- The paper introduces a diffusion-based View-Conditioned Diffusion Transformer (VCDiT) that generates novel X-ray views from a single image.
- It employs a weak-to-strong training strategy and cross-attention mechanisms to ensure high-resolution and anatomically coherent image synthesis.
- Experimental results on the LIDC-IDRI-DRR dataset show significant improvements over traditional methods, indicating potential for reduced radiation exposure and enhanced diagnostic accuracy.
SV-DRR: High-Fidelity Novel View X-Ray Synthesis Using Diffusion Model
Introduction
The novel "SV-DRR: High-Fidelity Novel View X-Ray Synthesis Using Diffusion Model" presents an innovative approach to tackle the limitations inherent in conventional X-ray imaging. Primarily concerned with synthesizing high-fidelity novel views from a single X-ray image, the study proposes a diffusion-based pipeline aimed at overcoming challenges related to angular range, resolution, and image quality in existing synthesis methods. This work leverages state-of-the-art advancements in diffusion models to enhance anatomical detail preservation and proposes a progressive weak-to-strong training strategy to ensure high-resolution image generation stability.
Methodology
The SV-DRR approach centers around a View-Conditioned Diffusion Transformer (VCDiT) that synthesizes new X-ray projections by conditioning on relative target views. This model follows the Latent Diffusion Model (LDM) framework, operating within the latent space of a Variational Autoencoder (VAE) to reduce computational demands while maintaining detail richness. Utilizing a cross-attention mechanism, the VCDiT efficiently integrates view-conditioning and structural alignment through dual streams: concatenated image embeddings with view parameters and channel-concatenated noisy target latents.
A unique weak-to-strong training strategy progressively increases image resolution, facilitating robust model performance at high resolutions. This gradual transition is stabilized by interpolating positional embeddings between resolutions, thereby ensuring consistency across image scales.
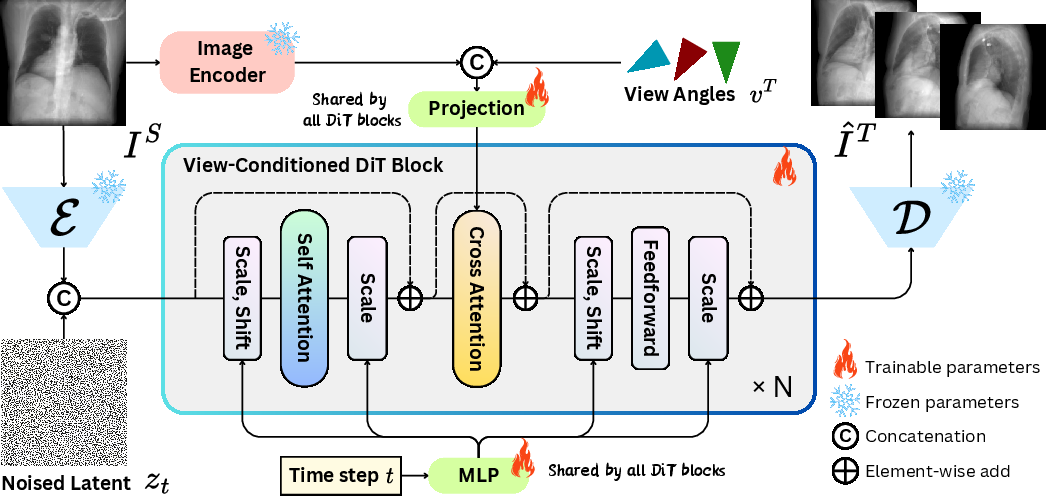
Figure 1: Overview of SV-DRR. Given a source X-ray image IS and relative target views vT, SV-DRR synthesizes realistic X-ray projections I^T.
Experimental Validation
The analysis substantiates SV-DRR's superior capabilities using the LIDC-IDRI-DRR dataset, with comparative metrics against contemporary methods like XraySyn, Zero123, and Zero123-XL. The SV-DRR model exhibits impressive performance across image quality measurements—PSNR, SSIM, LPIPS, and FID—demonstrating its proficiency in synthesizing anatomically coherent and visually realistic X-ray views, even for substantial angular discrepancies.
