- The paper introduces CoT2, demonstrating that continuous tokens can effectively enable parallel reasoning in models.
- The methodology combines attention and mixture-of-experts layers with continuous supervision and reinforcement learning to enhance convergence and accuracy on tasks like MNNS and ProsQA.
- Empirical results reveal that CoT2 outperforms traditional discrete chain-of-thought methods, showcasing its efficacy in complex reasoning and combinatorial problem-solving.
Continuous Chain of Thought Enables Parallel Exploration and Reasoning
The paper introduces the concept of conducting chain-of-thought (CoT) reasoning with continuously-valued tokens, referred to as CoT2. This approach is posited as an enhancement over traditional discrete token methods due to its potential to handle multiple parallel reasoning paths, offering richer and more efficient solutions in logical reasoning tasks.
Theoretical Foundations and Model Construction
Theoretical analysis in the paper shows that CoT2 allows models to track multiple reasoning paths concurrently, significantly boosting inference efficiency. The paper provides a comprehensive example with the Minimum Non-Negative Sum (MNNS) task, demonstrating that a single-layer transformer using CoT2 can solve complex combinatorial problems with sufficient embedding dimensions. The structure effectively combines attention mechanisms with a mixture-of-experts MLP layer, ensuring all partial sums are strategically encoded and managed.
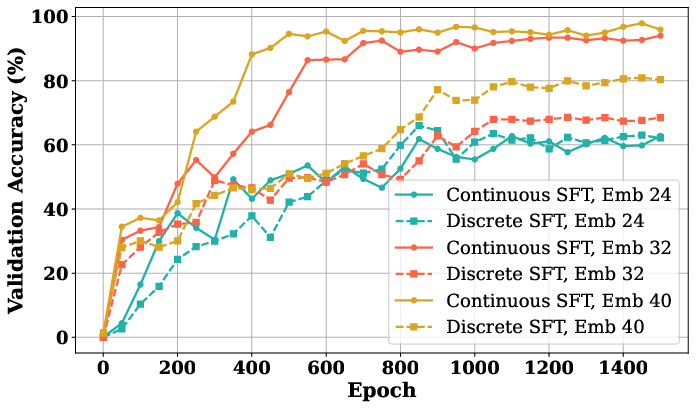 *Figure 1: The figure reveals that CoT2 model is superior to discrete CoT in ProsQA, while also exhibiting faster convergence. Setting: 4âlayer, 4âhead GPT2 with d∈{24,32,40.
*Figure 1: The figure reveals that CoT2 model is superior to discrete CoT in ProsQA, while also exhibiting faster convergence. Setting: 4âlayer, 4âhead GPT2 with d∈{24,32,40.
Supervised Training Techniques
The paper details a Continuous Supervised Fine-Tuning (CSFT) strategy for training CoT2 models. This approach involves fitting the softmax outputs to empirical token distributions from a set of target traces, providing a dense supervision signal that guides models toward efficient parallel exploration. Such an approach capitalizes on the potential of continuous tokens to represent multiple hypotheses, improving both accuracy and convergence speed, as illustrated in various tasks like MNNS and ProsQA.
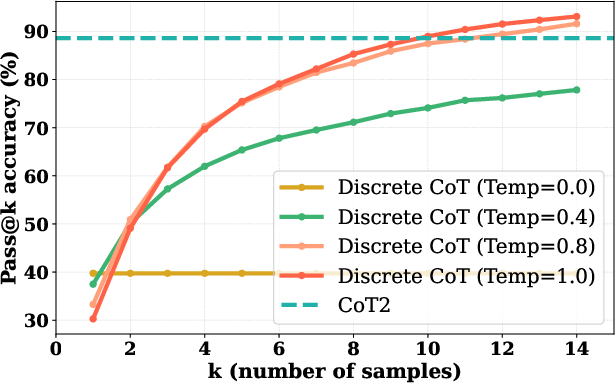
 *Figure 2: CoT2 vs.\ discrete CoT (Pass@k) accuracies for different temperatures on MNNS task.
*Figure 2: CoT2 vs.\ discrete CoT (Pass@k) accuracies for different temperatures on MNNS task.
Reinforcement Learning and Sampling Strategies
The work further enhances CoT2 using reinforcement learning (RL) approaches, introducing Multi-Token Sampling (MTS) and continuous exploration via Dirichlet sampling. These techniques encourage the model to explore wider reasoning paths and improve its policy over time. The RL strategies are supported by experiments showing improved accuracy and reduced token entropy, indicating more confident and precise model predictions.
