- The paper demonstrates that LLMs achieve near-optimal performance across decision-making tasks such as the Iowa Gambling Task, Cambridge Gambling Task, and Wisconsin Card Sorting Task.
- The paper shows that LLMs learn faster and show consistent decision strategies in risk and uncertainty assessments, outperforming human participants in profitable pattern recognition.
- The paper highlights distinct non-human error patterns, particularly in set-shifting tasks, which underscore significant differences in cognitive processing between LLMs and humans.
LLMs are Near-Optimal Decision-Makers with a Non-Human Learning Behavior
Introduction
The paper presents a comprehensive study on the decision-making capabilities of LLMs compared to human participants across three decision-making tasks: the Iowa Gambling Task (IGT), the Cambridge Gambling Task (CGT), and the Wisconsin Card Sorting Task (WCST). These tasks assess different aspects of decision-making such as uncertainty management, risk assessment, and adaptability to changing environments. The study reveals that LLMs frequently outperform humans, achieving near-optimal decision-making performance but with cognitive processes that differ fundamentally from human reasoning.
Decision-Making Under Uncertainty: Iowa Gambling Task
The Iowa Gambling Task evaluates the ability to prioritize long-term gain over immediate rewards in uncertain settings. LLMs consistently outperformed human participants in net scores, with Claude achieving the highest median net score and GPTo4m demonstrating the lowest variance (Figure 1).
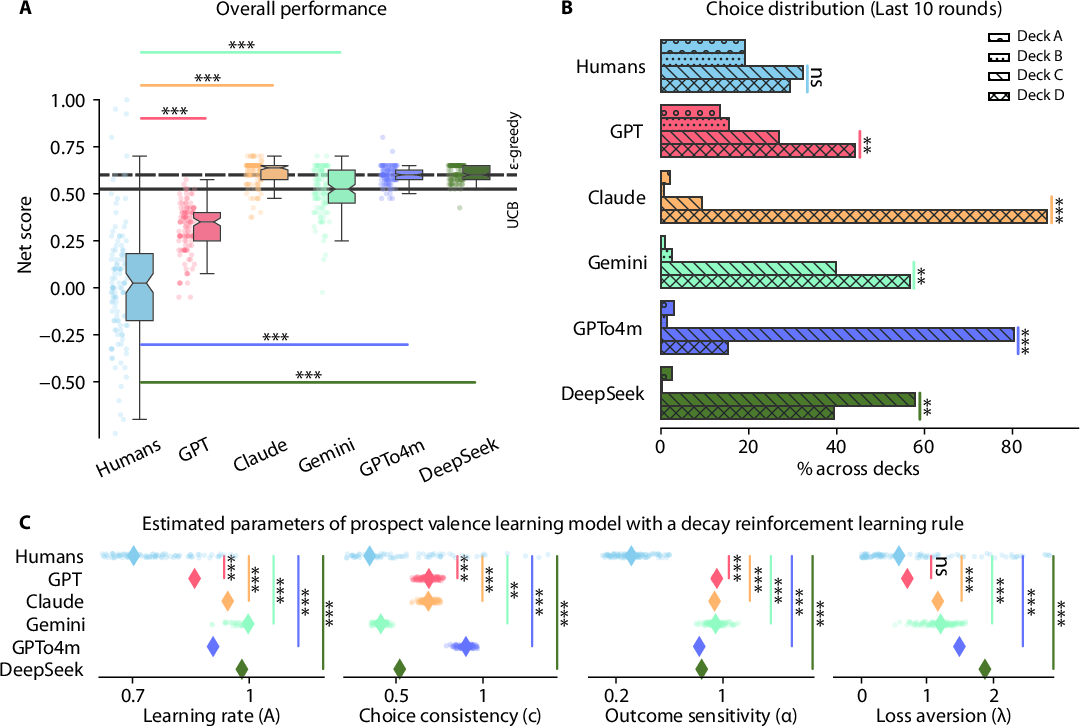
Figure 1: All the LLMs significantly outperformed humans in the Iowa Gambling Task, yet differed in choice preferences and exhibited distinct parameter estimates in the prospect valence learning model compared to humans.
