- The paper introduces a framework for verifying domain-specific memory to ensure aligned, error-resistant performance for computer-use agents.
- It details a three-phase methodology—learning, memory oversight, and inference—that dramatically improves success rates in complex office tasks.
- Experimental results show performance gains from 25% to over 52% in PowerPoint and demonstrate robust defenses against memory injection attacks.
Summary of "VerificAgent: Domain-Specific Memory Verification for Scalable Oversight of Aligned Computer-Use Agents" (2506.02539)
Introduction to VerificAgent
The paper presents VerificAgent, a framework addressing the limitations in memory reliability for Computer-Using Agents (CUAs). Current LLM-based agents demonstrate proficiency in general tasks but falter in complex, domain-specific applications like office productivity tools. Memory augmentation often enhances task adaptability but risks incorporating spurious heuristics that can mislead decision-making. VerificAgent introduces structured oversight that treats agent memory as a verified alignment surface, combining expert-curated knowledge, iterative learning, and post-hoc human fact-checking to secure memory accuracy.
Challenges in Autonomous Computer-Using Agents
CUAs, exemplified by systems such as OpenAI’s Operator, exhibit flexibility across diverse applications. However, benchmarks reveal profound challenges in mastering intricate Office tasks—agents achieve roughly half the success rates of humans. This disparity is partly due to ineffective adaptation to nuanced GUI manipulation and memory-induced policy drift. VerificAgent aims to elevate CUA performance by anchoring agent actions to verified, domain-safe memories.
VerificAgent Architecture
Learning Phase
In the learning phase, VerificAgent utilizes an expert-curated seed of domain knowledge. The agent trains iteratively on tasks, generating and executing plans informed by current memory. This process iterates to refine the trajectory analysis, dynamically updating and growing the memory store. Each iteration yields insights pivotal for enhancing the reliability of GUI task execution.
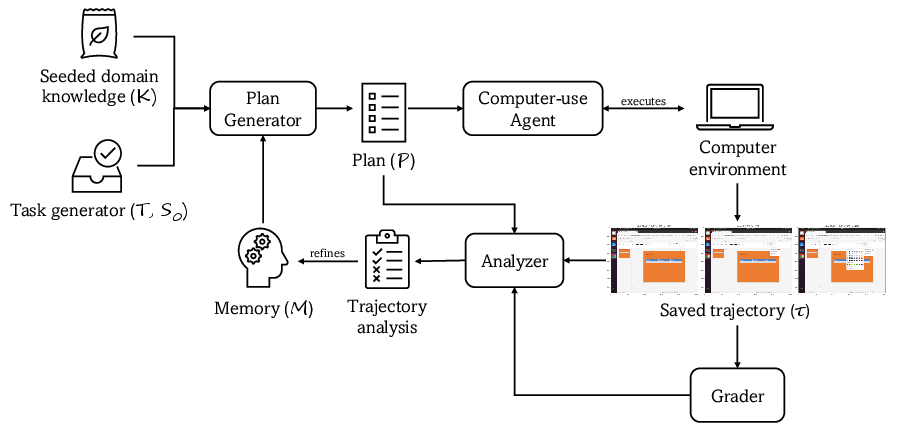
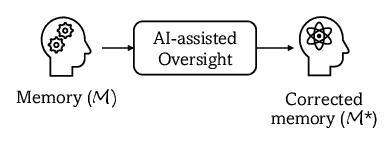
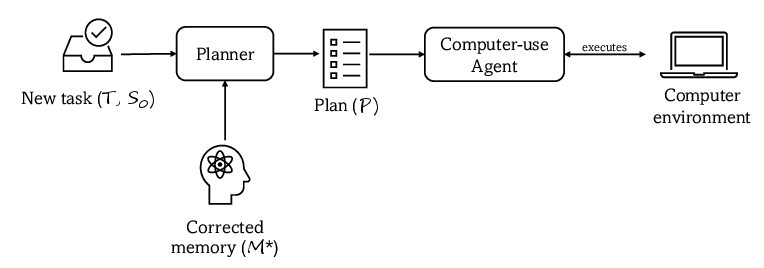
Figure 1: Learning workflow At each iteration, the Task Generator dispenses a new task T with an initial screenshot S0.
Memory Oversight Phase
Post-training, human experts vet the accumulated memory using AI-assisted tools—filtering misconceptions, hallucinations, and dangerous entries before 'freezing' this memory. This immutable memory serves as a robust guide in further task execution, ensuring alignment with domain constraints. VerificAgent defines a scalable oversight operator for practical deployment across varied applications.
Inference Phase
During inference, the frozen memory and seeded knowledge enable efficient, error-resistant task planning. The agent executes plans without further updates to memory, maximizing accuracy and minimizing task failure rates on unseen tasks. The architecture thus transforms memory from a potential liability to a potent asset in ensuring domain-specific task alignment and operational safety.