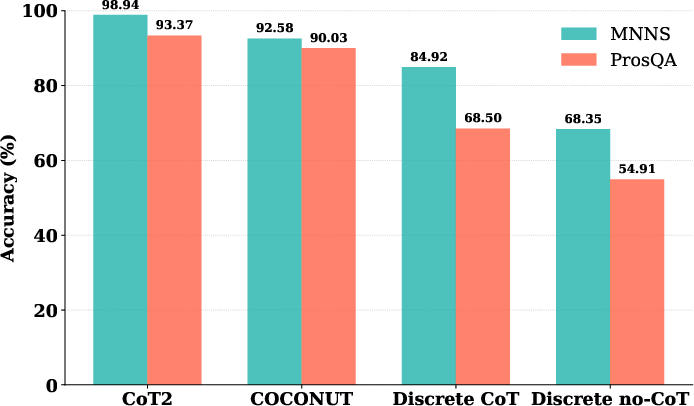
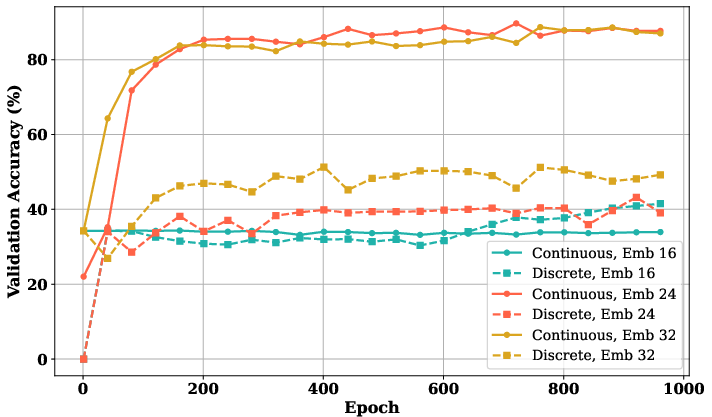 *Figure 3: Comparison between CoT2 and discrete CoT model for different embedding dimensions. The figure demonstrates that above a certain embedding dimension threshold, the CoT2 model outperforms the discrete CoT model in the MNNS task.
*Figure 3: Comparison between CoT2 and discrete CoT model for different embedding dimensions. The figure demonstrates that above a certain embedding dimension threshold, the CoT2 model outperforms the discrete CoT model in the MNNS task.
Empirical Results and Comparative Analysis
Experiments conducted on the MNNS, ProntoQA, and ProsQA datasets underscore the efficacy of CoT2, particularly at higher embedding dimensions where the model exhibits superior performance and faster training convergence compared to discrete CoT models. These results validate the theoretical benefits, with CoT2 models effectively balancing exploration and computation efficiency through its continuous token approach.
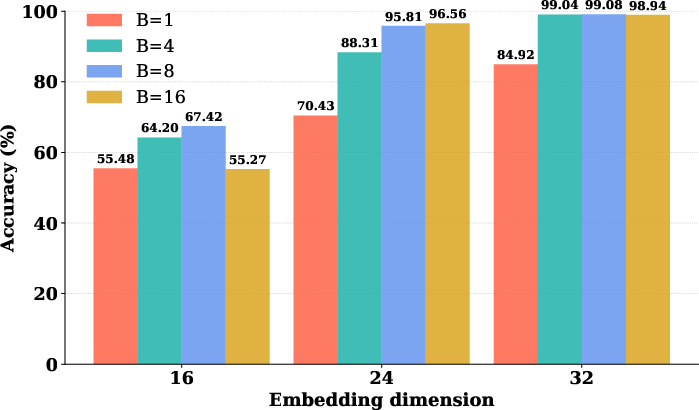
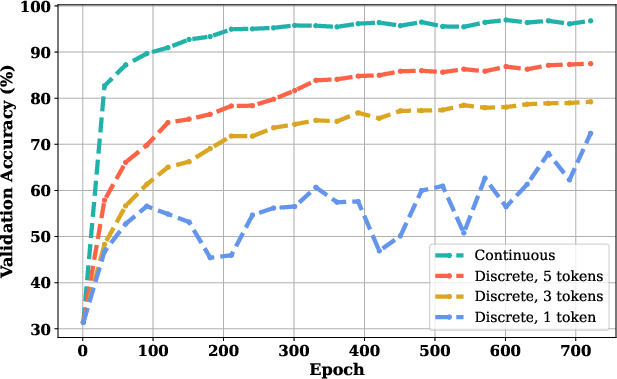 *Figure 4: The figure illustrates that when the range of digits makes the question non-trivial on an MNNS task, the discrete CoT model trained with full token supervision outperforms sparse supervisions; in particular, single token supervision yields the worst performance.
*Figure 4: The figure illustrates that when the range of digits makes the question non-trivial on an MNNS task, the discrete CoT model trained with full token supervision outperforms sparse supervisions; in particular, single token supervision yields the worst performance.
Conclusion
The paper presents CoT2 as a significant advancement in the implementation of logical reasoning in AI models. By leveraging continuous tokens for more expressive and parallel path exploration, CoT2 demonstrates substantial improvements in both theoretical robustness and empirical performance. Future work is encouraged to explore further optimization methods and applications of CoT2 in diverse reasoning tasks, expanding the boundaries of efficient and scalable AI reasoning systems.