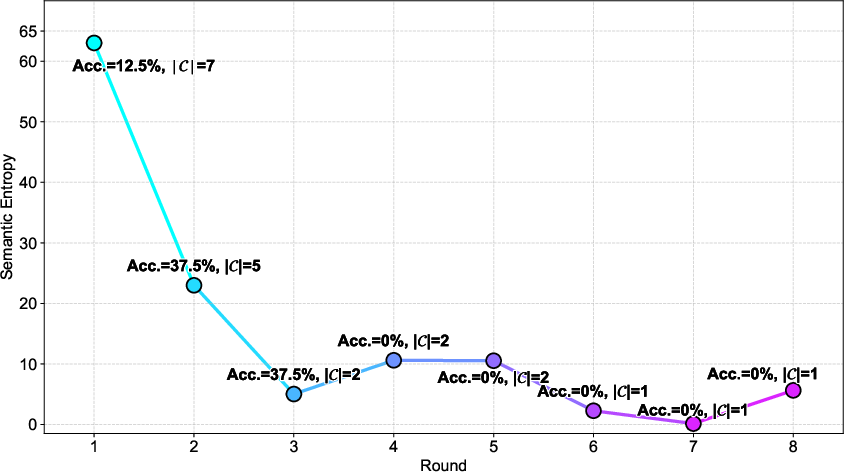
- The paper introduces SEAT, a framework that leverages semantic entropy to dynamically terminate multi-round parallel reasoning for efficient performance.
- It employs Monte Carlo approximation and optimal stopping theory to quantify semantic diversity and guide early stopping decisions.
- Extensive experiments across benchmarks show significant accuracy improvements (up to 85.67%) and better resource allocation without extra fine-tuning.
Adaptive Termination for Multi-round Parallel Reasoning
Introduction
The paper "Adaptive Termination for Multi-round Parallel Reasoning: An Universal Semantic Entropy-Guided Framework" (2507.06829) addresses the limitations of current LLMs in both sequential and parallel reasoning. While LLMs have advanced artificial general intelligence, they encounter constraints such as inefficient termination and lack of coordination among parallel branches. The paper proposes a novel framework named SEAT (Semantic Entropy-Adaptive Termination), which aims to mediate these issues by integrating the strengths of both reasoning paradigms through a dynamic quality metric: semantic entropy (SE).
Semantic Entropy as a Quality Metric
A fundamental insight of the paper is the introduction of semantic entropy (SE) as a robust metric for assessing reasoning quality. SE quantifies the semantic diversity of model responses, showing a strong negative correlation with response accuracy: higher SE often indicates lower model accuracy. This relationship serves as the cornerstone of the proposed framework, enabling adaptive termination by dynamically adjusting the reasoning process based on SE metrics.
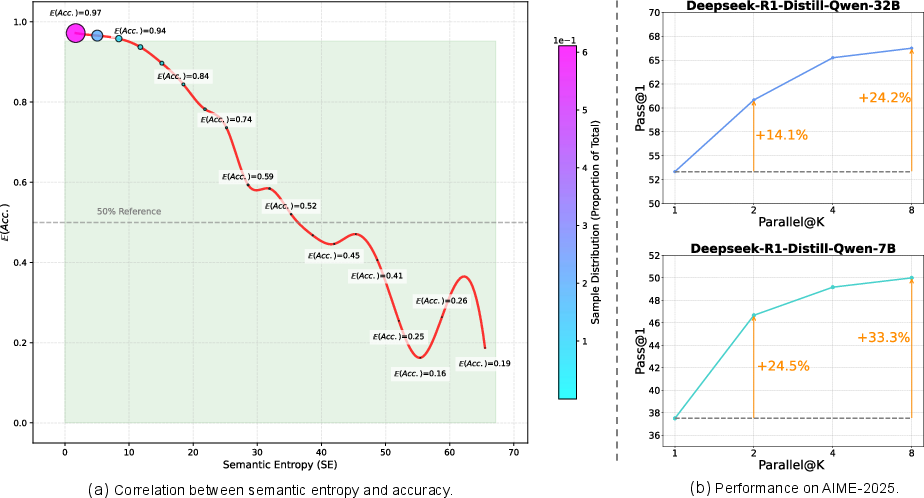
Figure 1: Strong negative correlation between semantic entropy and model accuracy on Math-500 benchmark.
SEAT Framework: Design and Implementation
SEAT comprises a plug-and-play framework leveraging parallel and sequential reasoning. It dynamically adjusts parallelization degrees and employs SE-based stopping criteria, which can either be statistical or inspired by optimal stopping theory. This versatility ensures maximized efficiency without sacrificing performance. The framework's architecture is illustrated in (Figure 2).
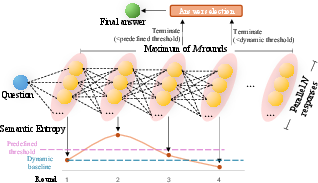
Figure 2: The overview of our proposed SEAT.
Key Components
- Multi-round Parallel (MRP) Inference: SEAT constructs an N×M reasoning structure, combining diverse parallel explorations and sequential refinements, thereby facilitating error correction and robust performance without additional fine-tuning.
