How Far Are We from Generating Missing Modalities with Foundation Models?
Abstract: Multimodal foundation models have demonstrated impressive capabilities across diverse tasks. However, their potential as plug-and-play solutions for missing modality reconstruction remains underexplored. To bridge this gap, we identify and formalize three potential paradigms for missing modality reconstruction, and perform a comprehensive evaluation across these paradigms, covering 42 model variants in terms of reconstruction accuracy and adaptability to downstream tasks. Our analysis reveals that current foundation models often fall short in two critical aspects: (i) fine-grained semantic extraction from the available modalities, and (ii) robust validation of generated modalities. These limitations lead to suboptimal and, at times, misaligned generations. To address these challenges, we propose an agentic framework tailored for missing modality reconstruction. This framework dynamically formulates modality-aware mining strategies based on the input context, facilitating the extraction of richer and more discriminative semantic features. In addition, we introduce a self-refinement mechanism, which iteratively verifies and enhances the quality of generated modalities through internal feedback. Experimental results show that our method reduces FID for missing image reconstruction by at least 14\% and MER for missing text reconstruction by at least 10\% compared to baselines. Code are released at: https://github.com/Guanzhou-Ke/AFM2.
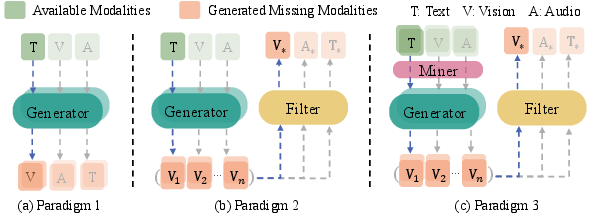

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now using the paper’s training-free paradigms and the proposed AFM² framework (miner–verifier–generator with self-refinement). Each item lists sectors, a plausible tool/workflow, and feasibility assumptions.
- Data completion and augmentation for ML pipelines
- Sectors: software, computer vision, NLP, speech
- What: Backfill missing images and captions in multimodal datasets; generate multiple candidates and select via MLLM-as-a-Judge; use reconstructed modalities to train classifiers, retrieval models, or captioners.
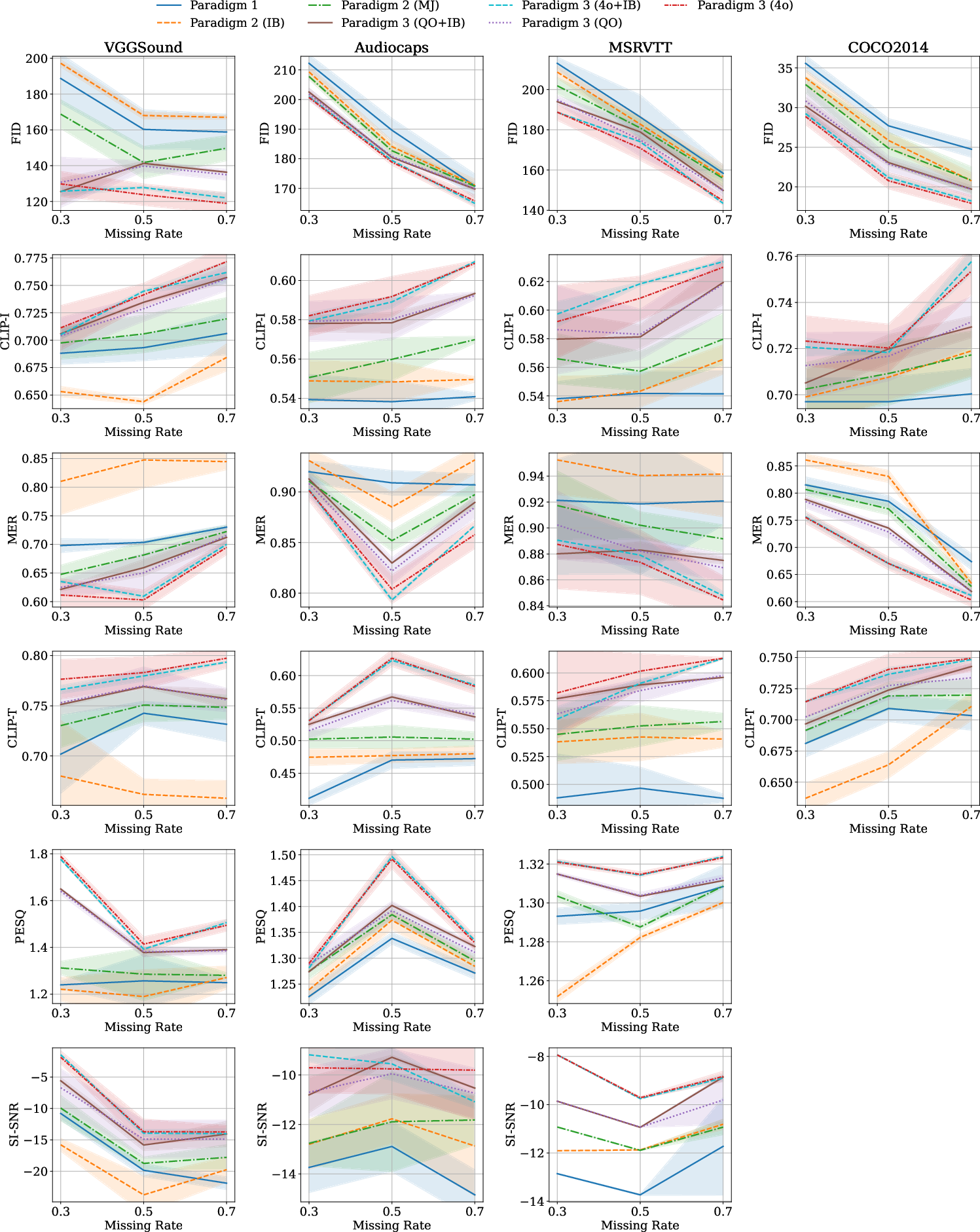
