Free-MAD: Consensus-Free Multi-Agent Debate
Abstract: Multi-agent debate (MAD) is an emerging approach to improving the reasoning capabilities of LLMs. Existing MAD methods rely on multiple rounds of interaction among agents to reach consensus, and the final output is selected by majority voting in the last round. However, this consensus-based design faces several limitations. First, multiple rounds of communication increases token overhead and limits scalability. Second, due to the inherent conformity of LLMs, agents that initially produce correct responses may be influenced by incorrect ones during the debate process, causing error propagation. Third, majority voting introduces randomness and unfairness in the decision-making phase, and can degrade the reasoning performance. To address these issues, we propose \textsc{Free-MAD}, a novel MAD framework that eliminates the need for consensus among agents. \textsc{Free-MAD} introduces a novel score-based decision mechanism that evaluates the entire debate trajectory rather than relying on the last round only. This mechanism tracks how each agent's reasoning evolves, enabling more accurate and fair outcomes. In addition, \textsc{Free-MAD} reconstructs the debate phase by introducing anti-conformity, a mechanism that enables agents to mitigate excessive influence from the majority. Experiments on eight benchmark datasets demonstrate that \textsc{Free-MAD} significantly improves reasoning performance while requiring only a single-round debate and thus reducing token costs. We also show that compared to existing MAD approaches, \textsc{Free-MAD} exhibits improved robustness in real-world attack scenarios.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way for groups of AI “agents” (like smart chatbots) to work together to solve tough problems. The method is called Free-MAD, short for “Consensus-Free Multi-Agent Debate.” Unlike older approaches that try to make all agents agree on one answer, Free-MAD avoids forced agreement and instead picks the best answer by looking at how each agent’s thinking changes during the discussion. This makes the system more accurate, faster, and harder to trick.
What questions were the researchers asking?
- How can we get better answers from a group of AI agents without making them all agree (which can spread mistakes)?
- Can we reduce “peer pressure” among AI agents so good answers don’t get replaced by bad ones?
- Can we choose the final answer more fairly by considering the whole debate, not just the last messages?
- Will this make the system more secure against attacks and more efficient (using fewer tokens and time)?
How did they do it? Methods explained simply
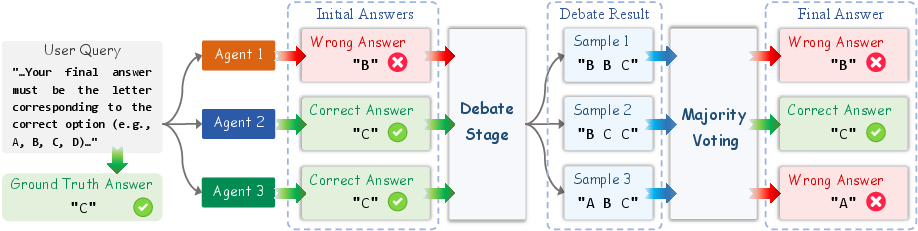
Think of a group chat where several AI “students” discuss a problem. Traditional multi-agent debate (MAD) works like this:
- They talk for several rounds.
- At the end, they vote on which answer most agents support (majority vote).
- Problem: if a few agents are wrong but confident, others may copy them. This is called “conformity” (like following the crowd). It can spread errors, wastes tokens, and can be unfair or random when votes are split.
Free-MAD changes two big things:
1) Consensus-free debate with anti-conformity
- Instead of telling agents to agree, the system encourages them to think critically.
- Each agent must explain its reasoning (step-by-step) and actively check others’ logic for mistakes.
- The idea is: don’t switch your answer just because others picked it—switch only if their reasoning is clearly better.
- In simple terms: less “peer pressure,” more “prove it.”
Technical idea in everyday terms: The paper models each agent’s reply as a mix of two forces:
- Independent reasoning: how well the agent can think on its own.
- Conformity: how much the agent matches the group. A prompt can push this mix toward independent thinking (anti-conformity) or toward agreement (conformity), depending on the task.
2) Score-based decision (a smarter way to pick the final answer)
- Instead of only looking at the last round, Free-MAD keeps a scoreboard for all answers that appear during the debate.
- Answers get points when agents switch to them (suggesting they found better reasoning).
- Answers lose points when agents abandon them (suggesting they found flaws).
- Answers also get points if agents stick with them (stability matters).
- Later rounds count a bit less to reduce the risk of late-stage peer pressure overwhelming good reasoning.