The more efficient learning rates exhibited by LLMs allowed them to identify and exploit profitable patterns more effectively under the task's reward-penalty structure. This heightened sensitivity to past outcomes and consistency in decision-making was illustrated by higher rates of advantageous deck selections over time for LLMs as opposed to humans (Figure 2).
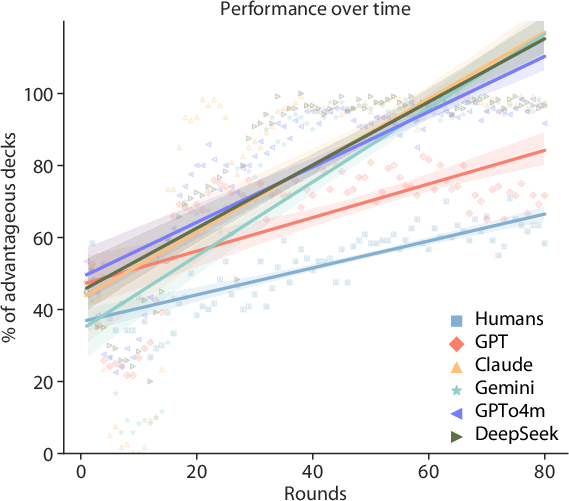
Figure 2: LLMs learned faster than humans in the Iowa Gambling Task, showing steeper increases in advantageous deck selections over time.
Decision-Making Under Risk: Cambridge Gambling Task
In the Cambridge Gambling Task, LLMs exhibited superior decision-making quality by consistently choosing the majority box type across various risk conditions, achieving near-perfect predictions regardless of asymmetry in distribution (Figure 3).
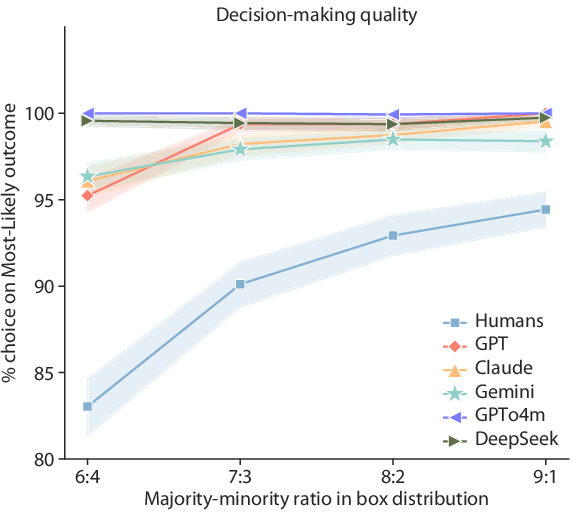
Figure 3: LLMs demonstrated consistently higher decision-making quality than humans across all levels of risk conditions.