- Semantic Entropy Calculation: By employing a Monte Carlo approximation, SE quantifies the uncertainty in responses, providing a signal for potential early stopping to avoid unnecessary computational expenses if the model output is unlikely to improve.
- Adaptive Termination Mechanism: This is implemented in two forms:
Experimental Results
Comprehensive evaluations were conducted across multiple benchmarks (AIME-2024, AIME-2025, MATH-500, MINERVA, and GPQA) using 7B and 32B models. The experiments demonstrated substantial accuracy improvements with SEAT. For instance, the R32B model showed an accuracy increase from 70.83% to 85.67% on AIME-2024 and similar gains for the R7B model. Notably, SEAT effectively mitigated performance degradation in smaller models by preventing "semantic entropy collapse," a situation where smaller models output overly confident, incorrect answers (Figure 4).
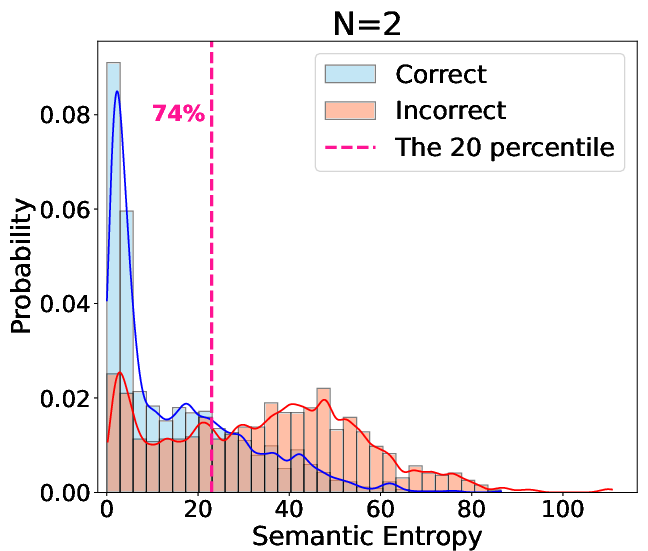
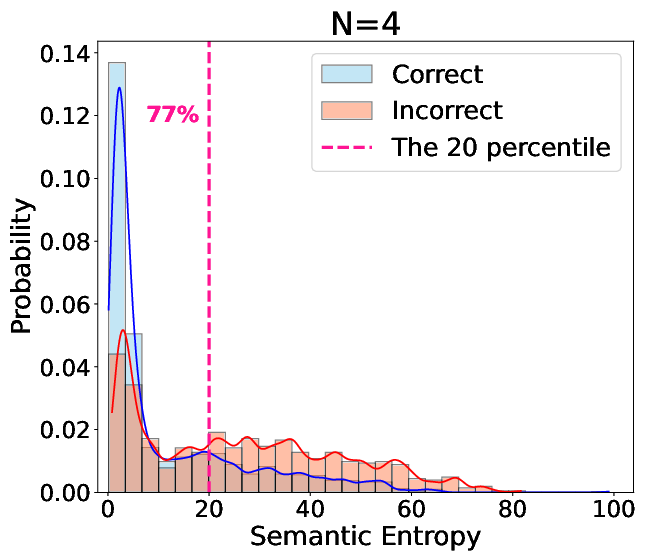
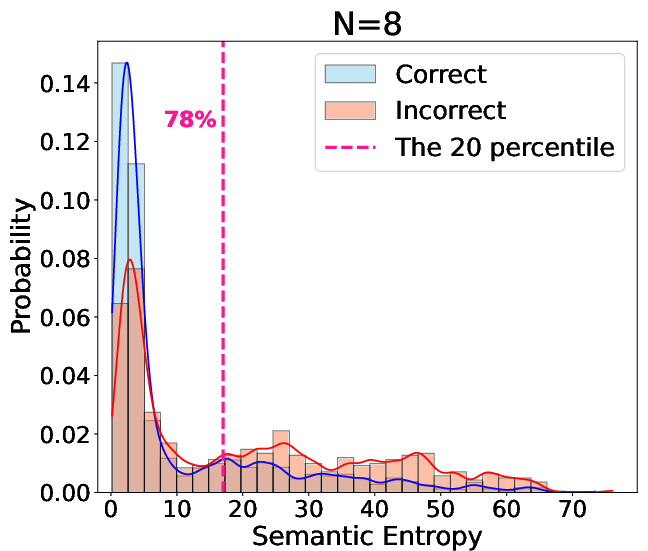
Figure 4: Semantic entropy distribution highlighting correct answer proportion within low entropy regions.
Future Implications
This research opens paths for LLMs to manage computational resources more effectively through test-time scaling. By employing semantic entropy as an intrinsic reasoning quality indicator, LLMs can more adaptively allocate effort to difficult problems. Future work may expand the SEAT framework to accommodate other unsupervised indicators and integrate complementary techniques like majority voting to further augment reasoning performance.
Conclusion
The SEAT framework represents a significant advance in test-time scaling strategies by integrating semantic entropy as a metric for adaptive termination in reasoning tasks. Through its innovative merge of parallel and sequential strategies, SEAT enables more efficient and effective LLM reasoning. This approach mitigates the risk of semantic entropy collapse, particularly vital for maintaining performance in smaller models, thus broadening the scope of practical applications in AI.