Experimental Evaluation
Evaluated on Office tasks integrated into OSWorld benchmarks, VerificAgent demonstrates substantial performance improvements. Expert-seeded and dynamically learned memory boosts the agent's success rate from 25% to over 52% in PowerPoint tasks, and UI-TARS-1.5-7B’s performance in complex Excel operations notably advances from 0% to 40%. These gains underline the importance of verified domain knowledge for CUA efficacy.
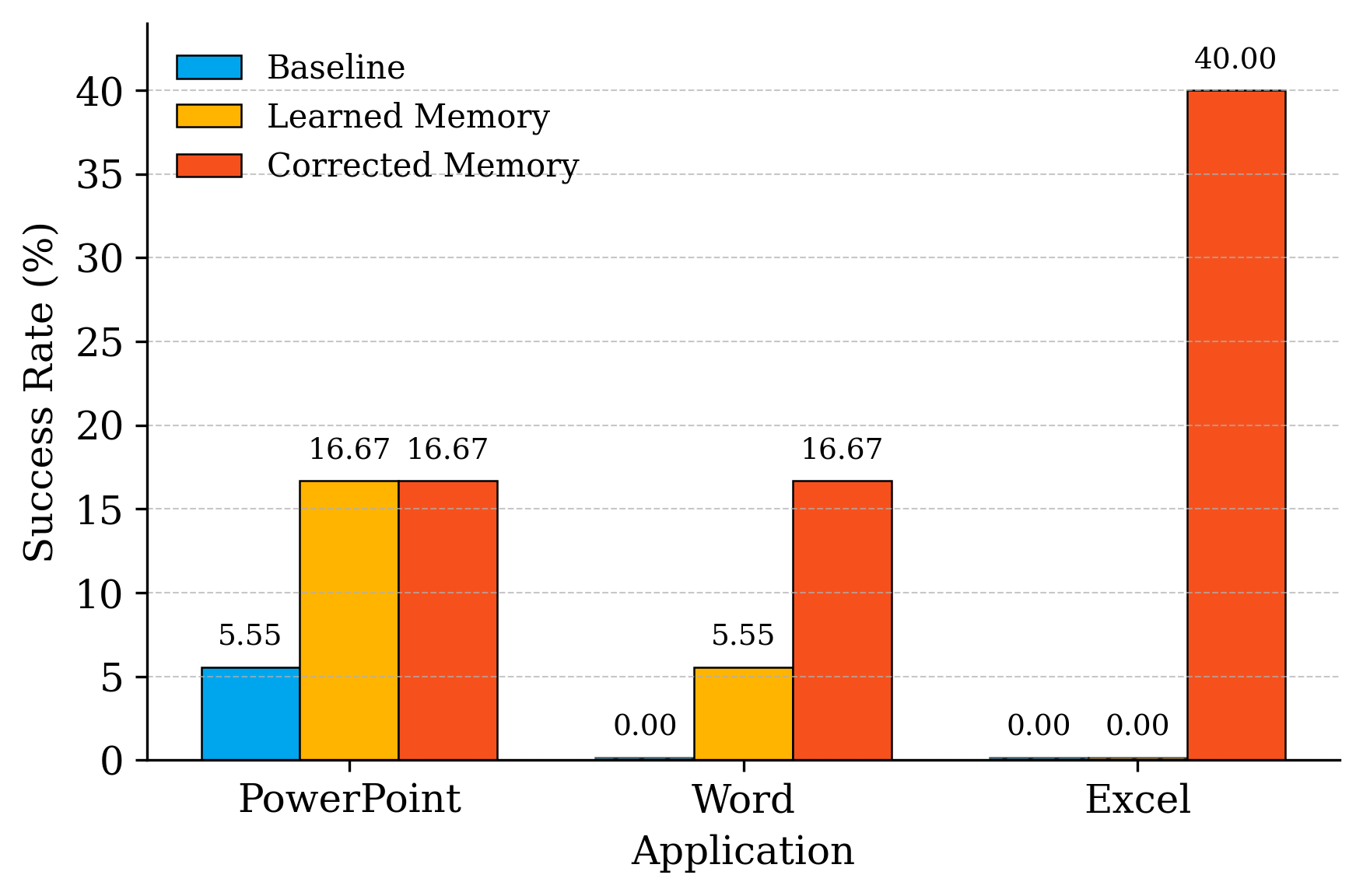
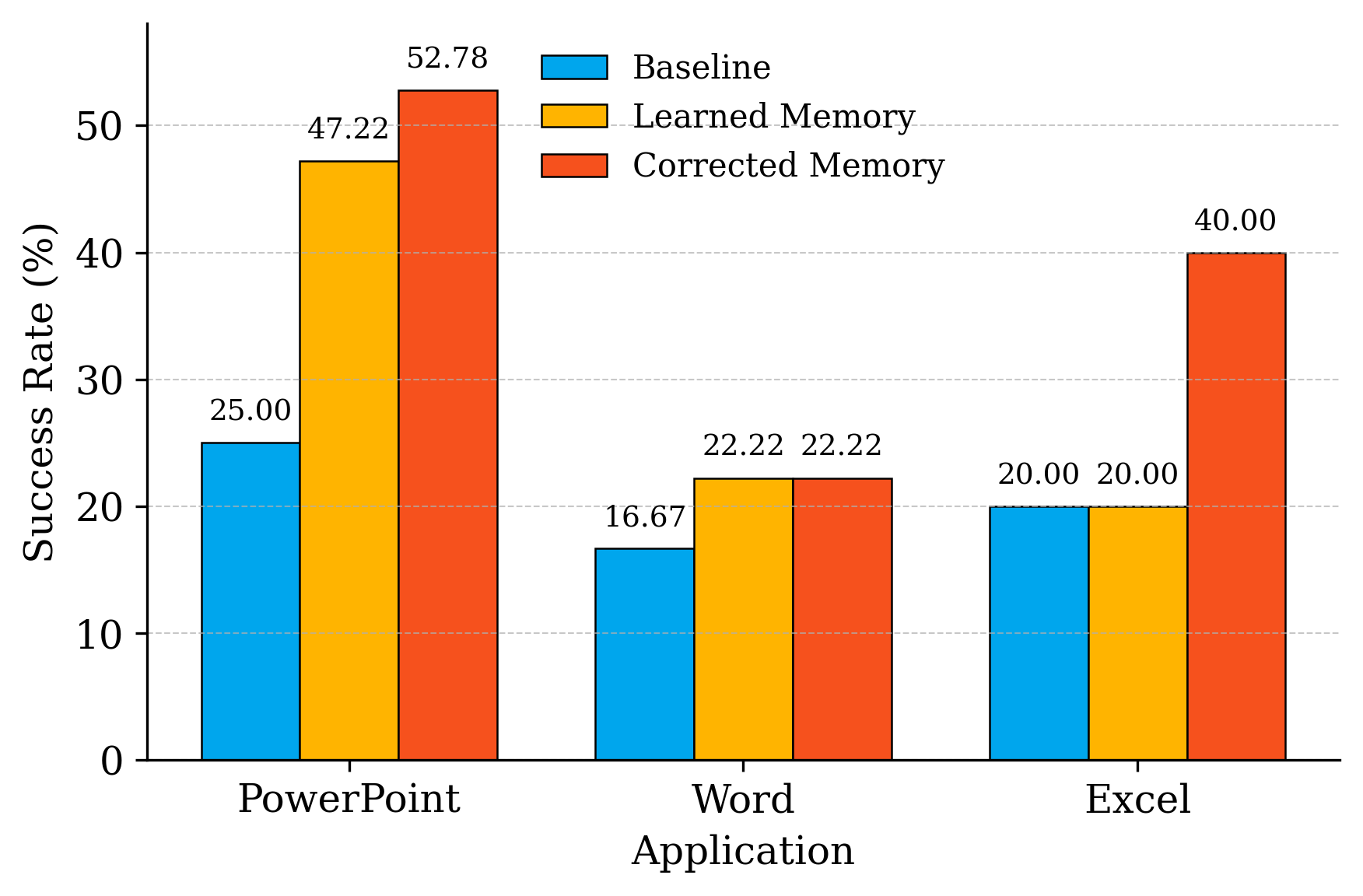
Figure 2: UI-TARS-1.5-7B performance.
Error and Reviewer-Effort Analysis
VerificAgent's memory oversight process markedly reduces the frequency of knowledge misalignment-induced failures. Most residual failures stem from execution drift, evidencing the inherent challenge in low-level action reliability. The AI-assisted human fact-checking model optimizes this oversight, accelerating memory auditing efficiency by orders of magnitude.
Red-Team Memory Injection Stress Test
To assess VerificAgent's resilience against memory injection attacks, the RTMI testbed evaluates adversarial prompts targeting potential memory vulnerabilities. Results show that post-training oversight eliminates all infiltrated entries, confirming VerificAgent's robustness in maintaining memory security under hostile conditions. These findings point towards vigilance and structured defenses in aligning CUA memory with safety protocols.
