- The paper introduces iMAD, a framework that selectively initiates debates via self-critique and a debate-decision classifier to improve LLM inference accuracy.
- It employs self-critique prompting to extract 41 linguistic and semantic features, using FocusCal loss to optimize debate-triggering decisions.
- Experiments show up to 13.5% accuracy improvement and 92% token reduction compared to baselines, demonstrating enhanced efficiency and reliability.
Intelligent Multi-Agent Debate Framework: iMAD
Introduction to iMAD
The paper "iMAD: Intelligent Multi-Agent Debate for Efficient and Accurate LLM Inference" (2511.11306) proposes a novel token-efficient framework called intelligent Multi-Agent Debate (iMAD) to enhance reasoning accuracy and efficiency in LLM systems. Unlike traditional Multi-Agent Debate (MAD) frameworks, which initiate debate for every query, iMAD selectively triggers debates, reducing unnecessary computational costs while improving accuracy. This is achieved by learning generalizable behavior patterns from LLM outputs to determine when to initiate a debate.
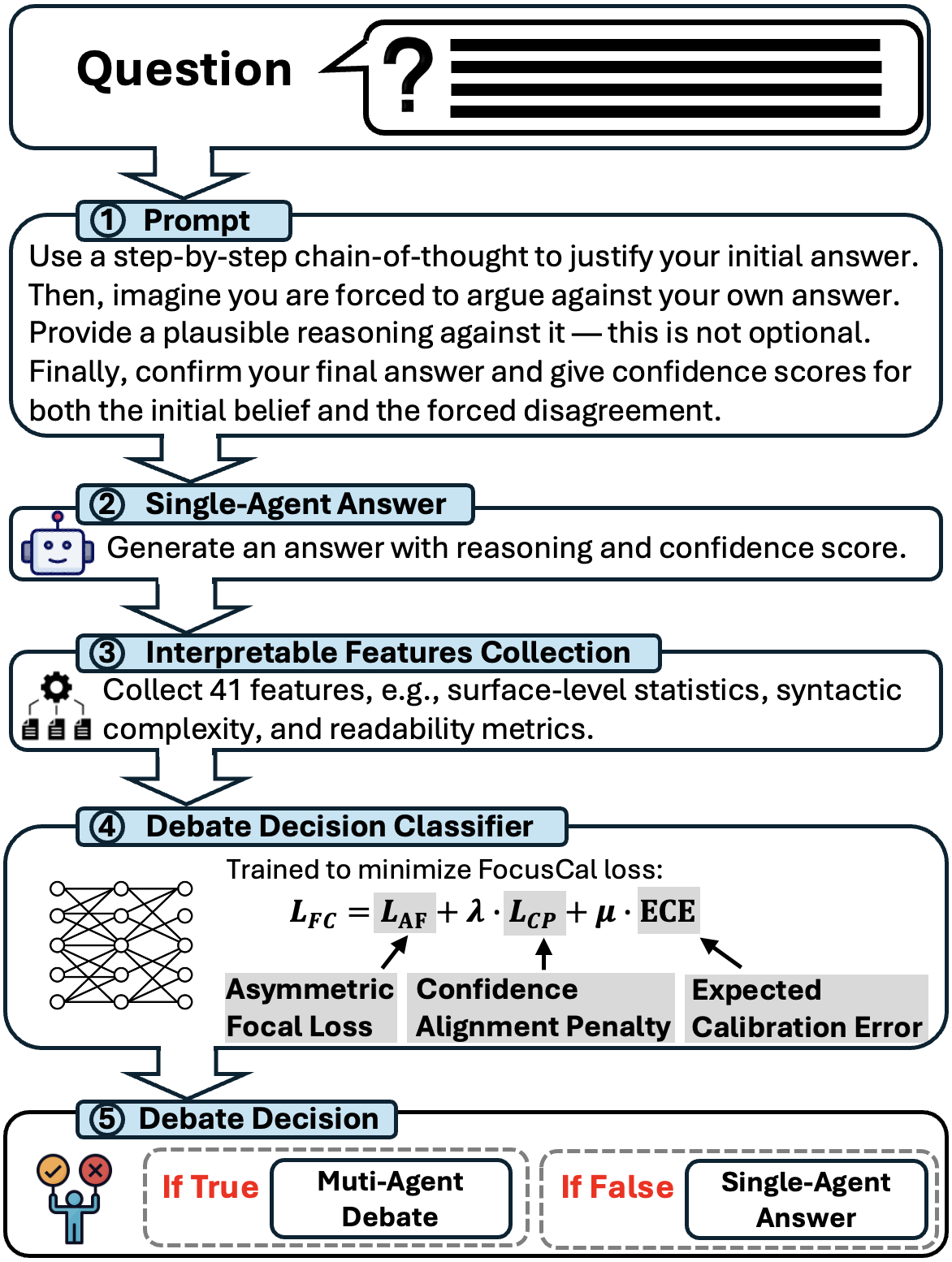
Figure 1: Overall workflow of iMAD.
