- The paper introduces a novel framework, Light-IF, that mitigates lazy reasoning via preview and self-checking to improve instruction-following in LLMs.
- It employs techniques such as hardness-aware prompt synthesis, Zero-RL cold start, and entropy-preserving SFT to boost generalization and compliance.
- Empirical results show Light-IF-32B achieving superior benchmark scores, validating the dense reward and token-adaptive RL approach in complex settings.
Light-IF: Empowering Generalizable Reasoning in LLMs via Preview and Self-Checking
Motivation and Problem Characterization
Instruction following is a critical capability for LLMs, particularly as they transition from generative next-token predictors to reliable assistants across domains requiring strict adherence to complex directives. Existing instruction-following LLMs display inconsistent compliance, with a pronounced limitation when tasked with constraint-heavy prompts. Analysis reveals that this inconsistency is primarily due to a prevalent phenomenon known as "lazy reasoning"—models often recite instructions rather than perform genuine compliance checking or rigorous self-assessment.
Importantly, as illustrated in (Figure 1), mainstream reasoning models like Qwen3-32B lack explicit preview and self-checking mechanisms, causing severe underperformance on benchmarks such as SuperCLUE, CFBench, and IFBench. The authors hypothesize that incentivizing effective reasoning patterns, specifically preview and self-checking, yields instruction-following improvements that generalize beyond training constraints.

Figure 1: Comparison of reasoning patterns between Qwen3-32B (lazy reasoning) and Light-IF-32B (explicit preview/self-checking).
Framework: Data Synthesis, Cold-Start, and Entropic Reinforcement
The Light-IF framework is meticulously designed to address lazy reasoning and enforce generalizable reasoning patterns. The approach comprises hardness-aware prompt synthesis, Zero-RL for incentivizing length and correctness, cold-start learning from filtered high-quality responses, entropy-preserving SFT, and token-wise entropy-adaptive RL with dense rewards. The process flow is visualized in (Figure 2).
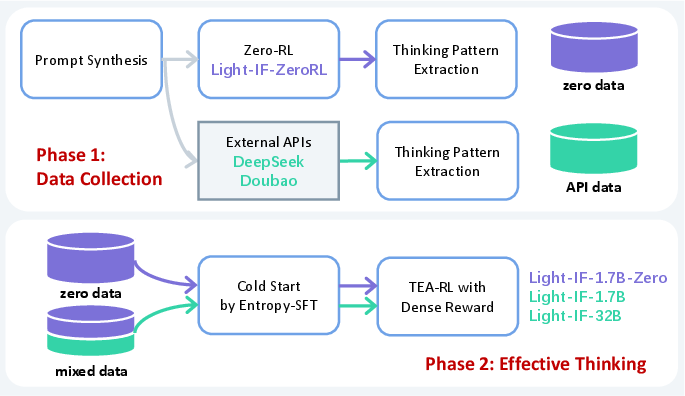
Figure 2: End-to-end pipeline of the proposed framework, including prompt synthesis, cold-start, Entropy-SFT, and TEA-RL.
Hardness-Aware Prompt Synthesis
Leveraging historical and in-house evaluation prompts, the authors generate seed prompts, expand them using Self-Instruct, and then inject verifiable constraints sampled from controlled templates. This yields 50k complex instruction prompts filtered for validity via automated code verification, producing "pass," "easy," and "hard" prompt sets as shown in (Figure 3).
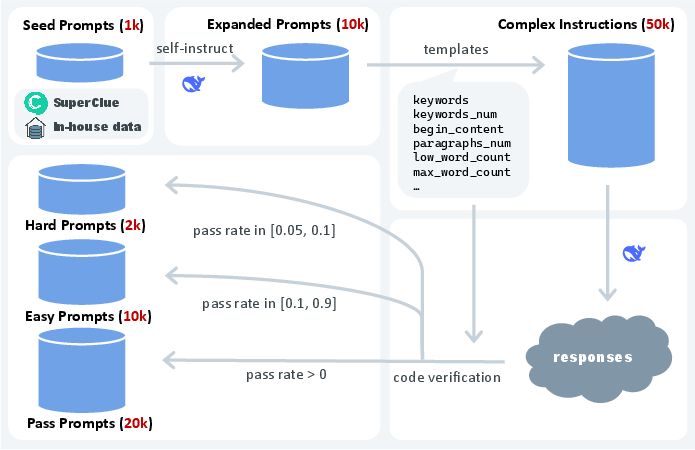
Figure 3: Hardness-aware prompt synthesis pipeline yielding distinct prompt difficulty sets.
Zero-RL Cold Start and Thinking Pattern Extraction
Zero-RL training post-trains the base model to discourage lazy-thinking via a reward design targeting both correctness (Rc) and response length (Rl). The relationship between length and correctness during Zero-RL is depicted in (Figure 4), where emergence of preview/self-checking correlates with improved compliance.
