- The paper introduces multi-agent debate strategies to outperform single-agent LLM approaches with an F1-score jump from 0.726 to 0.841.
- It presents a systematic taxonomy of MAD configurations, detailing roles like debaters, judges, and structured interaction protocols.
- Experimental evaluations reveal improved precision-recall balance for classifying functional versus non-functional requirements, albeit with increased computational costs.
Multi-Agent Debate Strategies to Enhance Requirements Engineering with LLMs
Introduction
The paper "Multi-Agent Debate Strategies to Enhance Requirements Engineering with LLMs" (2507.05981) investigates the utilization of Multi-Agent Debate (MAD) strategies to enhance the performance of LLMs in the domain of Requirements Engineering (RE). Despite the broad application of LLMs in RE tasks, the prevalent methods such as prompt engineering, model fine-tuning, and retrieval augmented generation lack the collaborative and iterative refinement seen in multi-agent systems. Inspired by human debate, the authors propose MAD among LLM agents to achieve improved accuracy and reduced bias by incorporating complementary perspectives.
MAD Strategies: Taxonomy and Analysis
The paper first conducts a systematic review of existing MAD strategies across diverse domains to establish a foundational taxonomy of their characteristics.
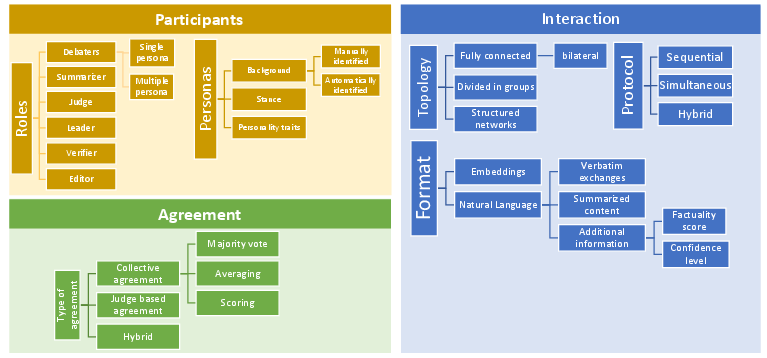
Figure 1: Taxonomy of Multi-Agent Debate characteristics.
Participants: MAD strategies involve varied roles, including debaters, judges, summarizers, and critics. Debaters are fundamental participants tasked with presenting viewpoints, while judges or summarizers synthesize or decide outcomes based on arguments presented. Participants can be defined by specific personas, influencing debate outcomes with varied stances and personality traits.
Interaction: Interactions among participants follow structured protocols, leveraging both sequential and simultaneous discussion formats. Topologies can range from basic bilateral debates to complex configurations involving multiple agents interacting through sparse or fully connected networks.
Agreement Strategies: Consensus mechanisms may involve collective decision-making through majority or weighted votes among debaters, or rely on a judge to finalize decisions based on the debate content.
The taxonomy demonstrates the diversity and adaptability of MAD strategies across domains, providing insights for future applications in RE tasks.