- Tools/workflows: AFM² with Qwen2.5-Omni miner/verifier, SD/FLUX for images, Qwen LLMs for text; set a verifier threshold (e.g., 4.0–4.5) and 5–15 candidates with self-refinement to control compute; CLIP-I/CLIP-T quality gates.
- Assumptions/dependencies: Access to GPU or efficient API; acceptable domain shift; human spot checks for critical datasets; audio reconstruction remains weak (low SI-SNR).
- Accessibility enrichment (alt-text and audio descriptions)
- Sectors: education, public sector, media, web platforms
- What: Generate alt-text for images and audio descriptions for short clips; enhance captions for COCO-like short texts with mined object/location details to reduce hallucinations.
- Tools/workflows: Miner extracts objects/locations/colors; LLM generator drafts text; MJ filter validates; integrate as a CMS plugin or batch pipeline.
- Assumptions/dependencies: Non-safety-critical usage; disclosure of synthetic content; ensure verifier thresholds are tuned to avoid misleading descriptions.
- E-commerce catalog repair and enrichment
- Sectors: retail, recommendation systems, search
- What: Fill missing product images from text and vice versa; refine sparse titles into SEO-rich descriptions; generate multiple candidates and select the best via semantic filter.
- Tools/workflows: AFM² microservice; batch nightly jobs; ImageBind/MJ scoring for alignment with existing catalog metadata.
- Assumptions/dependencies: Brand/style consistency checks; human-in-the-loop for high-value SKUs; rights management for generative images.
- Video and creative post-production utilities
- Sectors: media, entertainment, marketing
- What: Restore or synthesize missing stills (thumbnails, posters) from scripts/shot lists; generate draft captions/subtitles; add basic sound effects from textual cues when the audio track is damaged.
- Tools/workflows: Editor plugins calling AFM²; generate 5–15 candidates; miner adds fine-grained cues (actions, settings); verifier ranks for coherence.
- Assumptions/dependencies: Audio synthesis remains limited; creative approval needed; watermark synthetic assets.
- Robust model training under missing data
- Sectors: software, research labs
- What: Train downstream classifiers on datasets with missing modalities by reconstructing them first; the paper shows classification can approach full-data baselines when using Paradigm 3/AFM².
