- The paper introduces a novel inference framework that uses latent steering vectors to enable adaptive reasoning intensity in LLMs.
- It employs a tunable scalar, α, to parameterize the shift in latent states, allowing for dynamically controlled reasoning depth.
- Experimental evaluations on GSM8K, MATH500, and GPQA confirm significant accuracy improvements over conventional inference methods.
Fractional Reasoning via Latent Steering Vectors Improves Inference Time Compute
Introduction
The study introduces Fractional Reasoning, a novel inference-time framework designed to augment LLMs by allowing fine-grained control of reasoning intensity. This method leverages latent vectors to tailor the model's reasoning depth to the complexity of input queries. Existing methods such as Best-of-N and majority voting often lack this adaptability, applying uniform reasoning across diverse inputs.
Fractional Reasoning Framework
The core proposition of Fractional Reasoning lies in its ability to control reasoning intensity via latent steering vectors:
- Latent State Shift: The framework interprets the addition of reasoning-inducing prompts as causing a directional shift in the model's latent state. This shift can be parameterized using a tunable scalar, α, that defines the strength of the reasoning prompt.
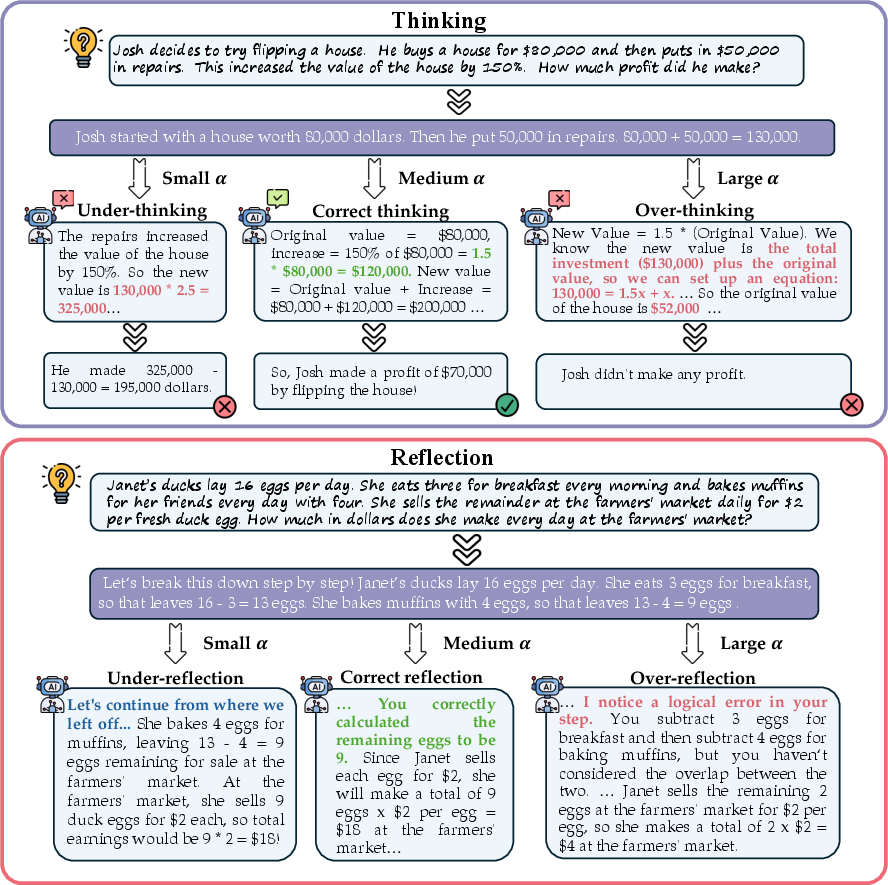
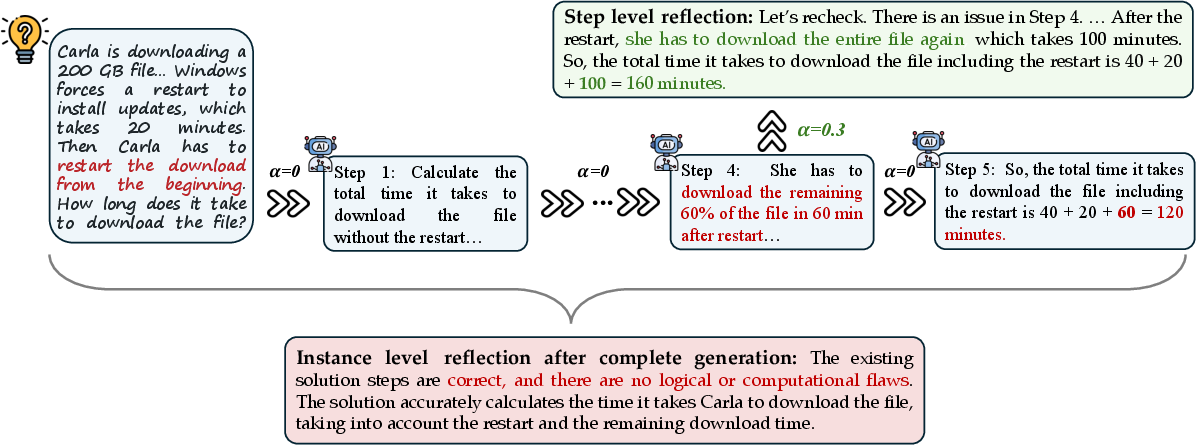
Figure 1: Example illustrating how model behavior changes with the scale of instructional strength α controlling the ``fraction" of reasoning, applied to both Chain-of-Thought and Reflection prompting.