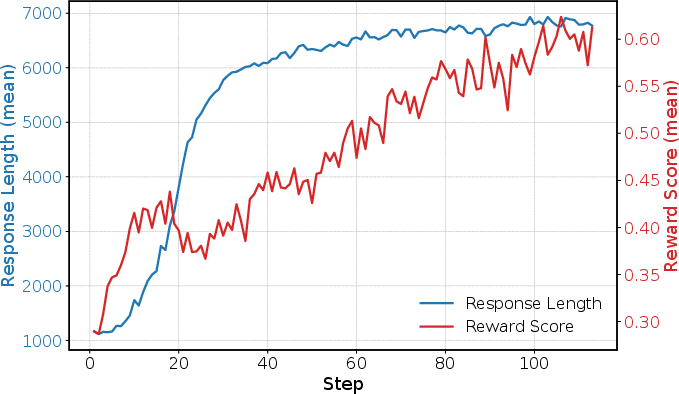
Figure 4: Response length positively correlates with correctness during Zero-RL, supporting preview/self-checking emergence.
High-quality reasoning samples exhibiting preview and self-checking behaviors are extracted via automated correctness, thinking content, and fluency checks, forming the cold-start dataset. Two strategies are employed: "zero data" (solely from Zero-RL) and "mixed data" (combining strong APIs for additional guidance).
Entropy-Preserving SFT and Token-Wise Entropy-Adaptive RL
Standard SFT produces entropy collapse, constraining exploration in RL. The Entropy-SFT algorithm counteracts this by selectively computing loss on tokens with high NLL and controlled entropy, favoring tokens crucial for preview/self-checking and preserving entropy for future RL (see (Figure 5), token rank evolution).
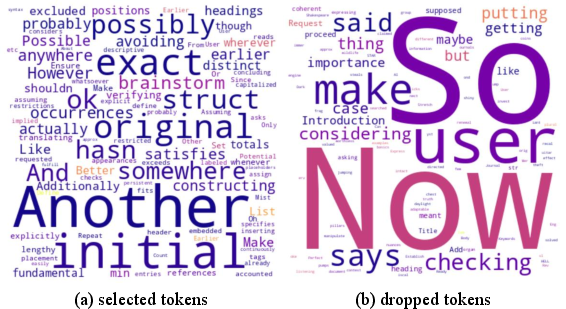
Figure 5: High-frequency, high-rank tokens emerge during the cold-start stage, reflecting preview and checking pattern induction.
TEA-RL regularizes entropy at the token level during RL, preventing collapse and facilitating behavioral generalization. Dense rewards are assigned for partial constraint satisfaction, smoothing the reward landscape and accelerating policy optimization. Entropy dynamics over RL stages are visualized in (Figure 6), highlighting the effectiveness of Entropy-SFT + TEA-RL versus conventional methods.
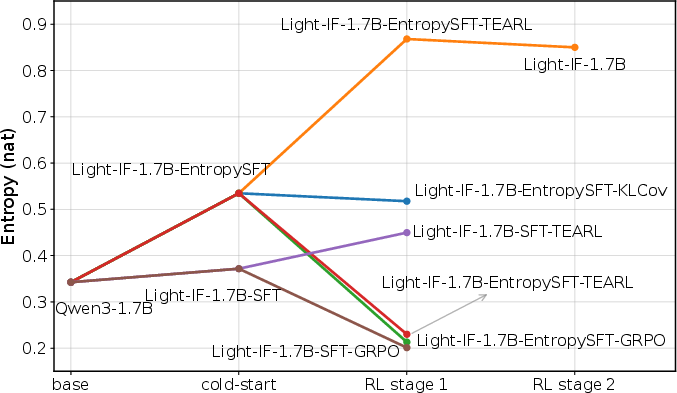
Figure 6: Entropy trajectories for different training strategies, with Entropy-SFT/TEA-RL yielding sustained exploration.
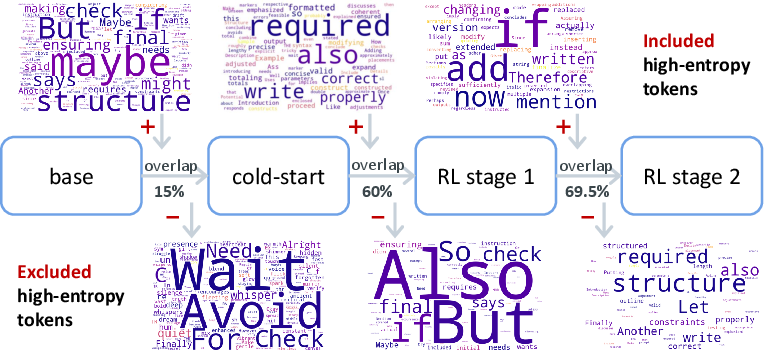
Figure 7: Evolution of high-entropy tokens across training, evidencing preview and self-checking pattern integration.
Empirical Evaluation and Ablation Analyses
Light-IF models (Light-IF-32B, Light-IF-1.7B, and Light-IF-1.7B-Zero) are evaluated against recent reasoning/non-reasoning SOTA models on IFEval, CFBench, IFBench, SuperCLUE, and instruction-following variants. Quantitative results show Light-IF-32B achieving the highest scores across all benchmarks, outperforming DeepSeek-R1 and Doubao-1.6 by substantial margins, e.g., +13.9 SuperCLUE, +9.8 IFBench. Light-IF-1.7B with fewer parameters matches or exceeds Qwen3-235B-A22B and Qwen3-32B in several benchmarks (see (Figure 8)).