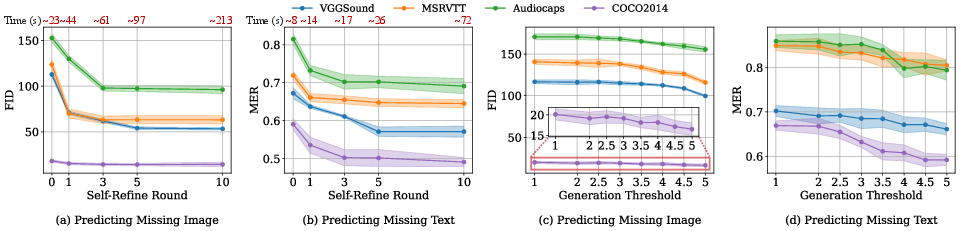
- Tools/workflows: Pre-training data completion step; use ImageBind encoders + MLP head; track F1/AP vs. missing rates; adopt self-refinement for better time–quality trade-offs.
- Assumptions/dependencies: Domain match to foundation models; careful metric monitoring to avoid overfitting to generated artifacts.
- Dataset triage and QA for multimodal corpora
- Sectors: academia, MLOps
- What: Use miner and verifier as “judges” to detect misaligned samples and filter or repair them; regenerate short captions into richer, consistent descriptions.
- Tools/workflows: MJ/Qwen-as-a-Judge; re-caption weak samples; create QA dashboards (FID/CLIP/MER) before release.
- Assumptions/dependencies: Judge bias; maintain audit logs of modified samples; governance over dataset changes.
- Lightweight robotics and IoT data repair (non-safety-critical)
- Sectors: robotics, IoT, warehousing
- What: When a sensor stream (e.g., text annotations, images for logging) is missing, generate proxy modalities to keep analytics dashboards and non-critical perception routines running.
- Tools/workflows: AFM² service in the data pipeline; miner extracts object/action cues from remaining streams; verifier enforces confidence thresholds.
- Assumptions/dependencies: Not for real-time control or safety; strict thresholds; fallback to “do-not-impute” if quality is low.
- Digital preservation and personal media utilities
- Sectors: daily life, cultural heritage
- What: Generate missing captions for photo archives; approximate ambient audio for silent clips; enrich metadata for searchability.
- Tools/workflows: Consumer apps with on-device Qwen-based miner/verifier and diffusion models; batch processing with logs of generated content.
- Assumptions/dependencies: User consent and disclosure; audio quality is approximate; local compute or privacy-preserving APIs.
- Privacy-preserving sharing via synthetic stand-ins
- Sectors: enterprise data sharing, healthcare research (preclinical), public datasets
- What: Replace sensitive modalities (e.g., raw images or audio) with semantically aligned synthetic proxies, enabling external collaboration without exposing raw data.
- Tools/workflows: AFM² with strong verifier thresholds; watermarking; documentation of synthetic substitution.
- Assumptions/dependencies: Not for diagnosis/forensics; utility–privacy trade-offs; legal review of synthetic data use.
- Research baselines and benchmarks for missing modality reconstruction
- Sectors: academia
- What: Use the paper’s 42-variant paradigms and AFM² code as reproducible baselines; study miner granularity and candidate scaling.
- Tools/workflows: Public codebase; evaluation with FID/CLIP-I, MER/CLIP-T, PESQ/SI-SNR; ablations on thresholds and rounds.
- Assumptions/dependencies: Availability of GPT-4o or open alternatives; standardized datasets and splits.
Long-Term Applications
These use cases are promising but require further research, domain adaptation, reliability guarantees, or regulatory clearance before deployment.
- Clinical modality reconstruction and decision support
- Sectors: healthcare
- What: Reconstruct missing imaging sequences (e.g., MRI contrasts), radiology report text from images, or auscultation-like audio proxies for training and workflow continuity.
- Tools/products: PACS-integrated AFM² “suggested reconstruction” panel; clinician-in-the-loop; provenance and confidence scoring; strict verifier thresholds and calibration.
- Assumptions/dependencies: Regulatory approval, rigorous clinical trials, bias and failure-mode analysis; improved audio grounding; watermarked synthetic outputs and clear disclosure.
- Safety-critical autonomy under sensor dropout
- Sectors: autonomous driving, industrial robotics, aviation
- What: Generate proxy modalities (e.g., images from text cues or other sensors) to maintain situational awareness during transient failures; enhance training via reconstruction-based augmentation in rare scenarios.
- Tools/products: ROS 2 middleware with AFM² agent; real-time bounded self-refinement; formal verification and simulation-in-the-loop evaluation.
- Assumptions/dependencies: Deterministic latency, certification, robust OOD handling; may favor “do-not-impute” unless confidence is high.
