- The paper introduces a self-correction flywheel that iteratively improves VLN model performance by detecting deviations and generating correction data.
- The methodology employs deviation detection and domain randomization, achieving success rates of 65.1% and 69.3% on R2R-CE and RxR-CE benchmarks respectively.
- The results highlight robust navigation improvements in both simulated and real-world deployments, paving the way for advanced embodied intelligence.
CorrectNav: Empowering Vision-Language-Action Navigation Models
Introduction
The paper "CorrectNav: Self-Correction Flywheel Empowers Vision-Language-Action Navigation Model" (2508.10416) presents an innovative approach to improving Vision-Language Navigation (VLN) models by integrating self-correction capabilities. Traditional VLN models focus on enhancing visual perception and multimodal reasoning to navigate environments based on natural language instructions. However, the absence of effective error correction mechanisms often results in significant deviations from intended paths. CorrectNav addresses this limitation through a novel post-training paradigm referred to as the Self-correction Flywheel, enabling models to automatically generate self-correction data and iteratively enhance their performance.
Self-correction Flywheel Paradigm
CorrectNav's Self-correction Flywheel is conceptualized as a continuous loop comprising model evaluation, deviation detection, self-correction data generation, and continued training.
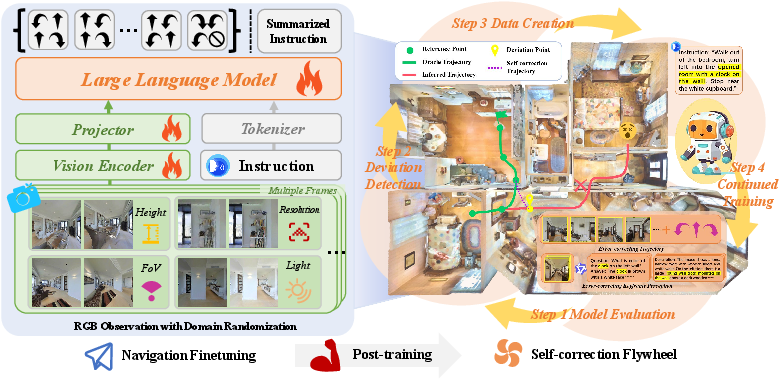
Figure 1: The overview of CorrectNav training. CorrectNav is first finetuned on the navigation tasks (Left), including action prediction and instruction generation. To enhance vision diversity, domain randomization strategies are implemented. Subsequently, the model undergoes Self-correction Flywheel post-training (Right), engaging in continuous evaluation and training cycles to improve error recovery.
Detailed Process
- Model Evaluation: The trained model is reevaluated on its training set to identify error trajectories. This step leverages incorrect paths as opportunities for model refinement rather than shortcomings.
- Deviation Detection: CorrectNav employs a method to detect deviations by measuring distances between error trajectories and true paths using interpolated reference points.
- Self-Correction Data Creation: The paradigm creates valuable correction data using identified deviations. For action correction, trajectories illustrating successful recovery are collected, while multimodal models analyze keyframes for perception correction.
- Continued Training: The model is refined using a blend of original training data and newly generated correction data, leading to progressive performance enhancements through multiple flywheel iterations.
Numerical Results and Comparative Analysis
CorrectNav achieves a state-of-the-art success rate of 65.1% on the R2R-CE and 69.3% on the RxR-CE benchmarks, significantly outperforming previous VLN models by margins of 8.2% and 16.4%, respectively.
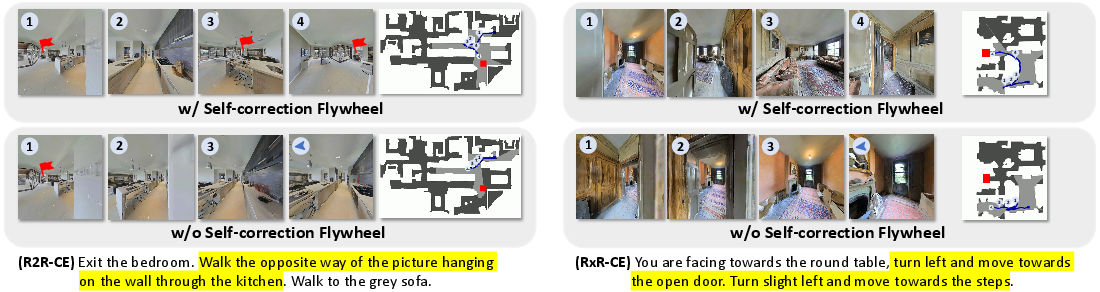
Figure 2: Case studies comparing CorrectNav with and without Self-correction Flywheel post-training illustrating enhanced path correction capabilities.
Effectiveness of Self-Correction Iterations
The paper highlights the quantitative improvements offered by CorrectNav through iterative flywheel training, showcasing increased success rates and reduced navigation errors across successive iterations.
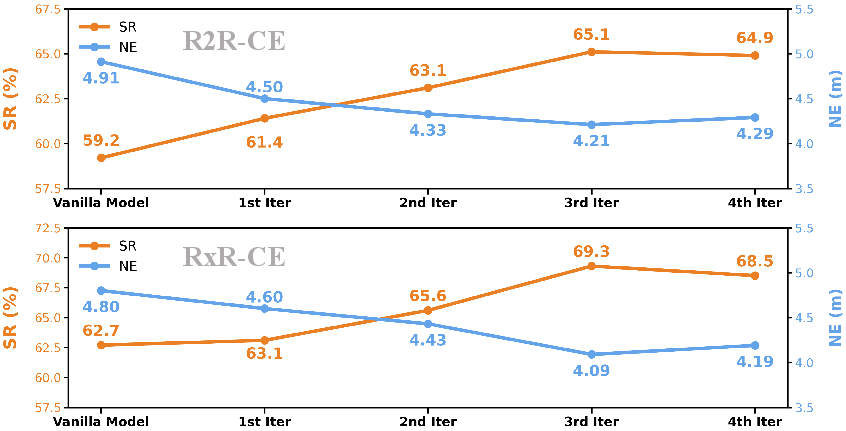
Figure 3: CorrectNav's performance on R2R-CE and RxR-CE Val-Unseen splits over Self-correction Flywheel iterations.
Real-world Deployment
CorrectNav's capabilities extend beyond simulated environments, showing superior performance in real-world scenarios, including complex indoor and outdoor navigation tasks. The model's dynamic obstacle avoidance and long-horizon instruction following are effectively demonstrated in robotic tests.

Figure 4: Qualitative results from the real-world deployment of CorrectNav, exhibiting robust navigation and error recovery in natural settings.
Implications and Future Directions
The introduction of self-correcting mechanisms in VLN models provides a substantial enhancement in robustness and efficiency, particularly in deployment scenarios requiring fast inference. CorrectNav serves as a promising step toward embodied intelligence with improved recovery capabilities. Future research aims to further enrich navigation models by integrating robotic dimension and state information as prior knowledge, potentially reducing navigation discrepancies attributed to monocular RGB sensing limitations.
Conclusion
CorrectNav embodies a significant advancement in VLN by embedding error correction into the core of model operation. Its Self-correction Flywheel not only fosters performance improvements but also equips models with the ability to autonomously adapt to unforeseen challenges in the navigation task. These attributes lay the groundwork for future exploration and development in vision-language-action models and their applications in real-world environments.

