- The paper introduces a fairness-augmented archetypal analysis method (FairAA) that minimizes group-specific bias while preserving interpretability.
- The methodology extends traditional AA with a fairness regularizer that penalizes covariance with sensitive attributes using both linear and kernel approaches.
- Experimental results on synthetic and real-world data (ANSUR I) demonstrate reduced group separability and high explained variance, confirming effective trade-offs between utility and fairness.
Incorporating Fairness Constraints into Archetypal Analysis: An Expert Summary
Motivation and Context
Archetypal Analysis (AA) is a convex representation learning framework that decomposes data into extremal points (“archetypes”), situated halfway between clustering and PCA. AA offers interpretable latent factors but, like other unsupervised methods, can encode sensitive attributes, thereby propagating bias in downstream applications. This paper introduces Fair Archetypal Analysis (FairAA) and its nonlinear kernel extension (FairKernelAA), providing explicit fairness regularization to mitigate group-specific bias in the AA projection space.
Fairness in unsupervised learning, particularly representation learning, is less explored compared to supervised settings. However, representational bias is critical since unsupervised transformations often precede supervised decision-making. This study seeks to ensure the learned latent space does not encode sensitive attributes, such as demographic group membership, thus enabling ethically responsible use of AA-derived representations.
Methodology
Archetypal Analysis Primer
AA models each datapoint as a convex combination of k archetypes, themselves convex combinations of original samples, by minimizing reconstruction error subject to simplex constraints. Optimization is performed via projected gradient descent, maintaining interpretability and preserving convexity of factors.
Fairness Regularization in AA
Building upon recent fair PCA formulations, the principal fairness objective is to make the latent AA representation uninformative of sensitive attributes. Specifically, FairAA minimizes the standard AA reconstruction objective augmented by a fairness term penalizing the covariance between sensitive attribute vectors and the learned projections. The fairness term adopts a relaxation: statistical independence is approximated by zero covariance for all linear adversaries.
The FairAA optimization problem is:
$\arg\min_{\mathbf{S}, \mathbf{C}} \left[\norm{\mathbf{X} - \mathbf{SCX}}_F^2 + \lambda \norm{\mathbf{z}\mathbf{S}}_F^2 \right]$
where z encodes centered group membership. The hyperparameter λ trades off utility (explained variance) and fairness (group indistinguishability). Gradients are analytically derived; computational complexity matches standard AA.
Extensions
- Kernelization: FairKernelAA leverages kernel matrices, online with the pairwise dependency of AA, enabling projection fairness in nonlinear Hilbert spaces.
- Multiple Groups: FairAA generalizes seamlessly to multiclass and multi-attribute sensitive features via multivariate group indicator matrices.
- Multiple Sensitive Attributes: Critical attributes with several groupings are handled by combining all one-hot encodings in a single fairness matrix.
Experimental Evaluation
Three key metrics quantify trade-offs:
- Explained Variance (EV): Reconstruction fidelity of the AA projection.
- Mean Maximum Discrepancy (MMD): Distributional distance between sensitive group projections.
- Linear Separability (LS): Logistic regression accuracy for group prediction from projected representations; lower values denote greater fairness.
Synthetic Experiments
Linear Two-Class Toy Dataset
Projections from standard AA yield clear group separation; FairAA suppresses separability, with nearly identical archetypes preserved.
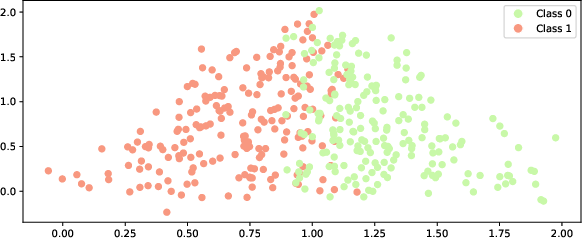
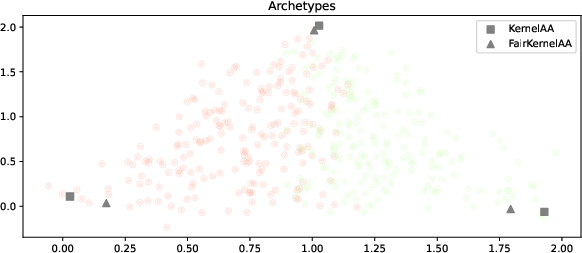
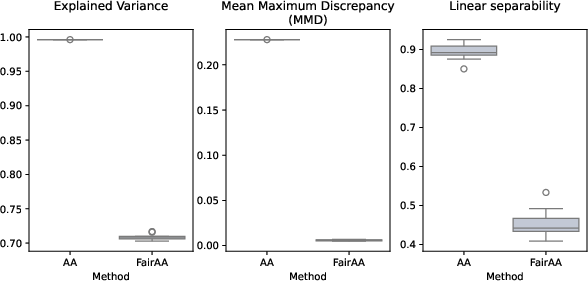
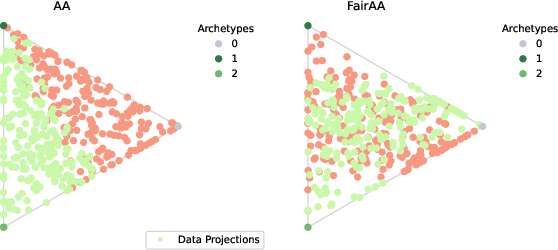
Figure 1: Toy dataset with two classes, used to benchmark AA and FairAA performance.