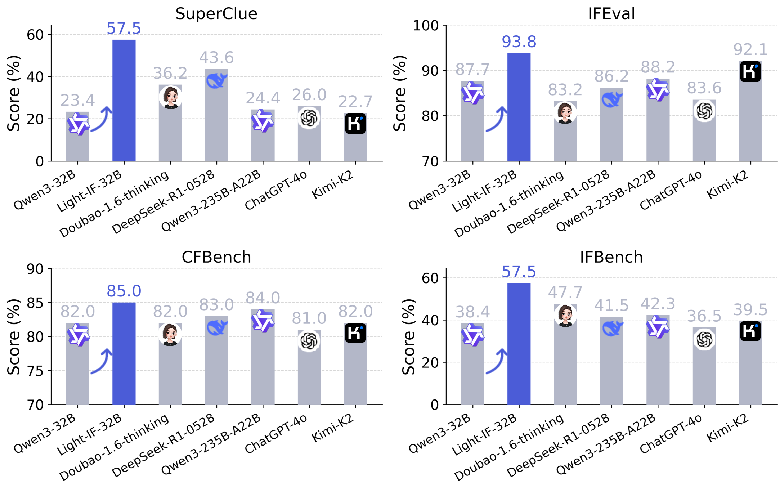
Figure 8: Main results of models on instruction-following benchmarks—Light-IF-32B demonstrates top-ranking performance.
Ablation studies validate the necessity of each pipeline component: the cold-start stage and sequential RL with dense rewards significantly increase final performance. Entropy-SFT and TEA-RL both yield superior outcomes versus SFT and GRPO alone, confirming the importance of entropy management for instruction-faithful generation.
Reward Engineering and Entropy Control
The dense reward strategy demonstrates rapid, stable RL policy improvement compared to sparse rewards, as visualized in (Figure 9). TEA-RL robustly maintains high entropy during RL, unlike traditional entropy regularization, preventing collapse/explosion and supporting exploration as visualized in (Figure 10).
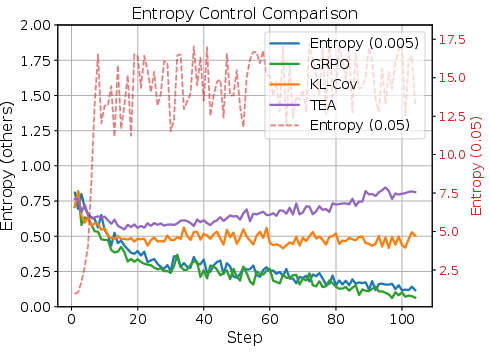
Figure 10: Entropy control via TEA-RL maintains high exploration and prevents collapse during RL.
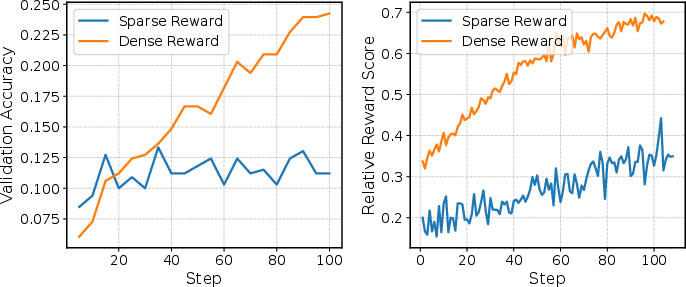
Figure 9: Rapid reward improvement with dense reward assignment compared to sparse reward RL.
Implications and Future Directions
Light-IF establishes a robust framework for enforcing generalizable reasoning in LLMs, applicable across both seen and unseen complex constraints without the extensive data requirements of prior SFT/DPO paradigms. Preview and self-checking patterns, once learned from a controlled dataset, generalize to broader domains, improving reliability and compliance. Entropy management emerges as a critical variable, with token-adaptive techniques facilitating advanced exploration and policy stability in RL.
Future work may explore further minimization of data requirements for cold start, scaling TEA-RL to larger models, and extending reasoning pattern induction to multilingual or multimodal tasks. The framework's modularity, especially its entropy and reward components, positions it as a template for instruction-following improvements in agentic, task-critical, and safety-sensitive LLM deployments.
Conclusion
The Light-IF framework presents a principled methodology for endowing LLMs with generalizable reasoning via preview and self-checking. By synthesizing complex instruction prompts, incentivizing effective reasoning behaviors through Zero-RL, filtering for high-quality cold-start samples, and employing entropy-preserving SFT and token-adaptive RL, Light-IF models achieve superior performance on instruction-following benchmarks. Empirical and ablation analyses confirm the efficacy and necessity of each pipeline stage, with entropy control playing a decisive role. This approach advances practical and theoretical understanding of instruction-following LLMs and informs future developments in RL-driven reasoning automation.
(2508.03178)