- Steering Vector Construction: Positive and negative prompt pairs are used to extract a latent steering vector, effectively capturing the model's shift in behavior due to reasoning prompts.
- Application: The model's latent states are dynamically modulated at inference time by scaling the steering vector, allowing for adjustable depth in reasoning.
Experimental Evaluation
Extensive experiments across GSM8K, MATH500, and GPQA validate the method's effectiveness:
- Performance Gains: The framework consistently improves accuracy over traditional inference-time compute methods, as demonstrated in multiple benchmarks.
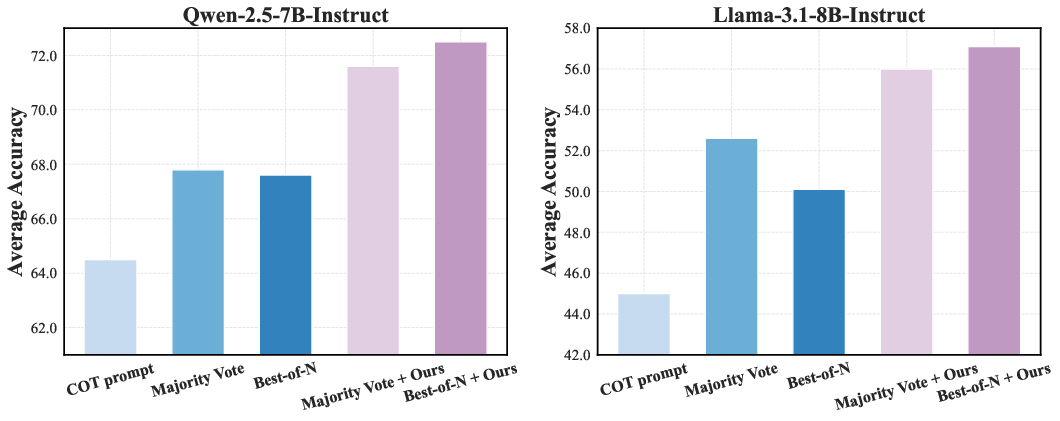
Figure 2: Averaged accuracy across MATH500, GSM8K, and GPQA. Blue bars represent standard test-time scaling methods, purple bars show these methods enhanced by our Fractional Reasoning.
- Adaptable Depth Control: Through variable α, models exhibit controlled reasoning, balancing between concise direct responses and detailed multi-step reasoning.
- Scalability: The method demonstrates robustness across varied compute budgets, showcasing linear improvements with increased sample sizes.
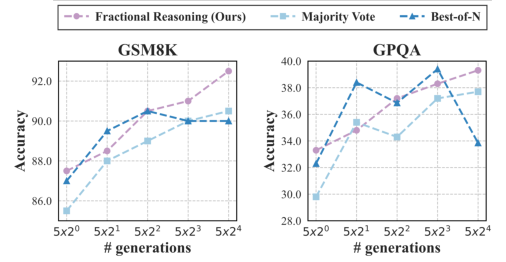
Figure 3: Accuracy on GSM8K and GPQA as a function of the number of generations.
Fractional Reasoning in Reflection
Beyond chain-of-thought prompting, Fractional Reasoning enhances reflection-based tasks:
Discussion and Conclusion
Fractional Reasoning provides a versatile, interpretable approach to inference time LLMs, addressing the limitations of uniform reasoning. The study outlines the potential for adaptive policies, suggesting future research to automate dynamic α tuning. This could further enhance model efficiency and precision, promoting comprehensive adaptability across reasoning and reflection contexts.
Endnote: Implementing these strategies allows for efficient, targeted reasoning scaling in LLMs, enhancing interpretability and execution at test time without additional training. The research supports ongoing developments in AI, potentially impacting diverse applications where reasoning precision is critical.