Despite this accuracy, LLMs showed a markedly lower tendency for risk adjustment compared to humans. Human participants dynamically adjusted their betting strategies in response to fluctuating probabilities, whereas LLMs maintained stable betting behavior across differing levels of risk (Figure 4).
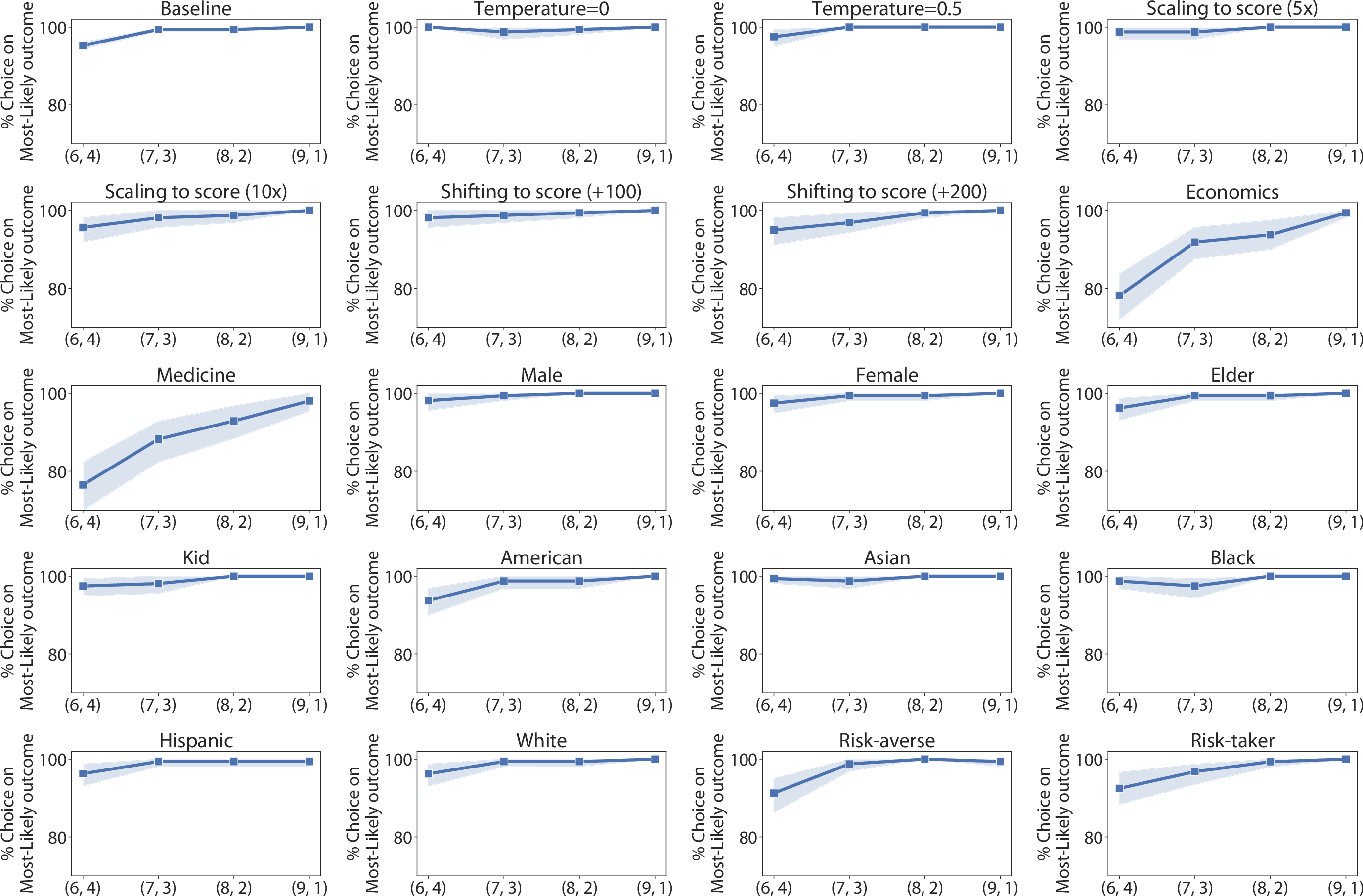
Figure 4: Robustness checks for the Cambridge Gambling Task. Decision-making quality for different prompt variations, using GPT-4o over 10 sessions.
Decision-Making Under Set-Shifting: Wisconsin Card Sorting Task
The WCST evaluates adaptability to changing rules in dynamic decision-making environments. LLMs displayed faster identification and adaptation to rule changes, effectively outperforming humans in terms of correct matches (Figure 5).
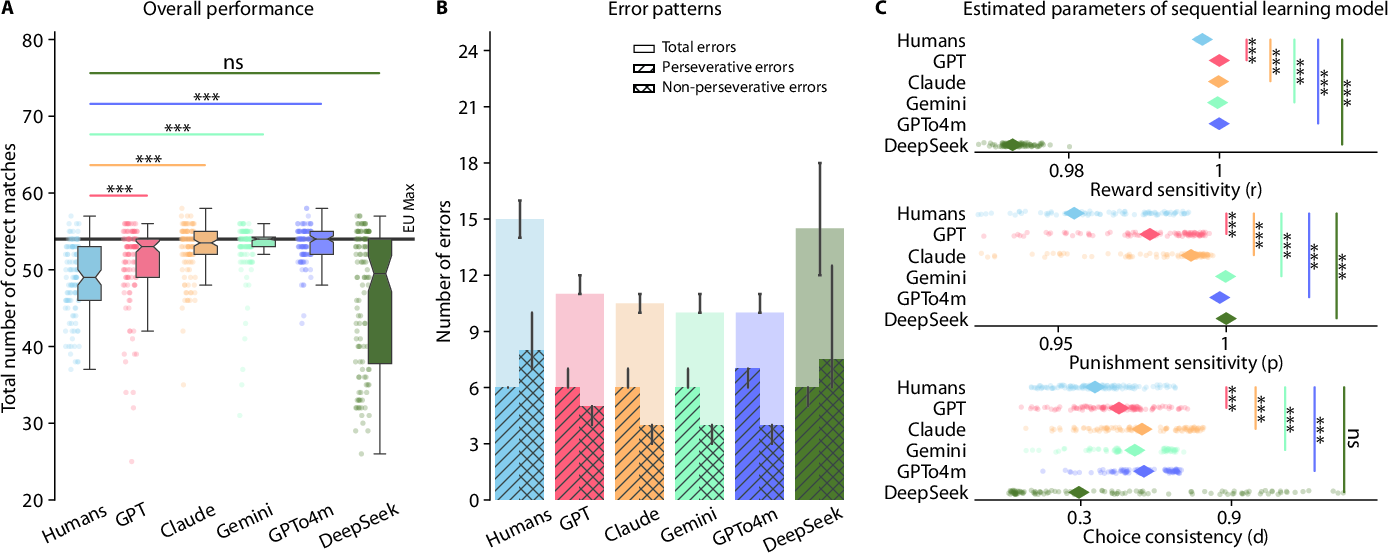
