- The paper presents the RAIF framework, which incentivizes deep reasoning with reinforcement learning to improve complex instruction-following in LLMs.
- It uses reproducible instruction synthesis and rule-centric rewards to overcome the limitations of supervised fine-tuning and basic chain-of-thought approaches.
- RAIF achieves up to 11.74% performance gains across benchmarks and demonstrates scalability and generalization across different model sizes and domains.
Incentivizing Reasoning for Advanced Instruction-Following of LLMs
The paper presents a method called "RAIF" aimed at improving the instruction-following capabilities of LLMs, specifically under complex instructions that involve various constraints and compositional structures such as And, Chain, Selection, and Nested. RAIF adopts a unique approach by incentivizing reasoning through reinforcement learning with verifiable rewards, addressing the shortcomings of traditional methods like supervised fine-tuning and basic chain-of-thought (CoT) prompting.
Challenges with Complex Instructions
LLMs struggle with complex instructions that encompass multiple constraints arranged in parallel, chained, or branched formats. These instructions often lead to models failing to observe certain constraints or misinterpreting nested instructions. Traditional methods have relied predominantly on either supervised fine-tuning or crafting specific inference templates, but both approaches suffer from overfitting and generalization issues due to exhaustive constraint enumeration.

Figure 1: Complex instructions with various atomic constraints and compositions pose great challenges to instruction-following capabilities of LLMs.