Nonlinear Two-Class Toy Dataset
FairKernelAA applies RBF kernelization; group-specific structure is largely mitigated in latent space, while utility remains high.
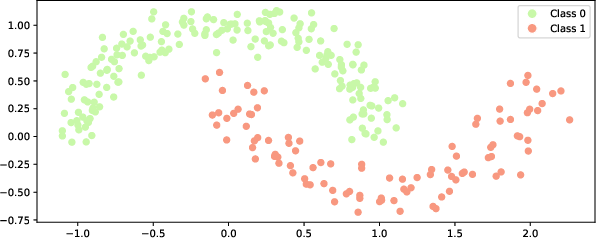
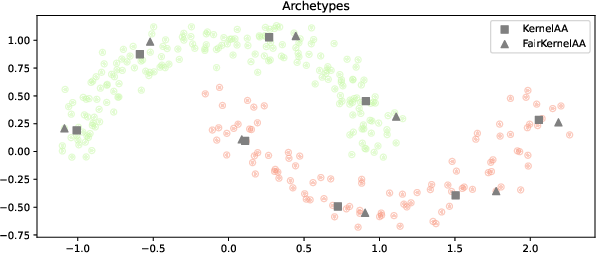
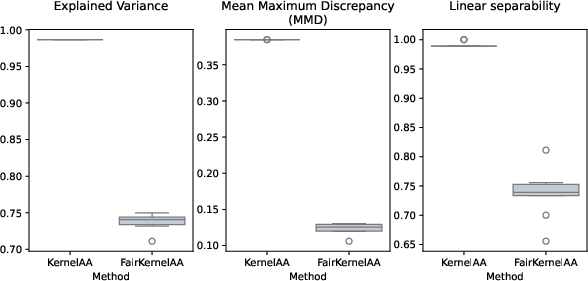
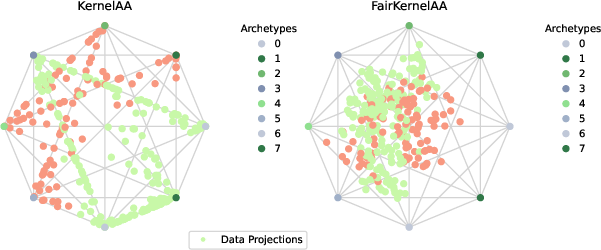
Figure 2: Nonlinear toy dataset with two classes illustrating kernel fairness regularization.
Four-Class Toy Dataset
FairAA maintains low MMD and LS for multidimensional groupings with minimal drop in utility.
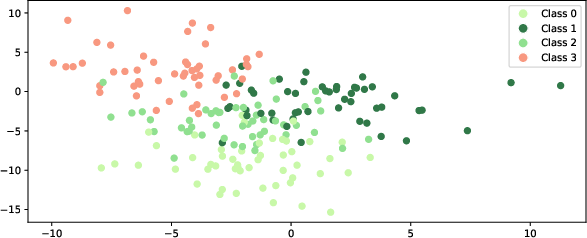
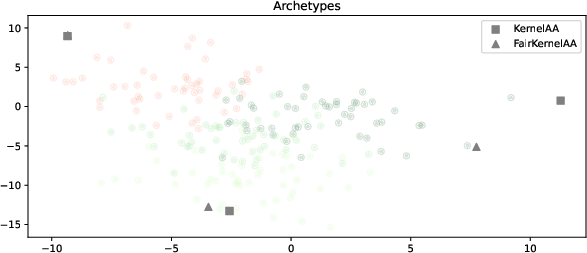
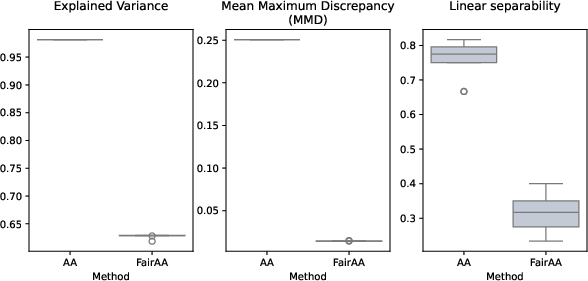
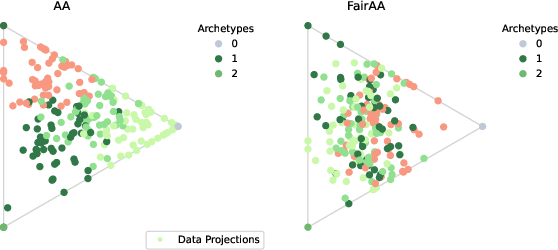
Figure 3: Toy dataset with four classes, demonstrating FairAA's multi-group efficacy.