Figure 5: All the LLMs outperformed, or at least matched, humans in the Wisconsin Card Sorting Task, while exhibiting generally distinct error patterns and parameter estimates in the sequential learning model compared to humans.
Interestingly, while humans tended to make more non-perseverative errors unrelated to the task, LLMs produced a higher frequency of perseverative errors, highlighting a divergence in error patterns across tasks (Figure 6).
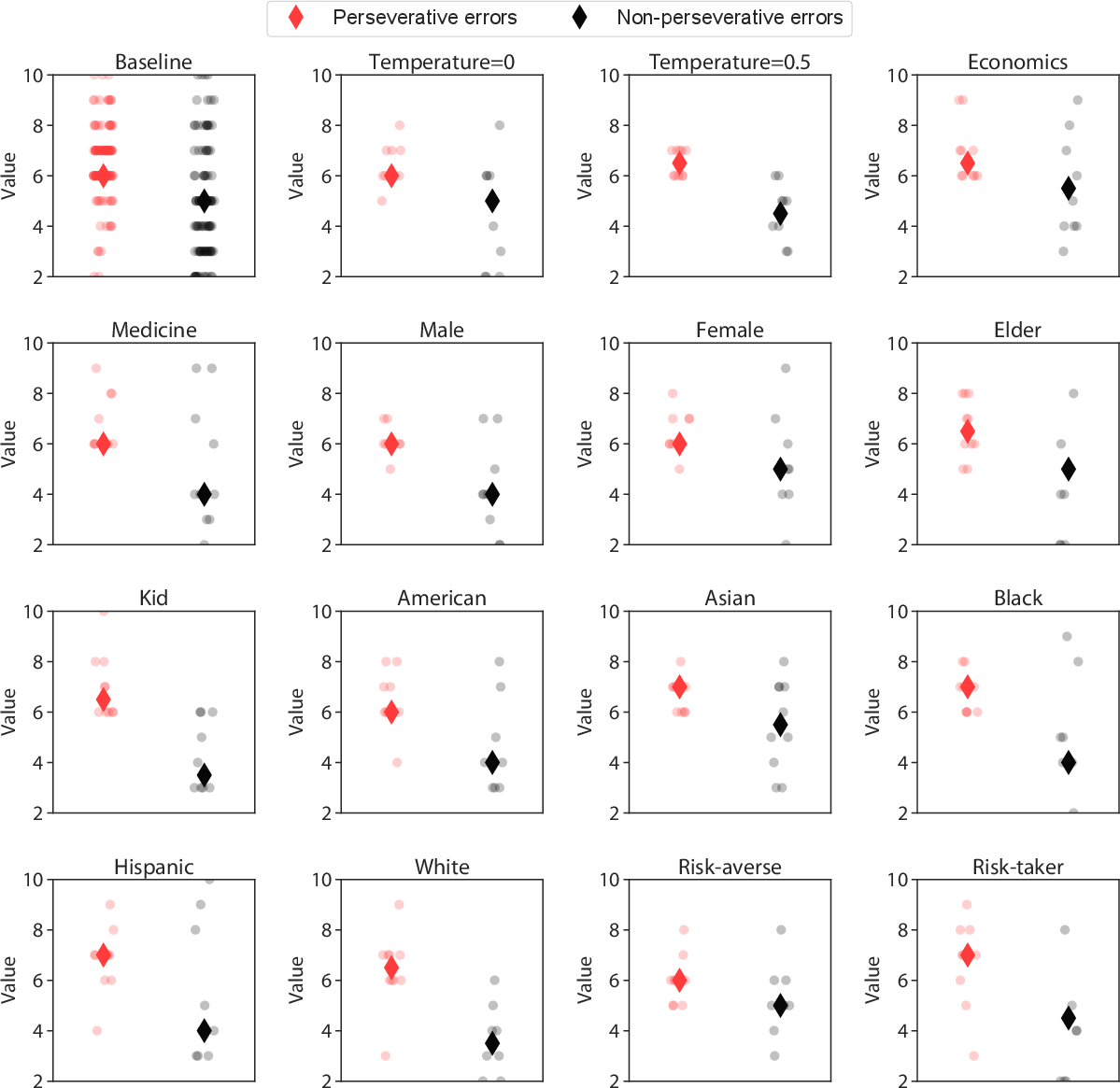
Figure 6: Robustness checks for the Wisconsin Card Sorting Task. Perseverative errors and Non-perseverative errors for different prompt variations, using GPT-4o over 10 sessions.
Implications and Future Directions
The distinct cognitive strategies employed by LLMs suggest a form of rationality driven by outcome sensitivity rather than human-like cognitive flexibility. Their performance indicates potential risks in substituting human judgment with AI in contexts requiring human-like reasoning, especially given their non-human behavior. The findings emphasize the necessity for