- The paper introduces a robust dataset integrating four distinct modalities with bilingual market coverage to enhance financial forecasting.
- It details comprehensive data construction and preprocessing, including image conversion, text summarization, and temporal data alignment.
- Experiments demonstrate that multimodal fusion using models like FTS-Text-MoE significantly reduces prediction errors in stock price forecasts.
Overview and Contribution
"FinMultiTime: A Four-Modal Bilingual Dataset for Financial Time-Series Analysis" introduces the FinMultiTime dataset, a large-scale, cross-market dataset designed for financial time-series analysis. It uniquely integrates four distinct modalities—financial news, structured financial tables, K-line technical charts, and stock price time series—across both the S&P 500 and HS 300 stock indices. The temporal alignment across modalities, coupled with the bilingual nature of the dataset, presents a robust framework for enhancing financial predictive models through multimodal learning.
Dataset Construction
The FinMultiTime dataset intricately compiles data from major financial markets. It begins with sourcing minute-level, daily, and quarterly data covering a period from 2009 to 2025. For the U.S. market, data includes S&P 500 constituent stocks retrieved through Yahoo Finance API for OHLCV data and news sentiment extracted from headlines and articles using a robust pipeline derived from existing open-source scripts. Chinese market data utilizes similar sources, including Tushare API for numerical data and multiple media platforms for news.
Figure 1: Data Collection Pipeline for the Bilingual Four-Modal FinMultiTime Dataset.
Technical Processing
Financial modalities are carefully preprocessed—charts are converted to grayscale images, news articles are summarized using LSA, and structured tables are parsed for key financial indicators. The synchronization of data is crucial, ensuring financial tables and price series reflect consistent temporal periods with aligned end-of-period data.
Experimentation and Analysis
The dataset's utility is validated through rigorous experiments using a diverse array of models. Unimodal and multimodal data impact is measured across different machine learning models such as CNN, RNN, LSTM, GRU, and advanced networks like TimeNet. Results highlight the substantial gains in performance when integrating multimodal data onto traditional time-series models, exemplified by significant reductions in prediction error rates.
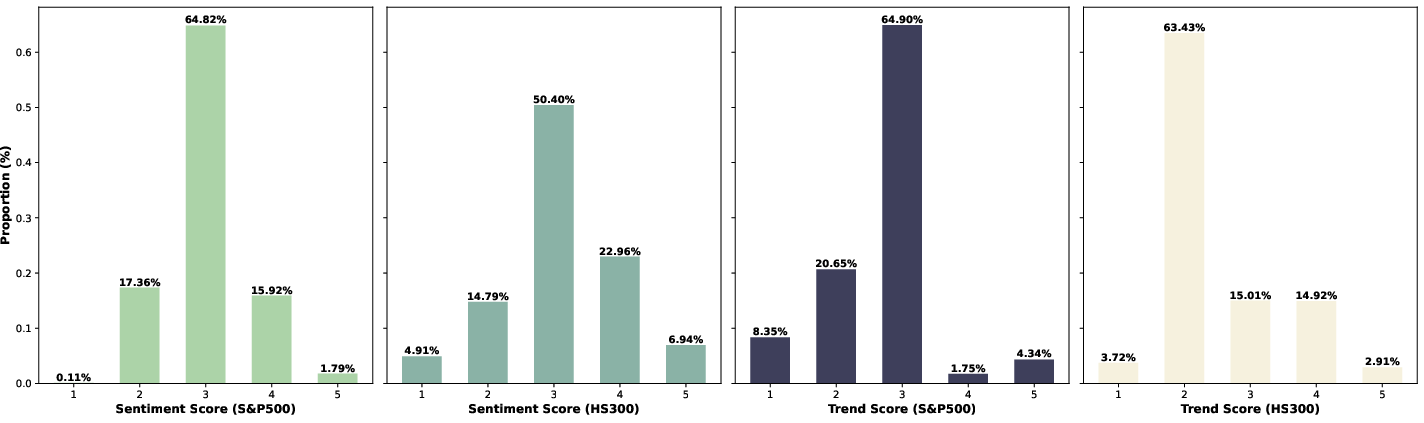
Figure 2: Figures (a) and (b) show the proportions of LSA-generated news sentiment scores (1 = negative, 5 = positive) for S&P 500 and HS300 stocks, respectively; Figures (c) and (d) display the corresponding six-month candlestick-chart trend scores.
Overall, experiments affirm that larger datasets aid in predictive accuracy, with multimodal fusion proving especially effective. Moreover, the Choice of models such as the FTS-Text-MoE outperforms others in integrating text and time-series data, offering more precise short-term predictions.
Implications and Applications
The development of FinMultiTime represents a significant tool for advancing AI-driven financial forecasting, capitalizing on the comprehensive nature of its multimodal information. The dataset is invaluable for training robust multimodal models that assimilate diverse financial signals at scale, thus enhancing understanding of stock price dynamics and improving predictive capabilities.
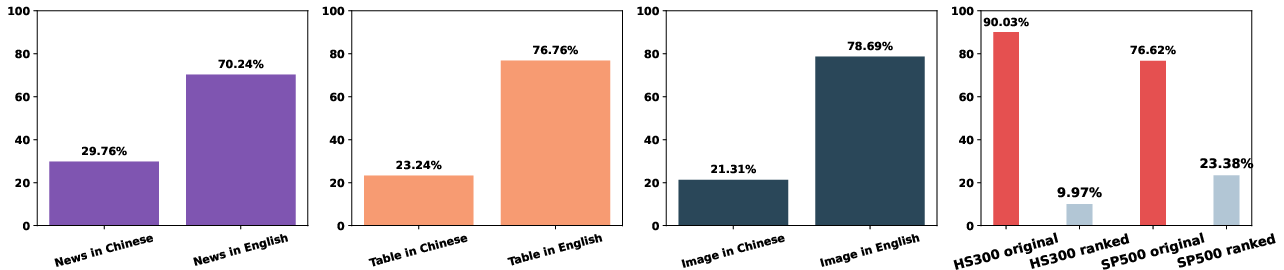
Figure 3: Proportions of Chinese vs. English Modalities (News, Tables, Images). Coverage ratios of ranked vs. original daily news for HS300 and S&P 500.
Conclusion
FinMultiTime sets a new standard in financial datasets by providing a versatile, multimodal, and bilingual corpus. It not only advances financial forecasting technology but also sets a foundational benchmark for future developments in multimodal neural networks and financial modeling. Through its robust design and comprehensive data structure, FinMultiTime illuminates new pathways for research and investment strategies in finance.