- The paper's main contribution is Delta, a two-stage framework that integrates value-based plan generation with cost-based selection to achieve superior query performance (up to 2.34× speedup).
- The framework employs a Mahalanobis distance-based compatible query detector to filter out out-of-distribution queries, ensuring robust and efficient optimization.
- Experimental results show reduced training time (66.6% of VBOs) and enhanced plan quality through data augmentation, heteroscedastic loss, and beam search.
Delta: A Learned Mixed Cost-based Query Optimization Framework
Introduction and Motivation
Delta introduces a mixed cost-based query optimization framework that addresses the limitations of both cost-based optimizers (CBOs) and value-based optimizers (VBOs) in database management systems (DBMSs). Traditional CBOs rely on dynamic programming and cost models, but suffer from search space explosion and heuristic pruning, often leading to suboptimal plans. VBOs, leveraging reinforcement learning and value networks, enable efficient exploration but incur high training costs and lower accuracy, especially for final plan selection. Delta proposes a two-stage planner, augmented by a Mahalanobis distance-based compatible query detector, to combine the strengths of both paradigms and mitigate their weaknesses.
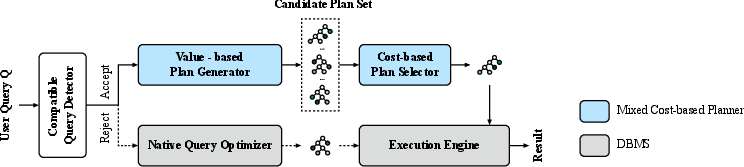
Figure 1: The architecture and workflow of Delta, illustrating the integration of the compatible query detector and the two-stage mixed cost-based planner.
Framework Architecture
Delta's architecture consists of two main components:
- Compatible Query Detector (CQD): Utilizes Mahalanobis distance to filter out queries that are out-of-distribution relative to the training workload, ensuring the planner only operates on queries where its models are reliable.
- Two-stage Mixed Cost-based Planner:
- Stage 1: Value-based plan generator employs a value network and beam search to generate a top-k candidate plan set, relaxing the precision requirements compared to VBOs that select only the top-1 plan.
- Stage 2: Cost-based plan selector uses a learned cost model to rank and select the optimal plan from the candidate set, leveraging the cost model's superior accuracy for complete plan evaluation.
This design enables Delta to efficiently explore the plan space and accurately select high-quality execution plans, while maintaining robustness against distributional shifts in query workloads.
Value-based Plan Generation
Delta extends VBOs such as LOGER and Balsa to generate top-k plans rather than a single top-1 plan. Empirical analysis demonstrates that the best plan is frequently not the top-1 plan according to the value network, but is present within the top-k candidates.
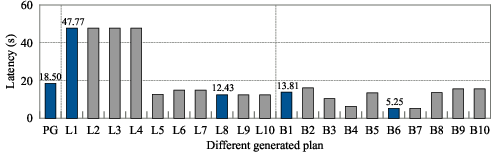
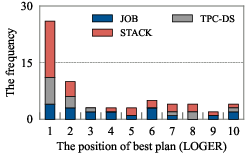
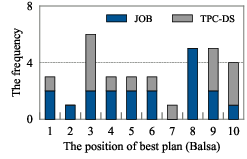
Figure 2: Example and statistics of top-1 vs. top-k plans generated by VBOs, showing that the best plan often appears deeper in the candidate list.
Beam search is employed to efficiently traverse the plan space, guided by the value network's estimates of overall cost (i.e., the minimal achievable latency among all complete plans containing a given subplan). Theoretical analysis guarantees that the best-case improvement of the top-k set is at least as good as the top-1 plan, and empirical results show substantial gains in plan quality by considering multiple candidates.
Cost-based Plan Selection and Training Efficiency
The cost-based plan selector leverages a learned cost model to rank the candidate plans. The cost model is trained using data collected during the value network's training phase, with extensive data augmentation by extracting subplans and their execution times from executed plans. This approach increases the diversity and quantity of training samples by up to 9× on JOB and 4× on TPC-DS and Stack.
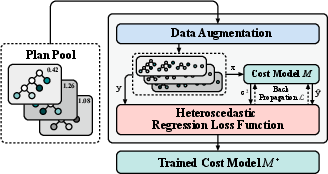
Figure 3: The training of the cost model M, illustrating data reuse and augmentation from the value network's executed plan pool.