Application to Requirements Engineering
The authors address the application of MAD to RE tasks through experimental evaluations focusing on binary classification—distinguishing functional from non-functional requirements.
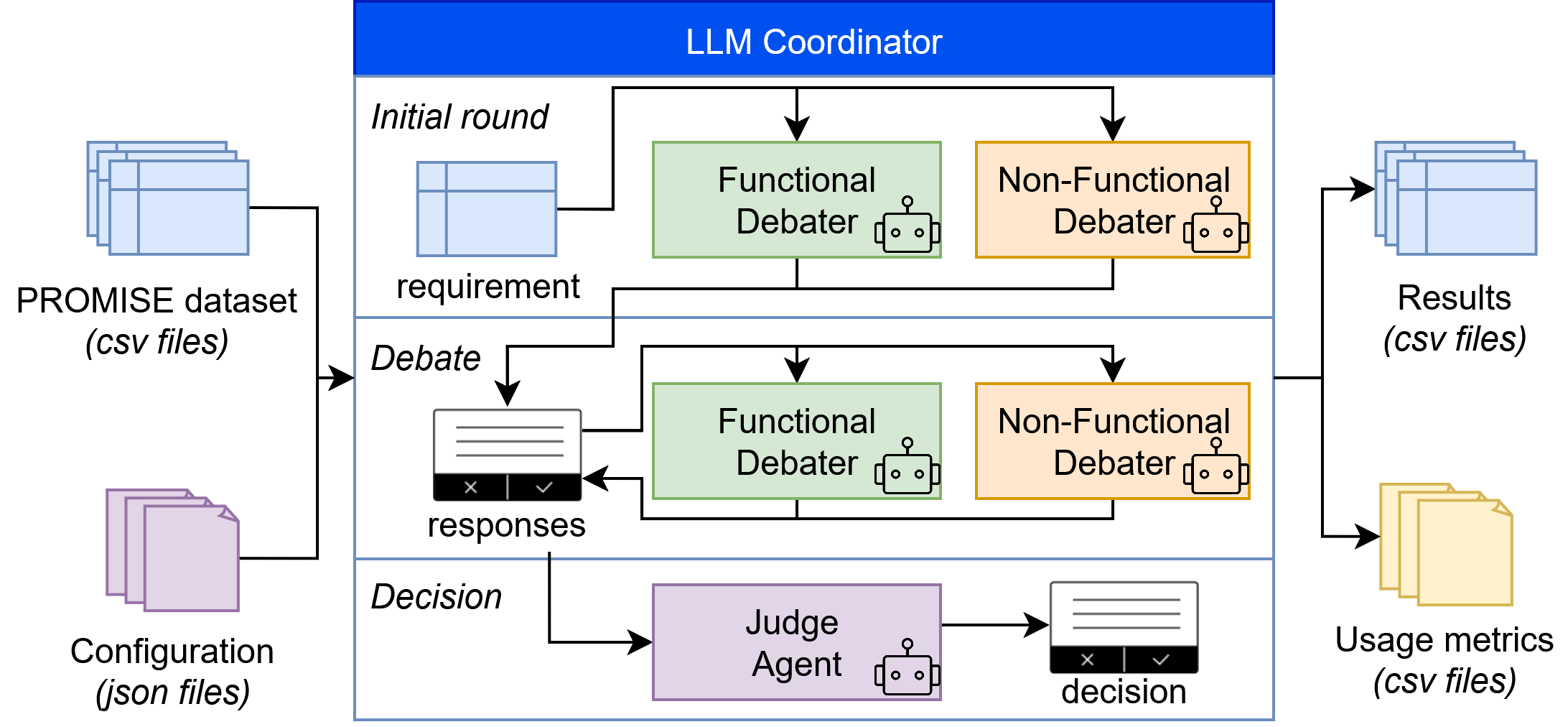
Figure 2: MAD architecture and interaction workflow.
Design: A MAD framework is introduced, leveraging three participants: two debaters representing functional and non-functional stances, and a judge deciding based on their arguments. Interaction protocols include both direct argument exchanges and iterative rounds for refining positions.
Evaluation: Experiments reveal that MAD strategies significantly enhance classification accuracy, with the F1-score improving from 0.726 with single-agent models to 0.841 for MAD at one interaction iteration. Notably, recall improvements for non-functional requirements are most pronounced, addressing imbalance issues between precision and recall in traditional methods. However, these gains come at increased computational and monetary costs, emphasized when interactions increase beyond one iteration.
Implications and Future Work
The study highlights MAD's potential to advance RE task accuracy by fostering collaboration among LLM agents. It underscores the importance of balancing accuracy improvements with resource efficiency, particularly in environments with limited computational capabilities. Future work should explore more complex RE tasks, evaluating diverse MAD configurations and optimizing the trade-off between correctness gains and computational overhead.
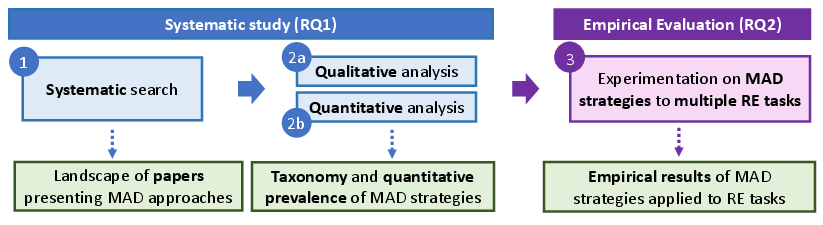
Figure 3: Research plan.
The proposed research plan aims to refine MAD approaches through comprehensive experiments across varied RE tasks, contributing refined strategies for broader applicability in the field. However, the dynamic evolution of AI models and the availability of high-quality datasets may pose constraints on the generalizability and scalability of MAD in RE tasks.
Conclusion
The paper provides valuable insights into the potential of MAD strategies, establishing a taxonomy to guide their application in RE. By integrating collaborative debate mechanisms, MAD offers promising improvements in LLM accuracy, setting the stage for further exploration in AI-enhanced Requirements Engineering. As the field progresses, ongoing efforts should focus on refining MAD strategies and expanding their applicability to complex and high-stakes RE scenarios.