- The paper introduces VerIF, a method that integrates rule-based code checks with LLM semantic verification to enforce both hard and soft constraints.
- It employs the VerInstruct dataset and GRPO algorithms to achieve significant performance gains on benchmarks like IFEval and Multi-IF.
- VerIF enhances RL training without compromising model generalizability, enabling robust performance across diverse instructional tasks.
VerIF: Verification Engineering for Reinforcement Learning in Instruction Following
This essay explores the concept of VerIF, a verification methodology tailored for reinforcing learning in instruction-following tasks. It integrates rule-based and LLM-based verification methods to bolster the capabilities of LLMs in adhering to complex instructional constraints.
Introduction to VerIF and Its Conceptual Basis
VerIF is situated in the broader context of reinforcement learning with verifiable rewards (RLVR), an arena that has gained traction for enhancing LLMs. VerIF innovatively combines rule-based code verification for addressing hard constraints, such as response length, with LLM-based verification mechanisms designed to handle the more nuanced soft constraints, like stylistic or semantic requirements (Figure 1).
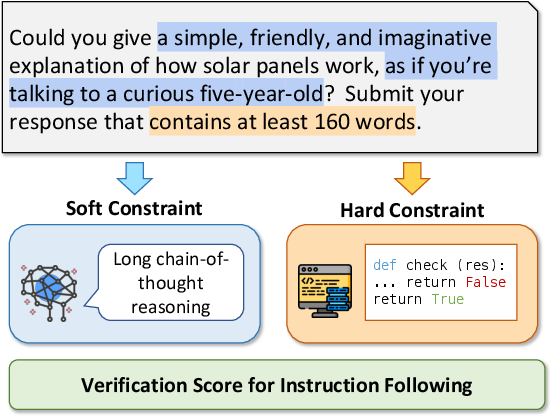
Figure 1: A simplified illustration of VerIF. The instruction constraints are categorized as soft or hard and verified using different methods in VerIF.
The core distinction between hard and soft constraints is pivotal in this context. Hard constraints are deterministic in nature, hence easily evaluated through code. Conversely, soft constraints necessitate an LLM's semantic understanding for accurate verification. This dual approach allows for a comprehensive verification system suitable for varied instructional directives.
Methodology: VerInstruct Dataset and VerIF Implementation
A significant contribution of this research is the VerInstruct dataset, comprising roughly 22,000 instruction instances paired with verification signals. The dataset construction involves augmenting instructions with constraint back-translation techniques to introduce additional hard and soft constraints, following verification through either automatically generated code or LLM judgment.
The RL training involves the application of GRPO algorithms with reward signals derived from VerIF, which computes the final reward as an average of scores from code validation and LLM verification.
Experimental Analysis and Results
VerIF's efficacy was tested on multiple benchmarks, including IFEval, Multi-IF, and SysBench, showcasing substantial gains. The models trained with VerIF achieved state-of-the-art performance in instruction adherence tasks, evidencing their superior constraint satisfaction outcomes compared to alternatives like TULU 3 or DeepSeek-R1-Distill-Qwen-7B.
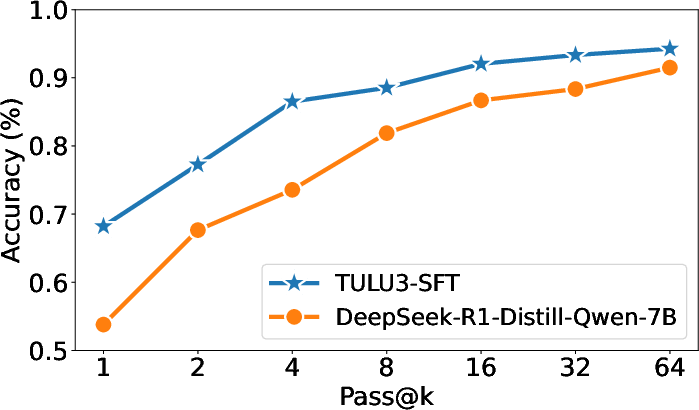
Figure 2: Pass@k results (\%) of two SFT-trained LLMs on IFEval. We report the prompt-level strict score.
This improvement highlights the robust performance enhancements over models of comparable scales, reinforcing VerIF's viability as a general-purpose RL training enhancement.
Generalization and Capabilities Preservation
Notably, models trained with VerIF exhibited excellent generalization across previously unseen instruction types and other tasks like mathematical reasoning and NLU benchmarks. Results indicate no degradation of general capabilities, suggesting that reinforcement learning with VerIF can be seamlessly integrated into existing training pipelines without negative impacts on other skill sets.
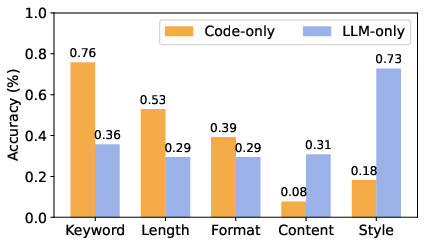
Figure 3: Accuracy (\%) of code-only or LLM-only verification in verifying compliance with different types of constraints. LLM-only adopts QwQ-32B.
Verification Methodology: Code vs. LLM-Based
The explorative phase involved verifying methodology preferences through IFBench. Code+LLM verification emerged superior in accommodating both hard and soft constraints, substantiating the co-dependence of code and LLM in achieving comprehensive verification accuracy (Figure 4).
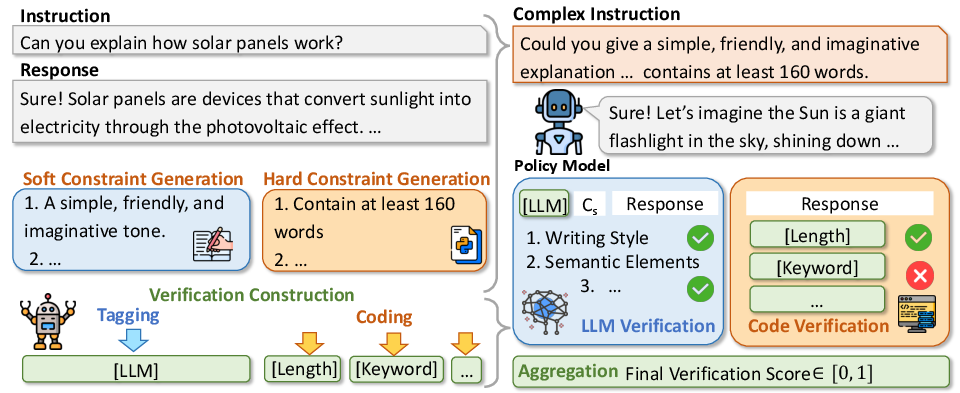
Figure 4: Left: The construction process for VerInstruct, including complex instruction generation and verification construction. Right: Our verification method, VerIF, providing verification for instruction following.
Future Directions and Concluding Remarks
The findings underscore the potential of RL augmented by verification engineering to revolutionize instruction-following LLMs. The work encourages further investigation into dataset diversity and scalable verifier models to enhance multi-lingual and cross-domain applicability. VerIF serves as an instrumental methodology, with VerInstruct facilitating exploration into less charted territories of reinforcement learning in LLM instruction-following scenarios.
In conclusion, VerIF showcases a significant advance in refining RL techniques with verifiable outcomes, heralding future directions for more sophisticated and reliable AI systems in diverse instructional contexts.