(Image below)
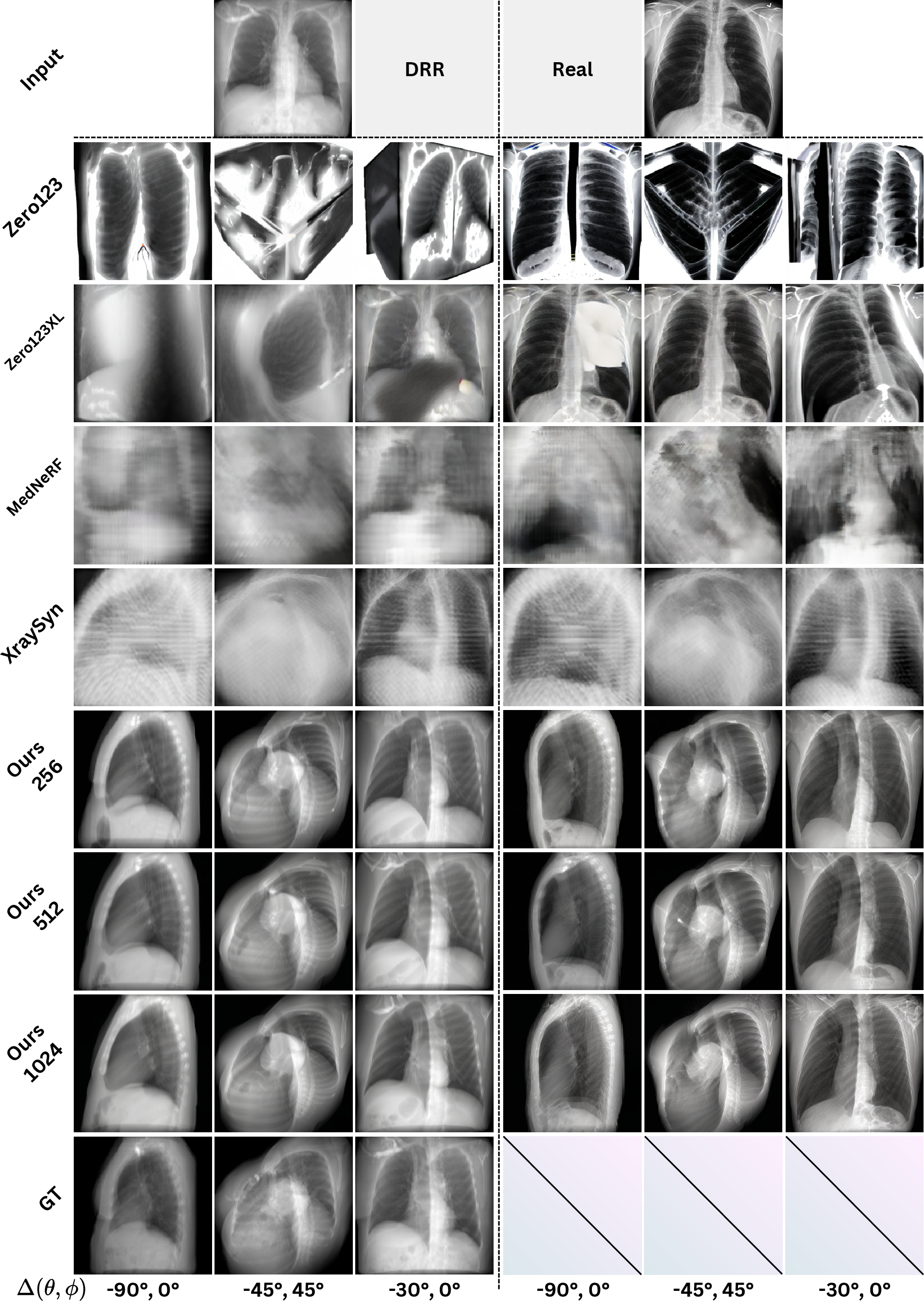
Figure 2: Comparison of synthesized X-ray images at different resolutions using our method (256, 512, 1024) against baselines. Superior fidelity in structure and orientation is evident with the use of diffusion models.
Beyond quantitative benchmarks, the paper details qualitative assessments, where expert evaluations illuminate the high realism of SV-DRR synthesized images, as evidenced by indistinguishable performance from DiffDRR-generated counterparts.
Implications and Future Directions
Implications extend across clinical, educational, and data augmentation applications. Particularly, the approach promises significant reductions in radiation exposure by minimizing the need for multiple imaging angles while maintaining high diagnostic quality. The robust synthesis framework supports diverse medical applications, potentially offering a viable alternative in environments lacking comprehensive CT scanning capabilities.
Future research may explore enhancements in cross-view anatomical alignment to further solidify realism and leverage SV-DRR for broader application in 3D medical imaging contexts.
Conclusion
"SV-DRR: High-Fidelity Novel View X-Ray Synthesis Using Diffusion Model" delivers a compelling synthesis strategy that significantly advances multi-view X-ray imaging. By integrating cutting-edge diffusion methodologies and an innovative training paradigm, the model sets a new standard for image synthesis fidelity and utility in medical imaging applications. Future expansions of the approach could reinforce its relevance across even more complex imaging scenarios, highlighting continued potential for diffusion-based models in clinical radiography.