To address label noise in plan latency, Delta employs a heteroscedastic regression loss, which models sample-specific noise and improves robustness. The cost model predicts both latency and noise, minimizing the weighted loss to focus on high-quality samples.
Training Cost and Convergence Analysis
Delta's two-stage design reduces the training cost by relaxing the accuracy requirements for the value network and reusing training data for the cost model. Experimental results show that Delta converges with significantly fewer executed plans and lower training time compared to VBOs, while achieving superior plan quality.
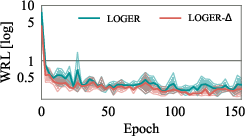
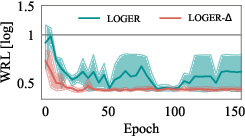
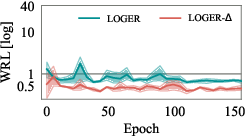
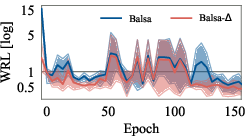
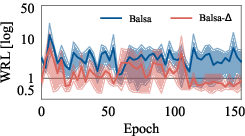
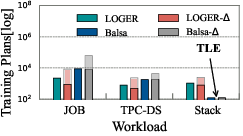
Figure 4: Training curves of Delta and value-based optimizers, showing faster convergence and reduced training plan sizes for Delta.
Candidate Plan Set Quality
Delta's value-based plan generator produces candidate sets with higher best-case improvement, lower worst-case risk, and a greater ratio of high-quality plans compared to cost-based generators. Boxplot analysis across JOB, TPC-DS, and Stack demonstrates that VBOs consistently outperform CBOs in candidate set quality.
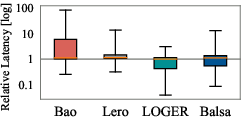
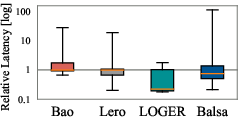
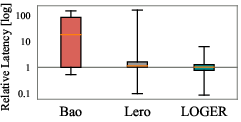
Figure 5: Plan performance distribution of candidate plan sets generated by different planners, highlighting the superior quality of VBO-generated sets.
Optimal Plan Selection: Value vs. Cost Models
Comparative evaluation of plan selection models shows that cost models (naive, learning-to-rank, and enhanced) consistently outperform value networks in selecting the optimal plan from candidate sets. Delta's enhanced cost model, leveraging data augmentation and heteroscedastic loss, achieves the best performance.
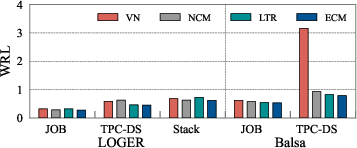
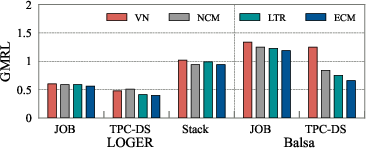
Figure 6: Performance of different models on optimal plan selection from candidates generated by LOGER or Balsa, demonstrating the superiority of cost-based selection.
Compatible Query Detection
The Mahalanobis distance-based CQD effectively filters out incompatible queries, routing them to the native optimizer to prevent performance degradation. Confusion matrix analysis shows 100% recall and up to 80% specificity, ensuring robust operation without negative impact on compatible queries.
Ablation and Parameter Sensitivity
Ablation studies confirm the contribution of each architectural component—CPS, CQD, data augmentation, and heteroscedastic loss—to overall performance. Parameter analysis shows that increasing k improves plan quality with minimal impact on planning time, and tuning γ allows for flexible trade-offs between robustness and optimization coverage.
Experimental Results
Delta achieves an average 2.34× speedup over PostgreSQL and outperforms state-of-the-art learned methods by 2.21× across JOB, TPC-DS, and Stack workloads. It requires only 66.6% of the training time of VBOs while delivering 1.94× higher execution performance. The framework demonstrates stable convergence, robust handling of distributional shifts, and superior plan selection accuracy.
Conclusion
Delta presents a unified mixed cost-based query optimization framework that leverages both value networks and cost models, augmented by a compatible query detector. Its two-stage planner efficiently explores the plan space and accurately selects optimal plans, while data reuse and augmentation minimize training costs. The Mahalanobis distance-based detector ensures robustness against out-of-distribution queries. Delta's empirical results substantiate its effectiveness in modern query optimization, offering a practical and scalable solution for DBMSs. Future work may explore adaptive retraining strategies, integration with federated workloads, and further improvements in model robustness and interpretability.