Basic CoT, despite its intuitive appeal, often results in negative impact due to superficial reasoning patterns where models merely paraphrase instructions without understanding hierarchical relationships among constraints.
Proposed Method: RAIF
RAIF seeks to systematically enhance LLM performance on complex instructions through incentivizing reasoning. It combines a scalable instruction synthesis method with rule-centric reinforcement learning.
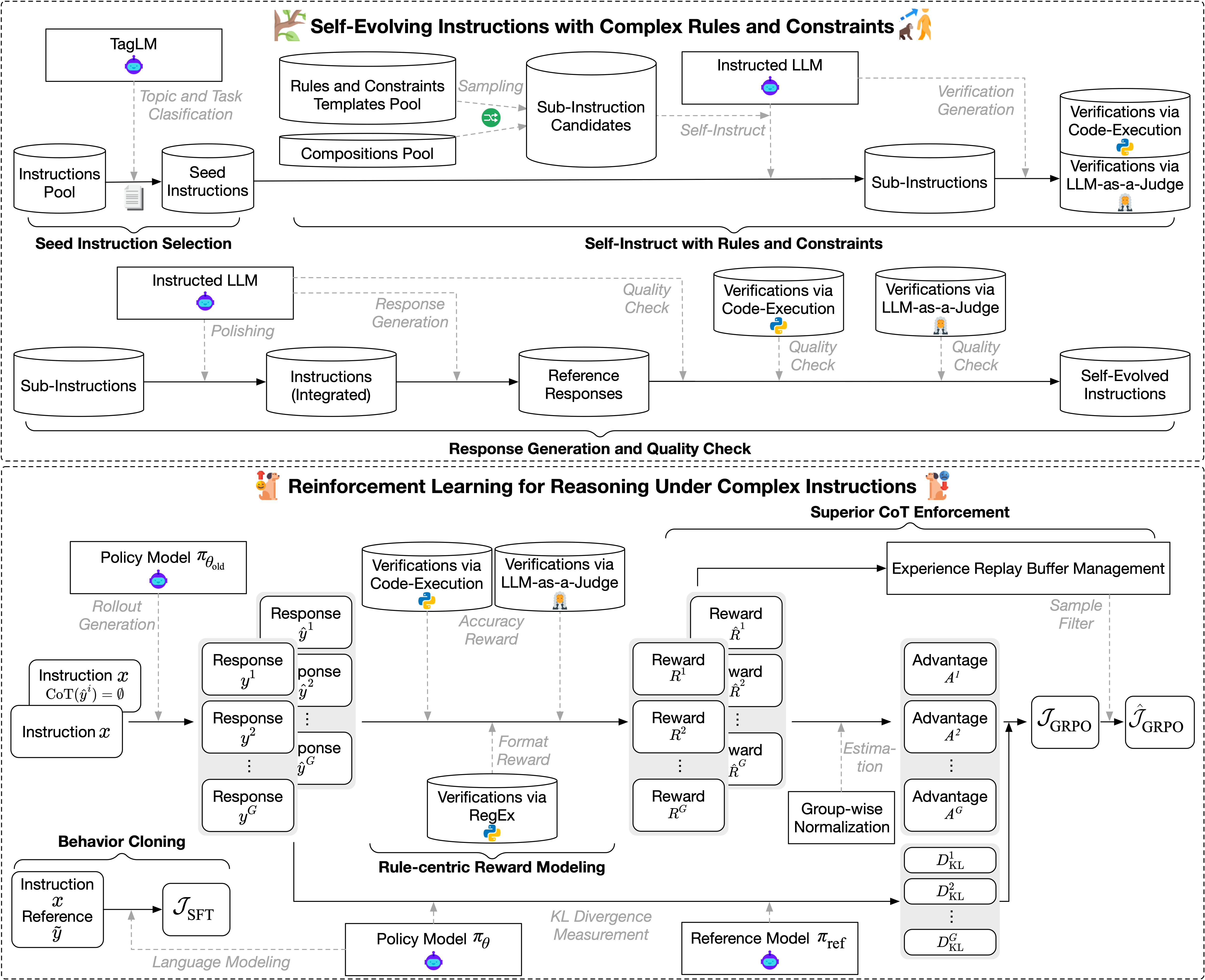
Figure 2: Illustration of the proposed method for advanced instruction-following via reasoning.
Data Synthesis and Reinforcement Learning
- Instruction Synthesis: RAIF employs a reproducible data acquisition method based on the decomposition of complex instructions into atomic constraints. The process involves evolving dynamic and diverse complex instructions across varied tasks and domains.
- Reinforcement Learning: This utilizes verifiable rule-centric reward signals specifically tailored to encourage deep reasoning. RAIF fosters superior CoT through sample-wise contrast and behavior cloning from expert models. It guides the steady shift in distribution from swift LLMs to adept reasoners, ensuring that reasoning is strategic and adheres to established rules.
RAIF systematically addresses the challenge of shallow reasoning by filtering out ineffective CoT, only allowing effective, deep reasoning that results in improved instruction-following quality.
Generalization and Scalability
RAIF not only proves effective on seven benchmarks but also demonstrates generalization across model families, sizes, and out-of-domain constraints. Testing results indicate that RAIF enables a 1.5B LLM to achieve performance comparable to an 8B LLM with 11.74% gains.