Real-World Benchmark: ANSUR I Dataset
FairAA is evaluated on ANSUR I anthropometric data, relevant for gender-based fairness. Standard AA projections afford high linear separability between sexes; FairAA achieves substantial reduction in group-distinguishability while retaining high explained variance and archetype interpretability.
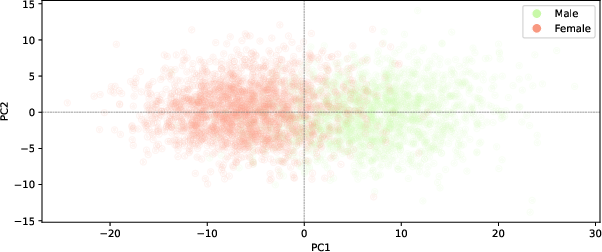
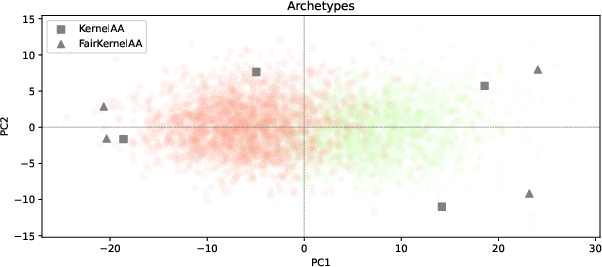
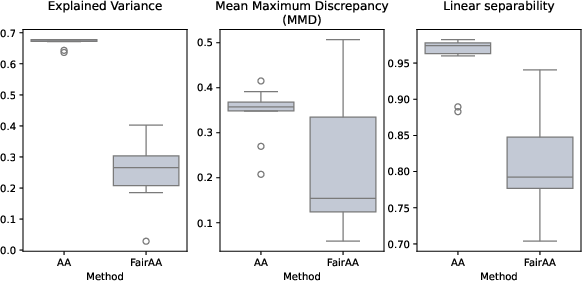
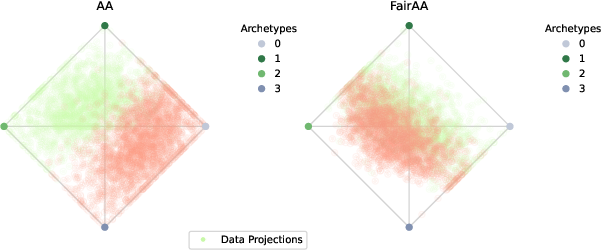
Figure 4: Projection of the ANSUR I dataset onto its first two principal components, visualizing group separation.
Numerical Results and Claims
Across all synthetic and real datasets, FairAA (and FairKernelAA) consistently yield reduced MMD and LS scores—quantifying significantly less group-specific information—while maintaining explained variance typically exceeding 80% of baseline AA. This evidences an effective trade-off between representation utility and fairness. Archetype consistency across models confirms the robustness of the fairness regularization.
Implications and Future Directions
The introduction of fairness constraints into AA addresses an important gap in unsupervised representation learning. Practically, FairAA enables deployment of interpretable latent spaces in sensitive domains (e.g., healthcare, finance, law) without encoding group distinctions, thus mitigating risk of discriminatory downstream decisions and regulatory non-compliance.
Theoretically, FairAA demonstrates that convex representation learning can be augmented to ensure fairness with minimal compromise to data fidelity, establishing a formal link between group parity and convex factor models.
Future work may target extensions such as balancing group-wise reconstruction errors, enforcing parity in both mean and higher-order moments, and integrating adversarial learning paradigms to handle more complex group dependence. Broader notions like individual-level fairness and algorithm-agnostic interventions remain open areas.
Conclusion
FairAA and FairKernelAA advance fairness-aware unsupervised learning by embedding explicit group regularization in archetypal analysis. Empirical results substantiate their ability to minimize latent group information with negligible loss in interpretability and utility. The methodological framework is robust, extensible, and applicable to both synthetic and real-world settings, paving the way for fair representation learning in critical applications.