- The paper introduces a framework that conceptualizes self-attention as a discrete-time Markov chain, enabling analysis of both direct and indirect token interactions.
- It employs repeated Markov transitions (multi-bounce attention) to denoise signals and reveal metastable token clusters, quantified through the second eigenvalue (λ2).
- TokenRank, derived from the DTMC steady state, accurately ranks token importance, leading to improvements in zero-shot segmentation and generative tasks.
Discrete-Time Markov Chains as a Universal Lens for Attention Interpretation
Introduction and Motivation
The paper "Attention (as Discrete-Time Markov) Chains" (2507.17657) introduces a unified interpretative and analytic framework for transformer self-attention by casting attention matrices as discrete-time Markov chains (DTMCs). This perspective enables systematic reasoning about both direct and indirect flow of information between tokens, moving beyond conventional methods that focus primarily on local (first-order) structure in the attention matrix. The authors formalize higher-order operations as repeated Markov transitions ("bounces") and utilize insights from Markov chain theory, notably steady-state analysis (TokenRank) and eigenstructure, to extract global and robust signals of token importance. The framework provides both theoretical clarity and integrated, lightweight tools which empirically enhance segmentation, attribution, and generative tasks.
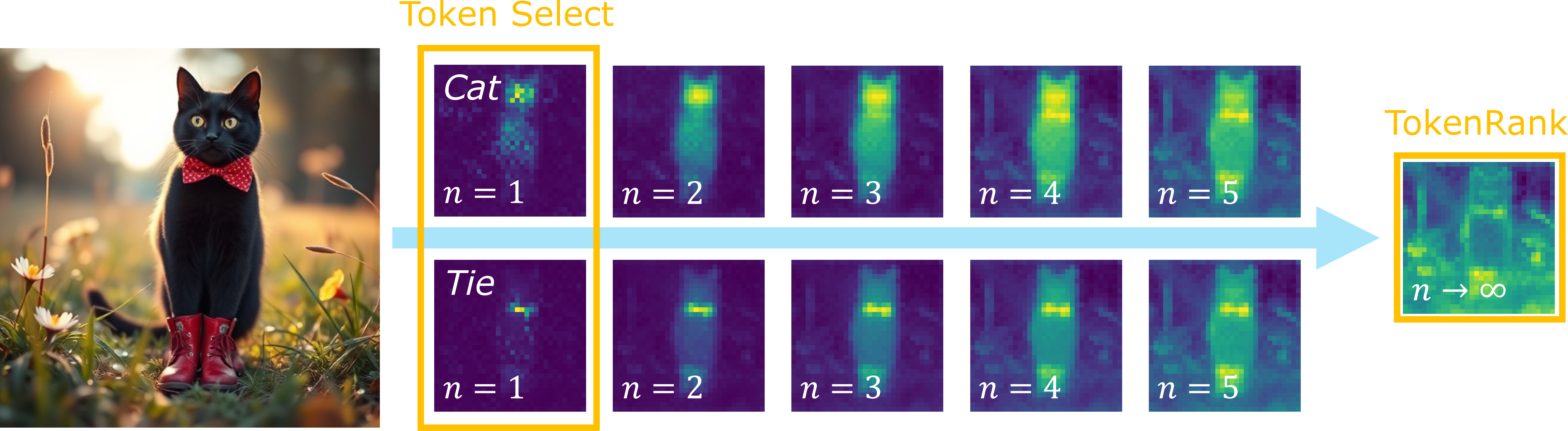
Figure 1: Attention Chains interprets attention matrices as Markov chains, where higher-order transitions capture indirect attention effects and lead to TokenRank steady states.
Self-attention matrices, after softmax normalization, are row-stochastic: all entries are non-negative, and row sums are unity. The authors exploit this structure by identifying the attention matrix A∈Rn×n with the transition matrix of a DTMC over n states (tokens). Transition Ai,j is interpreted as the probability of moving from state i to j in one time step.
Key Markovian tools are systematically mapped to standard attention operations:
- Row and column selection: Direct attention (row) and direct dependency (column) are first-bounce transitions from one-hot initial distributions.
- Sum and mean over heads: Head aggregation is described as averaging over Markov processes, which can dilute or obscure metastable structure. The authors propose λ2-based eigenvalue weighting to improve signal extraction.
- Matrix multiplication across layers: This corresponds to chaining time-inhomogeneous Markov processes, paralleling previous "rollout" and gradient-based attributions, but with a principled stochastic descriptor.
The central innovation is extending analyses to higher-order interactions by iterating the Markov process (multi-bounce attention).
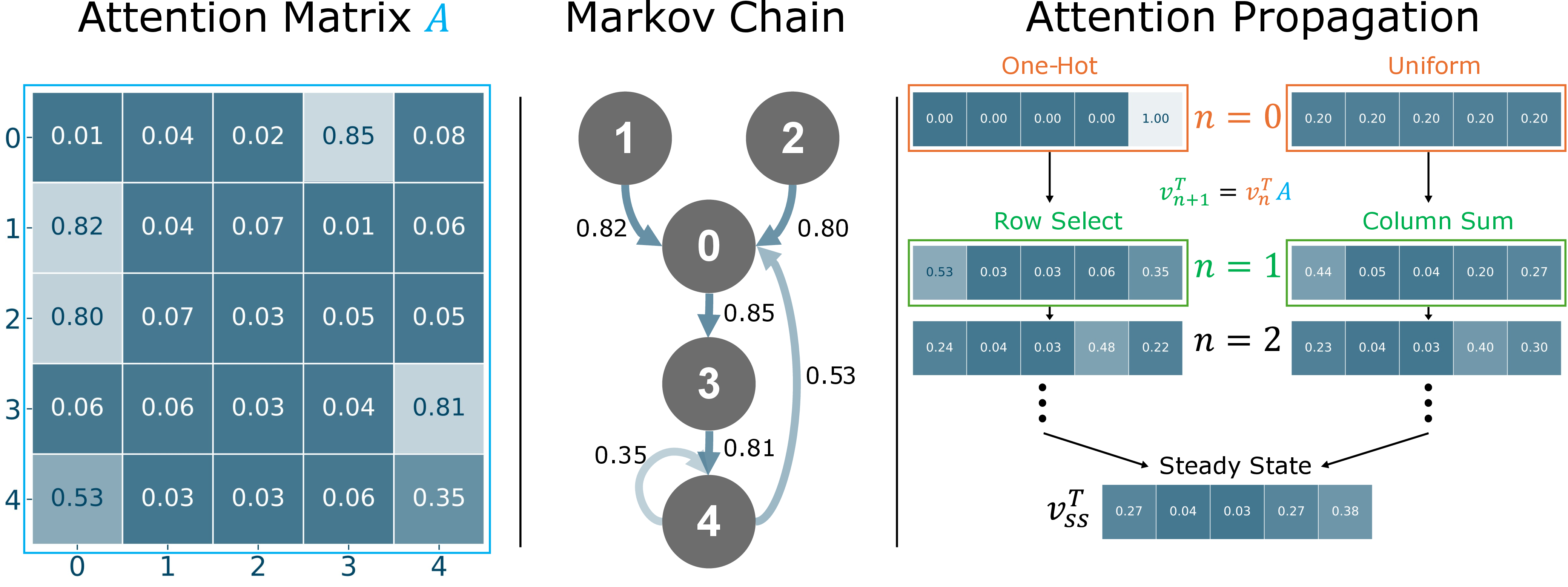
Figure 2: Higher-order attention propagation demonstrates the indirect influence of tokens, with repeated bounces amplifying metastable states.
The multi-bounce construction is conceptually and computationally simple: start from an initial distribution (e.g., one-hot or uniform), and iteratively apply the attention matrix:
vn+1T=vnTA
With sufficiently many iterations, the distribution converges to the stationary eigenvector (the DTMC steady state). The intermediate bounces (low-order propagation) exhibit denoising of noisy attention and reinforcement of persistent token clusters—these "metastable states" correspond to semantically coherent regions, empirically improving robustness and selectivity of attention map–derived masks.
Careful eigenanalysis reveals that the second largest eigenvalue λ2 quantifies the coherence and stability of these metastable clusters: larger λ2 values indicate slower mixing, signaling persistent substructure relevant for segmentation and interpretability.