The iMAD method improves the efficiency of MAD by utilizing a self-critique mechanism and a debate-decision classifier. The self-critique prompt leads a single agent to generate a structured critique of its initial response, from which linguistic and semantic features are extracted. These features, in turn, inform a lightweight classifier, trained using the novel FocusCal loss, to decide whether a MAD is warranted.
Methodology
Self-Critique Prompting and Feature Extraction
The iMAD framework begins with prompting an LLM to produce an initial response that includes both an answer with justification and a self-critique. This process is crucial for unearthing linguistic indicators like hesitation or conflicting logic, which are vital for the subsequent decision-making process. A total of 41 features are extracted, encompassing lexical cues, syntactic characteristics, and semantic indicators of uncertainty.
Debate-Decision Classifier
The core of iMAD's decision process lies in the debate-decision classifier. This classifier uses an MLP architecture to evaluate whether a debate might correct potential errors in the initial response. To enhance decision accuracy, the classifier employs FocusCal loss, which incorporates Asymmetric Focal Loss, Confidence Penalty, and Expected Calibration Error (ECE), addressing the model’s overconfidence issues and aligning the debate-triggering decisions with empirical correctness.
FocusCal Loss
FocusCal loss is designed to optimize the classifier's ability to identify when a debate could be beneficial. It integrates:
- Asymmetric Focal Loss (AF): Emphasizes penalization of overconfident incorrect predictions.
- Confidence Penalty (CP): Corrects misalignment between predicted confidence and semantic uncertainty.
- Expected Calibration Error (ECE): Enhances calibration between predicted scores and empirical correctness, reinforcing reliable identification of debatable scenarios.
These components collectively improve the classifier's robustness, ensuring that debates are initiated intelligently to boost overall system accuracy without excessive token use.
Experimental Evaluation