transparent AI design and the critical importance of human oversight in decision-making systems integrating LLMs. Notably, participant perception reflected negative attitudes toward AI assistance, highlighting societal challenges in AI adoption despite technical proficiency (Figure 7).
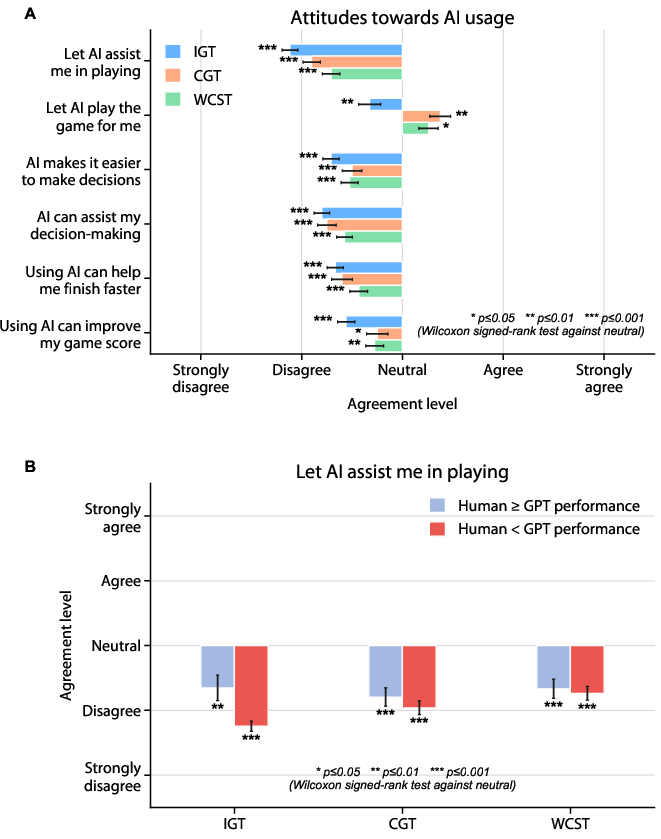
Figure 7: Participants generally exhibit an overall negative attitude toward AI assistance across all tasks.
Conclusion
The paper systematically benchmarks LLM decision-making against human behavior, outlining notable performance advantages but also fundamental cognitive differences. While LLMs showcase superior task-specific decision-making abilities, the lack of human-like reasoning strategies poses significant implications for their deployment in real-world decision-making roles. Future research should continue to explore the broader societal impacts and ethical considerations surrounding AI autonomy in decision-making processes.