Figure 3: Iterative Markov "bouncing" sharpens signal on structured inputs (real images) and diffuses rapidly for random, unstructured data, as reflected in convergence rates (second eigenvalue magnitudes).
TokenRank: Global Index of Token Importance
TokenRank is introduced as the Markov chain's steady-state vector, analogous to PageRank in web graphs. For attention, TokenRank quantifies the global importance of tokens by integrating recursively all direct and indirect influence paths. Existence and uniqueness is enforced by stochastic smoothing (as in PageRank teleportation) if needed.
Empirically, TokenRank yields less noisy, sharper, and more faithful attributions compared to typical direct column/row operations or naive head averaging, especially in large pretrained vision transformers. It also has a dual interpretation: applying the power method to a properly normalized attention matrix produces global incoming TokenRank (authorities), while the transpose produces outgoing TokenRank (hubs).



















Figure 4: TokenRank captures global incoming attention flow, surpassing local-centric or noisy baselines and closely matching dedicated CLS token structure.
Application to Zero-Shot Segmentation and Generation
The DTMC attention framework produces immediate benefits for zero-shot segmentation. Multi-bounce attention maps, especially with second or third bounce, lead to more precise and semantically coherent segmentation masks, as demonstrated on ImageNet and COCO-Stuff-27 benchmarks. Notably, the combination of multi-bounce attention and λ2-weighted head aggregation outperforms prior state-of-the-art methods, as measured by mIoU and mAP metrics.