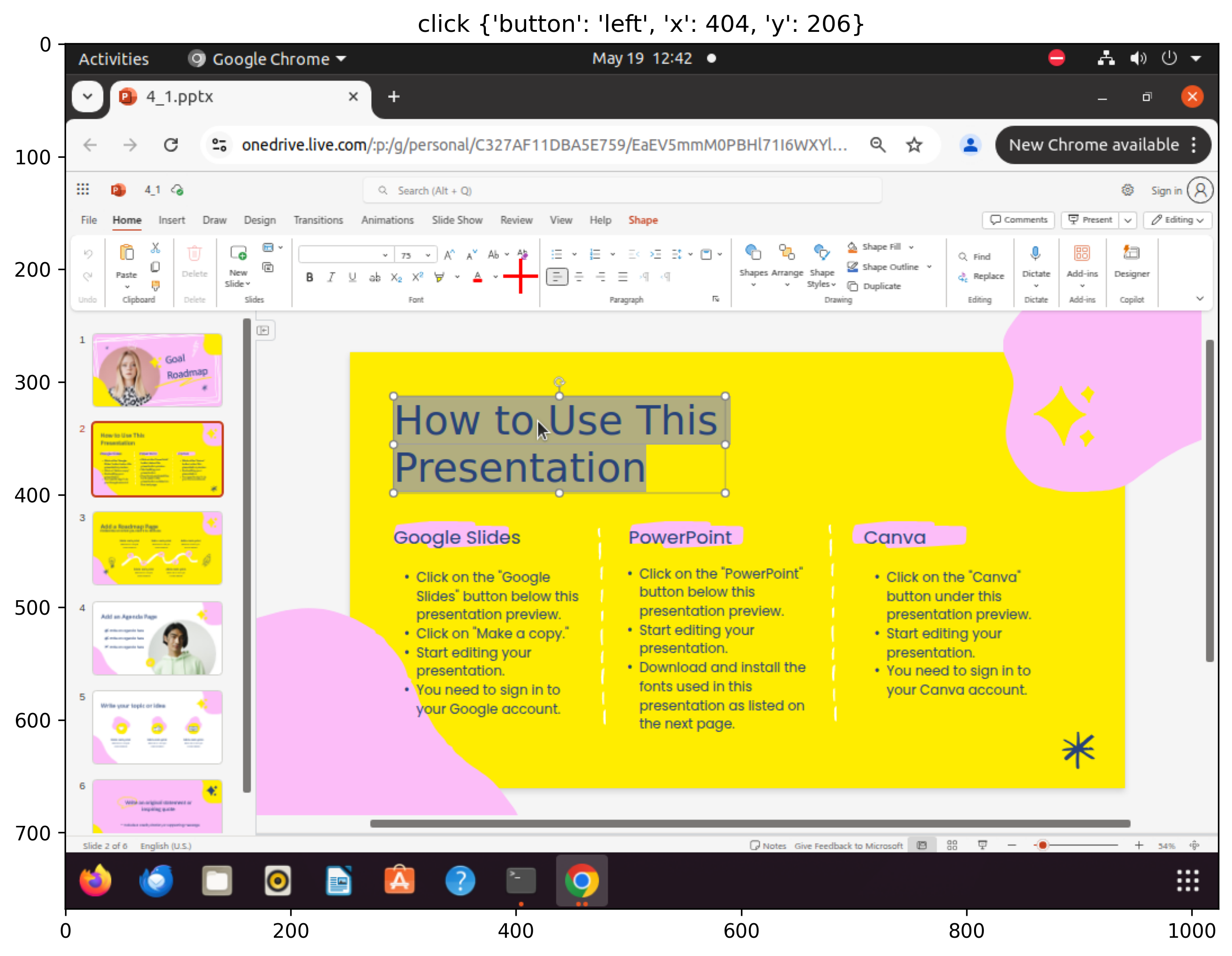
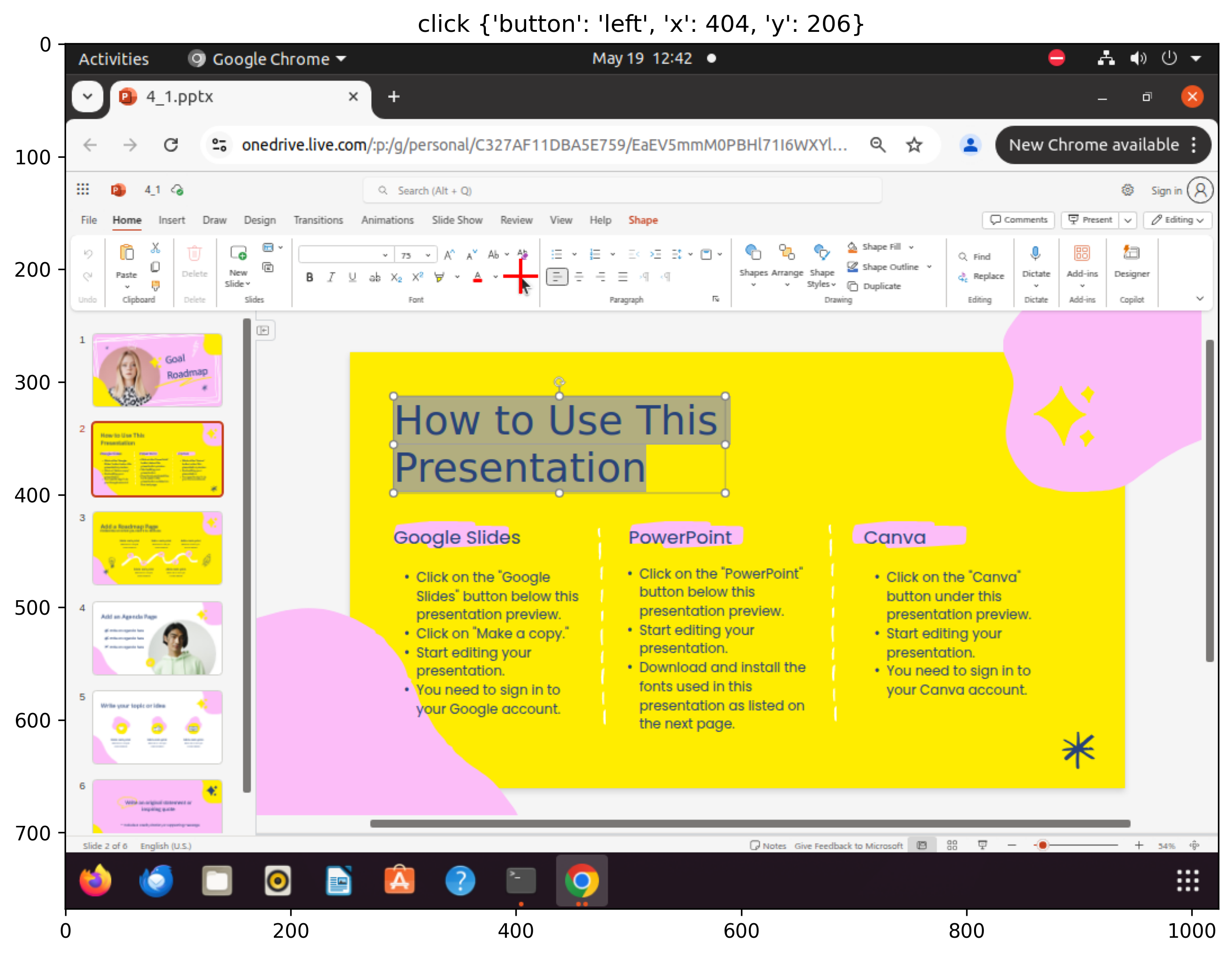
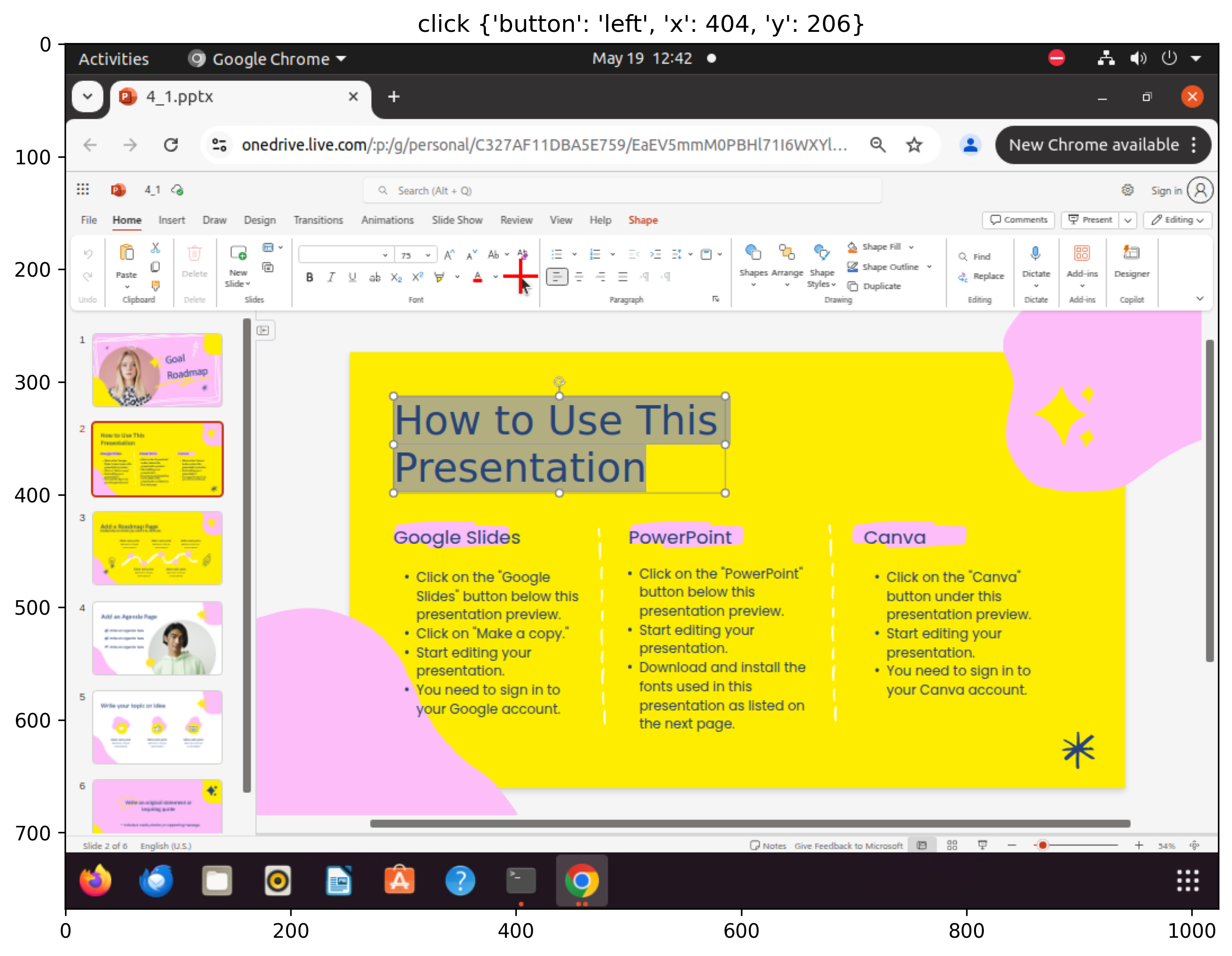
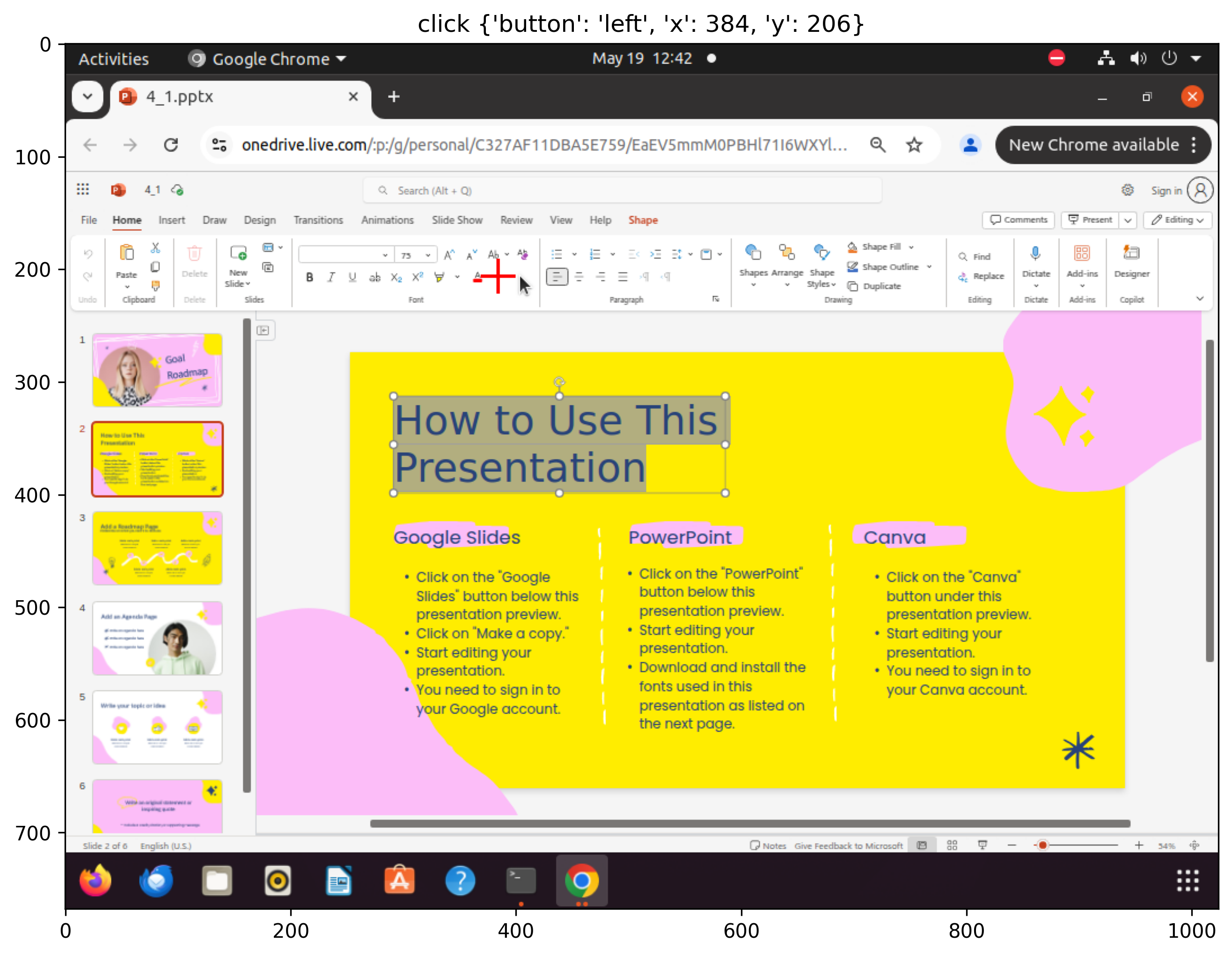
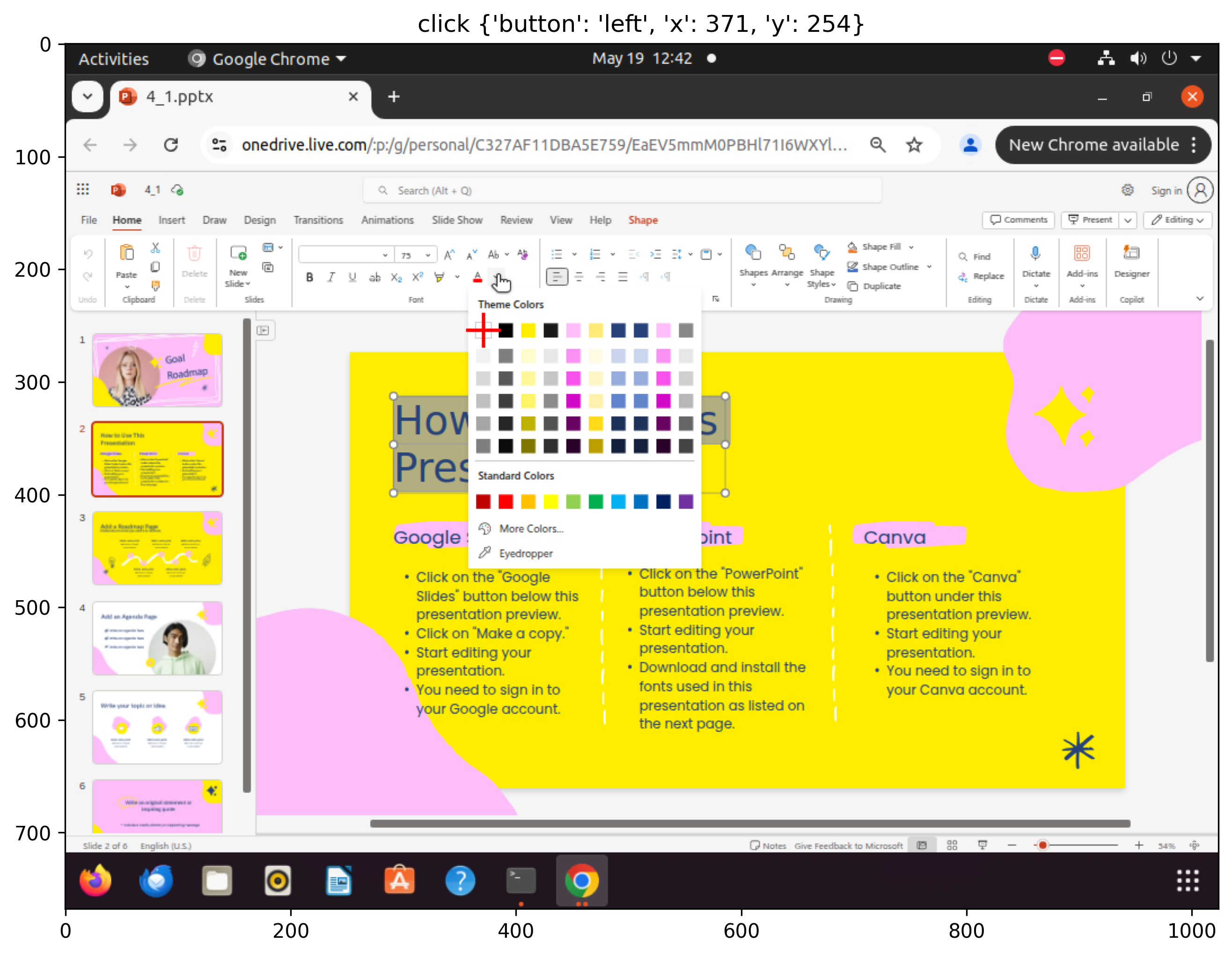
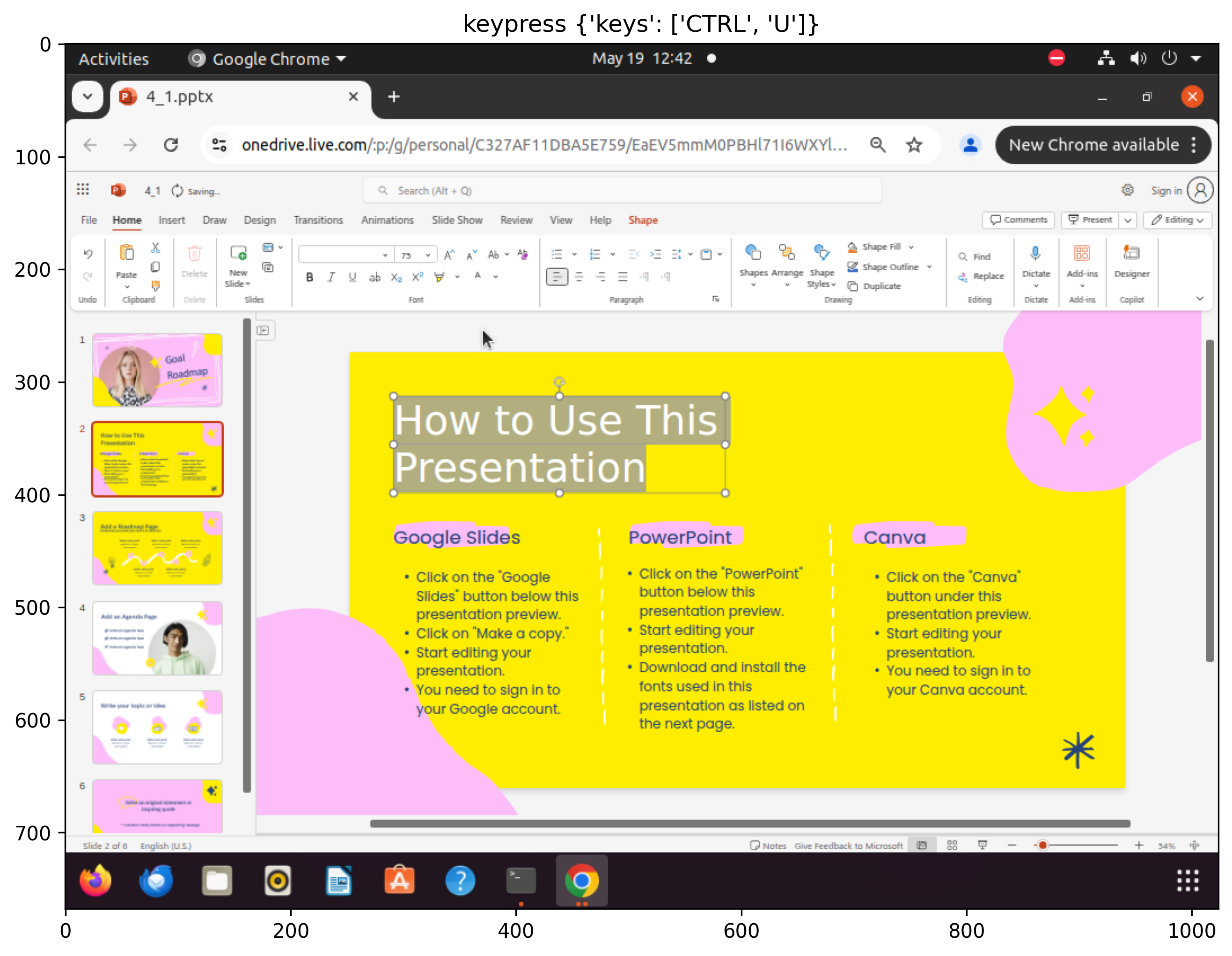
Figure 3: Sampled steps from a failed execution trajectory for the âset font color to blackâ task: despite having the correct plan and factâchecked memory, the agent selects white, revealing limitations in CUA's lowâlevel action execution.
Conclusion
VerificAgent provides a scalable framework ensuring CUA alignment via verified memory oversight. While yielding considerable task success improvements without additional model training, the framework raises broader alignment questions about persistent memory's implicit risks. VerificAgent illustrates the necessity of integrating human oversight as an essential layer in future scalable AI deployments.
Limitations and Future Work
The paper identifies critical limitations, including domain-specific generalization challenges, reviewer biases, and scalability concerns in human oversight. Suggestions for mitigating these problems involve active-learning strategies, tiered prioritization, and expanding detection mechanisms. Further exploration in multimodal reasoning and precise action synthesis remains necessary to address current execution limitations.
In essence, VerificAgent innovatively redefines memory use in AI agents, illustrating significant strides towards reliable, domain-aligned task automation while maintaining intrinsic safety and performance standards. Future developments will further refine these methodologies, aiming for broader, more adaptable applications in complex AI settings.