Analogy: Imagine a science fair judge watching students debate. The judge records:
- When someone moves to a new answer (maybe they discovered stronger evidence).
- When they leave an answer (maybe they found a mistake).
- When they hold steady (confidence backed by good steps). The judge adds up these signals over time and picks the answer with the highest overall score. If there’s a tie, the system breaks it randomly for robustness.
Two versions for different needs:
- Free-MAD-n: uses anti-conformity prompting + scoring (best when blind agreement is a problem).
- Free-MAD-c: uses normal/conformity prompting + scoring (can help on simpler tasks or when shared knowledge helps).
What did they find and why it matters?
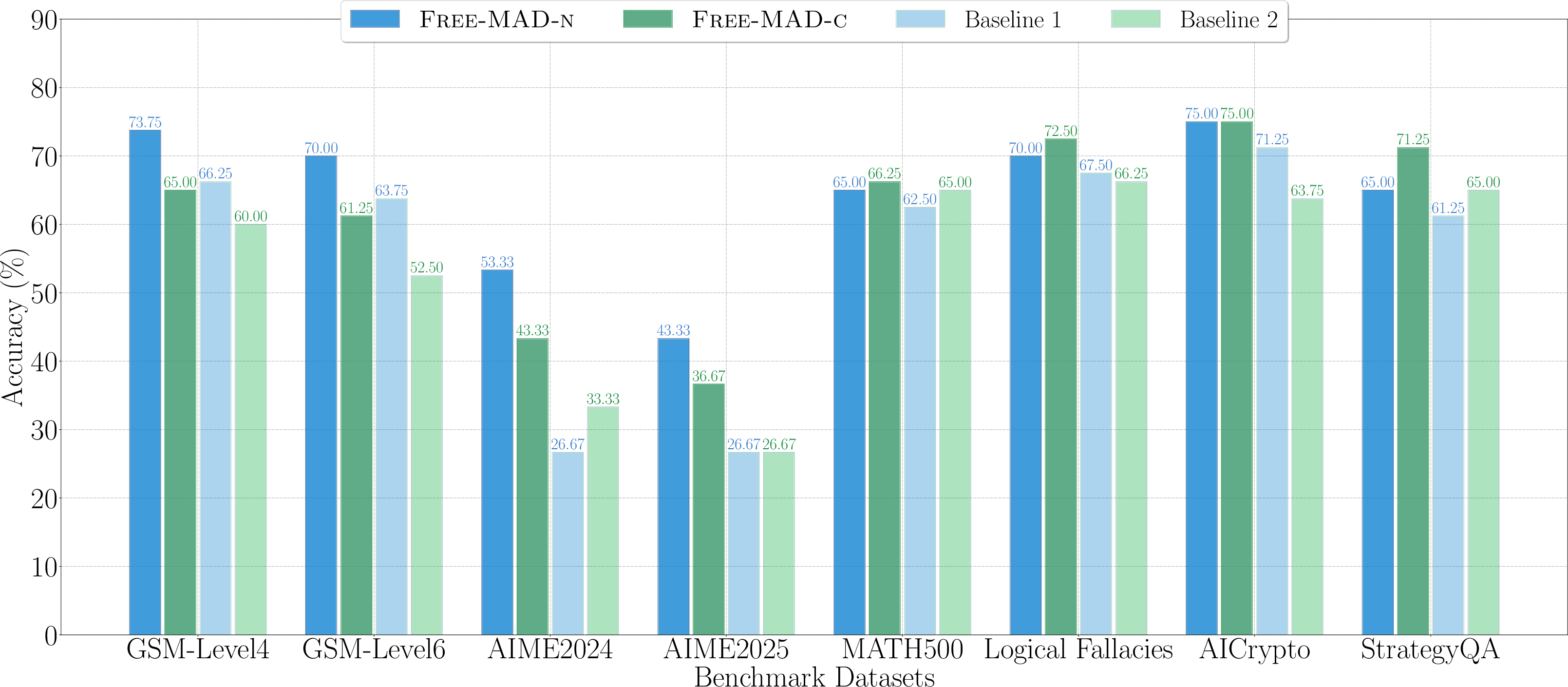
Across eight test sets (math, logic, and knowledge-based questions), Free-MAD showed:
- Better accuracy: On average, Free-MAD beat strong baselines by about 13–17%. It also did well on harder math problems, where careful reasoning matters.