- Grid and industrial monitoring with cross-modal imputation
- Sectors: energy, manufacturing
- What: Fill gaps in multimodal telemetry (acoustic, thermal, visual) for predictive maintenance and anomaly triage; generate descriptive incident narratives from sparse signals.
- Tools/products: Edge–cloud AFM² services; domain-specific miner rules (equipment types, locations); verifier tuned to anomalies.
- Assumptions/dependencies: Domain adaptation and robust calibration; ground-truth validation; cyber-security and safety policies.
- Education: automatic tri-modal course capture and remediation
- Sectors: education/EdTech
- What: When a modality is missing (e.g., audio track or lecture notes), reconstruct it from slides and partial transcripts; create accessible variants.
- Tools/products: LMS integration; AFM²-based content repair assistant; batch QA with human instructors reviewing low-confidence cases.
- Assumptions/dependencies: Better long-form audio/text grounding; academic integrity and disclosure policies.
- Secure on-device modality repair assistants
- Sectors: consumer software, mobile, enterprise privacy
- What: Offline AFM² variants using open models (Qwen/FLUX/AudioLDM) for privacy-sensitive data; reconstruct captions/images without leaving device.
- Tools/products: On-device SDK; model distillation and quantization; adaptive candidate scaling.
- Assumptions/dependencies: Efficient local LMMs, hardware acceleration, privacy threat modeling.
- Forensics and investigative reconstruction (advisory-only)
- Sectors: public safety, legal
- What: Hypothesis-generation by reconstructing missing frames or ambient sounds to aid human investigators; never as evidence without corroboration.
- Tools/products: AFM² “what-if” workstation; audit logs; watermarking; uncertainty reports.
- Assumptions/dependencies: Strict policy controls; risk of hallucination; clear evidentiary separation.
- Synthetic de-identification frameworks with utility guarantees
- Sectors: policy, enterprise governance, healthcare research
- What: Replace sensitive modalities with verified synthetic analogs while preserving downstream task performance; publish with transparency reports.
- Tools/products: Verifier-calibrated risk/utility dashboards; standardized disclosure artifacts; governance APIs.
- Assumptions/dependencies: Policy standards for synthetic data disclosure; sector-specific compliance (HIPAA/GDPR).
- Standardization: verification thresholds, auditability, and disclosure norms
- Sectors: policy, standards bodies, platform governance
- What: Define industry guidelines for using MLLM-as-a-Judge, setting acceptance thresholds, reporting metrics (FID/MER/PESQ), logging self-refinement, and watermarking.
- Tools/products: Compliance checklists; reference test suites; public leaderboards for missing-modality benchmarks.
- Assumptions/dependencies: Multistakeholder consensus; evolving metrics for audio and safety-critical domains.
- Next-gen audio reconstruction and grounding
- Sectors: audio tech, accessibility, AR/VR
- What: Close the audio gap with better audio miners/generators and cross-modal grounding (beyond text-only prompts) for realistic environmental and speech audio synthesis.
- Tools/products: New audio foundation models; improved evaluation metrics beyond PESQ/SI-SNR; multi-sensor context mining.
- Assumptions/dependencies: Research advances and large, diverse training corpora; ethical sourcing of audio data.
- Platform products for enterprise “Modality Repair”
- Sectors: software/SaaS
- What: “AFM² Studio” and “Modality Proxy API” to repair, enrich, or synthesize missing modalities across departments (analytics, marketing, R&D).
- Tools/products: Orchestrated miner–verifier–generator pipelines; cost controls via self-refinement; admin dashboards for policy and QA.
- Assumptions/dependencies: API and model licensing (e.g., GPT-4o) or robust open-source substitutes; MLOps integration and monitoring.
Notes on feasibility across applications
- Strong dependency on the miner and verifier: The paper shows these are the primary drivers of quality and semantic alignment; audio remains the weakest modality and requires additional R&D.
- Compute and latency trade-offs: More candidates improve quality; self-refinement reduces brute-force scaling but still needs tuning for cost/latency targets.
- Human-in-the-loop: Recommended for safety-critical or brand-sensitive contexts; adopt conservative verifier thresholds and explicit disclosure/watermarking.
- Legal/ethical considerations: IP rights for generated assets, privacy of source data, and honest signaling of synthetic content are essential for adoption.
Collections
Sign up for free to add this paper to one or more collections.