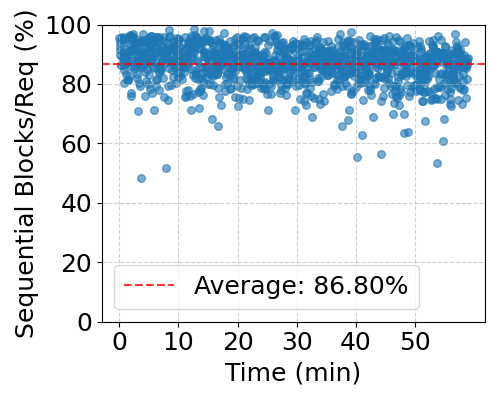
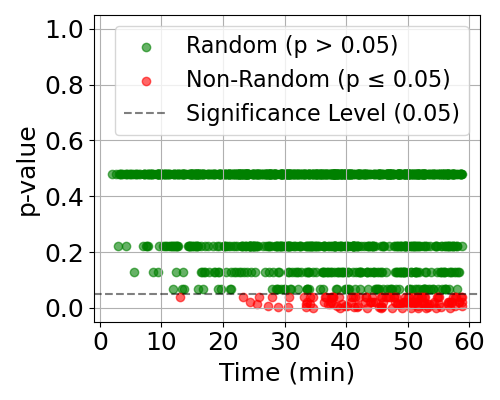
Figure 2: Sequential and Random Access Pattern in Requests.
Experimental Evaluation
The performance of Redis, CHIME, and Sherman in handling range queries and random accesses was systematically evaluated to quantify their limitations:
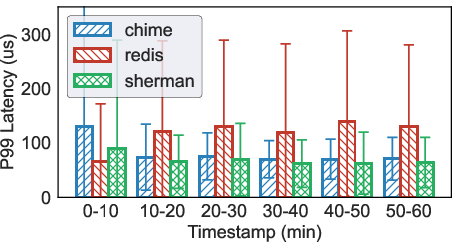
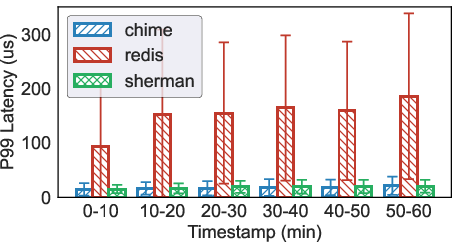
Figure 3: P99 Range Query Latency.
Redis, reliable yet traditional, demonstrated inefficient handling of KVC metadata due to its operational overhead. Although CHIME and Sherman optimized for disaggregated memory systems, they exhibit marginally better performance but still fall short for KVC prefill workloads by 10.3% and 5.5%, respectively.
Key insights from the research indicate:
- Incompatibility of Existing Systems: Traditional systems like Redis are unsuited for modern KVC workloads due to high index times and inability to exploit key reusability effectively.
- Increased Overhead with Optimization Techniques: Techniques such as chunked prefill and KVC compression amplify metadata management, stressing the need for solutions that address both metadata operations and efficient cache layouts.
- Insufficiency of YCSB Benchmarking: The YCSB workloads do not adequately represent the unique metadata access patterns required for prefix prefill, necessitating new benchmarks for meaningful evaluations.
Conclusions and Future Work
The findings suggest a critical gap in existing solutions to efficiently manage metadata in KVC systems supporting prefix prefill workloads. There is a pronounced need for developing specialized metadata management systems that strike a balance between efficient sequential retrieval and handling random block accesses. Future research will focus on creating optimized caching structures and comprehensive benchmarks that truly reflect the access patterns and demands of contemporary KVC workloads.
In conclusion, the paper highlights the inadequacies of current key-value store solutions in supporting prefix prefill workloads and methods for advancing KVC metadata management that aligns with the unique demands and patterns of LLM inference.