- Fewer rounds and lower cost: It can work in a single debate round while matching or beating the accuracy of multi-round methods—saving tokens and time.
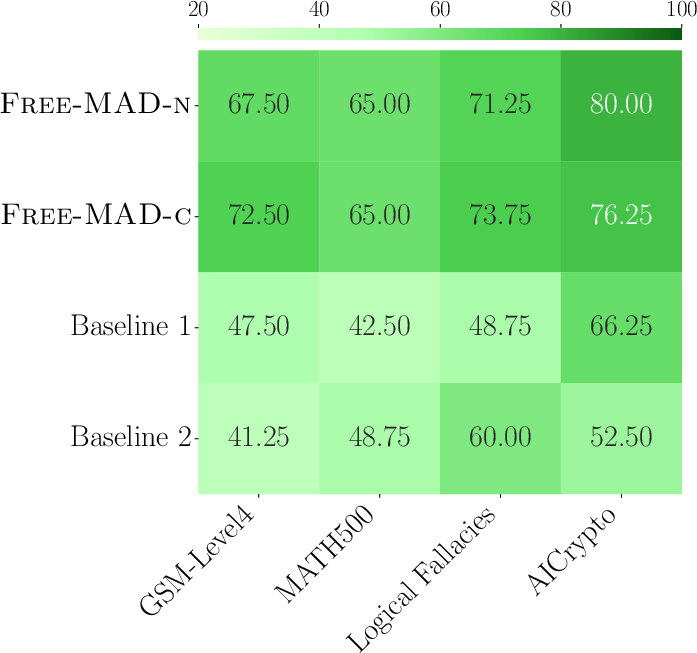
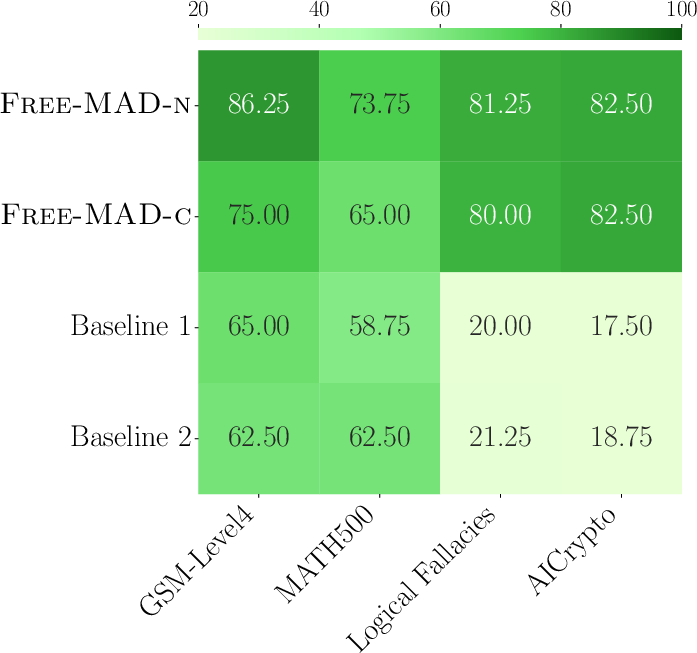
- More robust to attacks: If some agents can’t receive messages (communication attacks) or are influenced by bad prompts, Free-MAD’s scoring still picks good answers and stays accurate.
- Fairer and less biased: Agents don’t need special roles or a “judge AI” that might be biased. All agents contribute equally, and the decision logic is outside the models (so it’s not affected by hallucination).
- Practical balance: Anti-conformity helps avoid error spreading, but for some simpler or knowledge-light tasks, a bit of conformity can be useful. That’s why they offer both Free-MAD-n and Free-MAD-c.
So what? Implications and impact
Free-MAD shows that AI group discussions don’t need forced agreement to be effective. By scoring the whole debate (not just the final round) and encouraging careful, explainable reasoning, we get:
- More reliable answers in areas like math problem solving, coding, healthcare, and cybersecurity.
- Faster, cheaper systems (fewer tokens, fewer rounds).
- Stronger security against real-world risks (like prompt injection or broken communication).
- Fairer decision-making without relying on a single “judge” model.
In short, Free-MAD turns multi-agent debate into a smarter, safer group chat: agents think critically, the system tracks how opinions evolve, and the best-supported answer wins—no crowd-following required.
Collections
Sign up for free to add this paper to one or more collections.