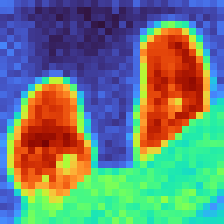
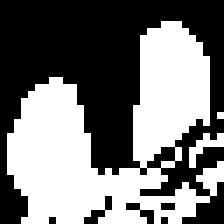



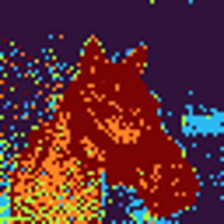



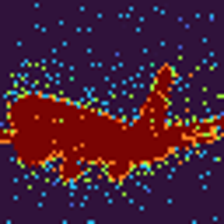

Figure 5: ImageNet segmentation results exhibit significant improvement and cleaner masks when utilizing higher-order (multi-bounce) attention.
Integrating TokenRank as a mask generator for self-attention guidance (SAG) in diffusion models (e.g., SD1.5) enhances both sample quality and diversity, as measured by inception score (IS) and FID/KID. Improved image structure and reduced artifacts are observed, both quantitatively and qualitatively.





Figure 6: Incorporating TokenRank into Self-Attention Guidance in diffusion models reduces artifacts and yields more structurally coherent generations.
The framework is also shown to boost the effectiveness of other segmentation methods (e.g., DiffSeg), when used for anchor/token selection.
Faithfulness and Head Weighting via λ2
A systematic token masking experiment demonstrates that masking tokens with highest TokenRank produces the greatest accuracy degradation across diverse ViT models (DINOv1, DINOv2, CLIP), indicating it is a superior global importance metric. This contrasts with centerpatch, CLS, or column-sum–based orderings.
λ2 provides a principled criterion for head weighting in aggregation operations: heads with higher λ2 contribute more reliable, metastable information, while low-λ2 heads are more prone to noise. Empirical results validate that λ2-based weighting achieves sharper attributions and improved segmentation performance compared to naive head averaging or random weighting.
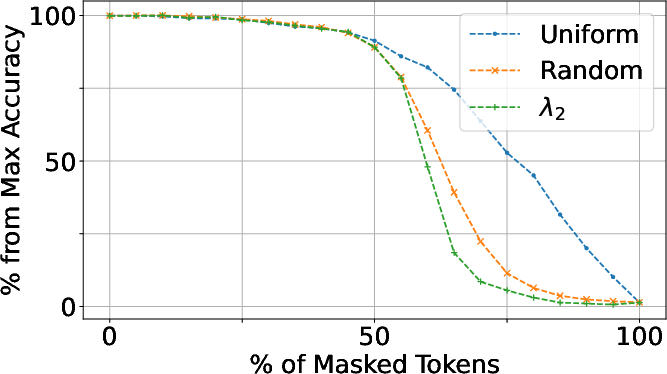
Figure 7: Head aggregation via λ2 weighting leads to greater drop in performance when important tokens are masked, reflecting stronger attribution fidelity.
Analysis and Qualitative Insights
The Markov chain perspective reveals key structural phenomena: for real images, repeated bounces consolidate attention into persistent regions; for random inputs or poorly trained models, the chain mixes rapidly with little structure. TokenRank visualizations are stable across diffusion denoising timesteps and trace meaningful semantic clusters (e.g., part segmentation and conditional masks).
Implications and Future Directions
The discrete-time Markov chain lens offers a mathematically principled, interpretable, and computationally efficient approach for both analysis and practical enhancement of visual transformer architectures. Several novel implications and directions can be enumerated:
- Unified interpretation: The framework subsumes and clarifies prior techniques for attention attribution and manipulation, providing a common ground for method comparison, ablation, and principled extension.
- Cross-domain applicability: While the study focuses on visual transformers, the abstraction is generic for any attention module. Extensions to text, video, and multimodal models are direct.
- Improved attributions and interventions: Faithful attribution methods based on higher-order effects can inform adversarial robustness, model debugging, and network surgery.
- Markovian diagnostics for model analysis: Metrics like λ2 and the spectral profile of attention matrices offer diagnostic tools for model structure, overfitting, or capacity; they may serve for regularization or architectural design.
- Limitations: The current instantiation is natural for square (self-attention) matrices; extension to cross-attention or non-square blocks may require augmenting the chain (e.g., with dummy or absorbing states).
Conclusion
In summary, viewing attention maps as DTMCs enables rigorous higher-order analysis of token interaction and importance—leading to improved interpretability, segmentation, and generation performance in transformers. The TokenRank steady state and λ2-weighted head fusion offer empirically validated, theoretically principled tools for attribution and global token ranking. The Markovian framework furnishes a foundation for both analytic understanding and practical manipulation of attention in deep learning systems, and points towards new methodology in model interpretation and intervention.