iMAD was evaluated across six datasets, demonstrating its capability to reduce token usage by up to 92% while enhancing accuracy by up to 13.5%. It was compared against five baselines including traditional single-agent and full-debate frameworks. The results clearly illustrated iMAD's advantage in both efficiency and accuracy.
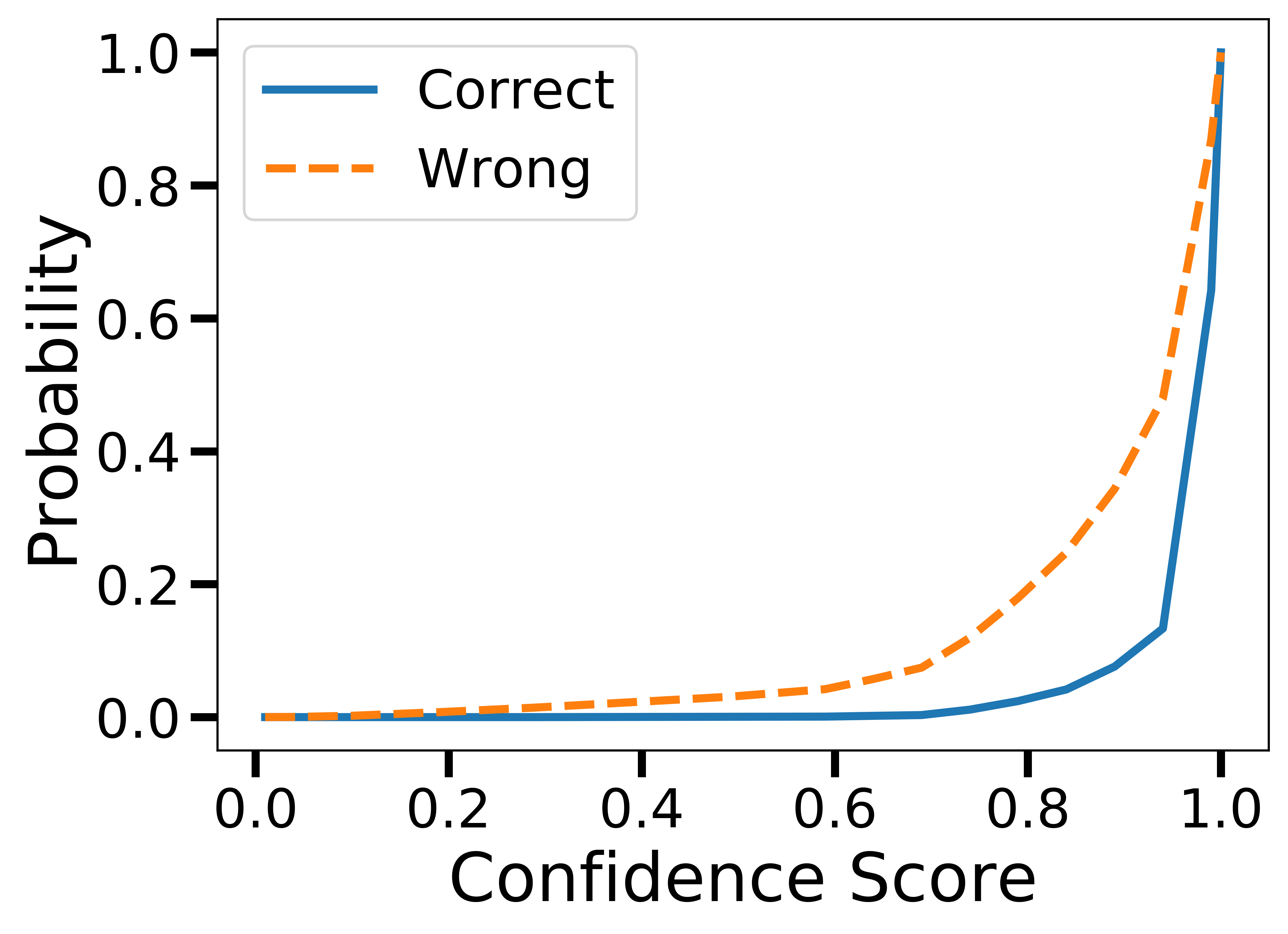
Figure 2: Cumulative Density Function (CDF) of confidence scores for correct and incorrect single-agent answers.
The efficacy of iMAD is further evident in its ability to adjust debate decisions based on empirical cues rather than fixed confidence thresholds, a distinct improvement over existing methods like DOWN. The decision classifier's accuracy in identifying beneficial debates (up to 95.9% alignment with correct answers) exemplifies iMAD's proficiency in maintaining high accuracy with reduced computational overhead.
Theoretical and Practical Implications
The implementation of iMAD represents a substantial stride in the pursuit of efficient and accurate AI systems leveraging LLMs. The framework's selective debate mechanism ensures that computational resources are allocated optimally, engaging in multi-agent reasoning only when probable benefit exists. This characteristic not only curtails unnecessary token expenditure but also aligns with real-world deployment scenarios where computational efficiency is paramount.
Looking forward, iMAD paves the way for future research in adaptively learning when collaborations between agents can genuinely enhance outcomes, without pre-evaluated reliance on LLM confidence scores alone. This adaptability embodies a significant shift toward more intelligent and resource-efficient AI reasoning paradigms.
Conclusion
iMAD offers a sophisticated approach to managing reasoning tasks within LLM systems by selectively engaging in multi-agent debates only when advantageous. By cutting down extraneous discourse and focusing computational effort where it matters most, iMAD delivers enhanced accuracy in an efficient manner. Through further explorations, such as online learning for more dynamic adaptability, iMAD's approach could further revolutionize AI reasoning and inference processes.