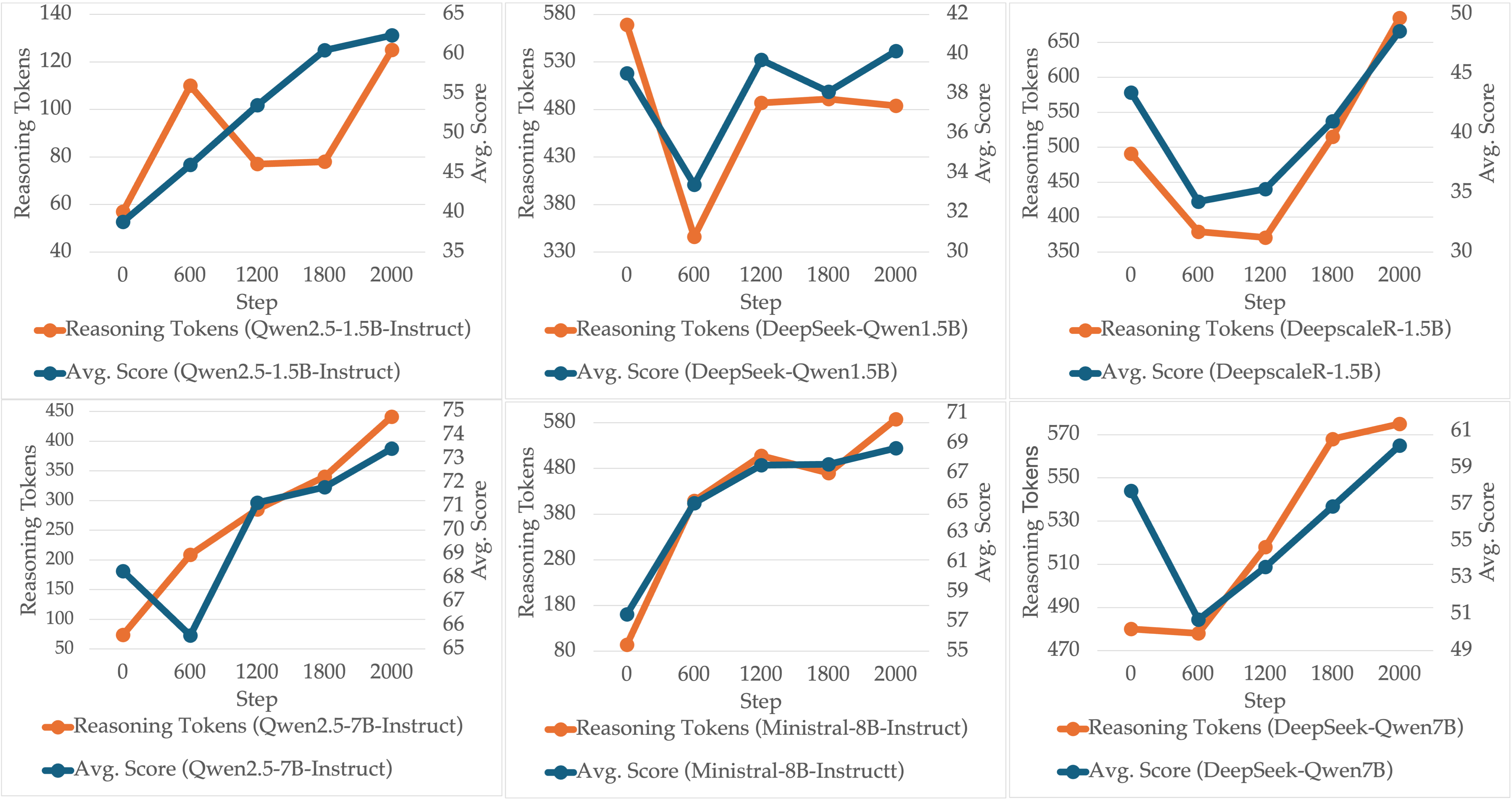
Figure 3: The averaged number of reasoning tokens and scores over steps (best viewed magnified).

Figure 4: The averaged frequency change of keyword tokens of DeepSeek-Qwen1.5B, DeepScaleR-1.5B, Qwen2.5-1.5B-Instruct, and Qwen2.5-7B-Instruct before/after RL.
Implications and Future Directions
The RAIF methodology highlights fundamental differences between reasoning required for mathematical problems versus those under complex instructions, suggesting a pioneering direction that demystifies the cultivation of reasoning through reinforcement learning.
Further implications point to RAIF's potential to evolve instructive LLMs beyond specific benchmarks, possibly paving avenues for improvements in multi-purpose tasks and even tasks requiring out-of-domain generalization. Future work may involve scaling datasets significantly to accommodate larger models and broader application reach.
Conclusion
RAIF introduces a novel framework for enhancing LLM capabilities in complex instruction-following through incentivized deep reasoning. By intertwining strategic data synthesis with advanced reinforcement learning techniques, RAIF sets a new benchmark for scalable, constructive solutions to instruction-following, promising consistent improvements across diverse model types and application domains.