ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents
Abstract: We introduce ComputerRL, a framework for autonomous desktop intelligence that enables agents to operate complex digital workspaces skillfully. ComputerRL features the API-GUI paradigm, which unifies programmatic API calls and direct GUI interaction to address the inherent mismatch between machine agents and human-centric desktop environments. Scaling end-to-end RL training is crucial for improvement and generalization across diverse desktop tasks, yet remains challenging due to environmental inefficiency and instability in extended training. To support scalable and robust training, we develop a distributed RL infrastructure capable of orchestrating thousands of parallel virtual desktop environments to accelerate large-scale online RL. Furthermore, we propose Entropulse, a training strategy that alternates reinforcement learning with supervised fine-tuning, effectively mitigating entropy collapse during extended training runs. We employ ComputerRL on open models GLM-4-9B-0414 and Qwen2.5-14B, and evaluate them on the OSWorld benchmark. The AutoGLM-OS-9B based on GLM-4-9B-0414 achieves a new state-of-the-art accuracy of 48.1%, demonstrating significant improvements for general agents in desktop automation. The algorithm and framework are adopted in building AutoGLM (Liu et al., 2024a)
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
ComputerRL: Teaching AI to Use a Computer Like a Skilled Assistant
1. What is this paper about?
This paper is about building an AI “computer helper” that can use a desktop computer on its own—opening apps, clicking buttons, typing, editing files, and more—to complete real tasks. The authors introduce a system called ComputerRL that trains these helpers to work better and faster by practicing on thousands of virtual computers at the same time.
2. What questions did the researchers ask?
The team focused on three big questions:
- How can an AI control a computer efficiently when the screen and mouse are designed for humans, not machines?
- How can we train the AI at scale so it gets better across many different apps and tasks?
- How can we keep the AI improving during long training runs, instead of getting stuck doing the same thing over and over?
3. How did they do it?
The researchers built a complete training setup with three key ideas. Here’s the gist, using everyday comparisons:
- API-GUI: two ways to control the computer
- GUI actions are like moving a mouse and typing on a keyboard.
- APIs are like special remote-control commands that apps understand directly.
- The paper combines both: the AI uses the GUI when needed (like a human) and uses APIs when they’re faster and safer (like shortcuts). They even use AI to help auto-build these APIs for apps by analyzing examples and generating code and tests.
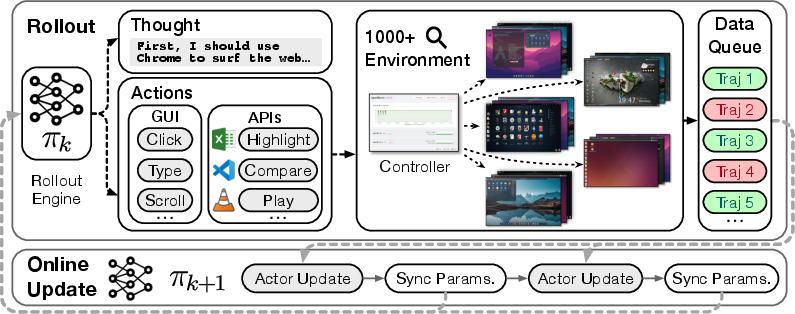
- A giant practice room made of virtual computers
- They run thousands of “pretend” Ubuntu desktops (virtual machines) in parallel—like setting up a massive gym full of practice stations.
- These desktops are organized with efficient tools (Docker, gRPC) so training is stable and fast.
- A web dashboard lets them monitor what’s happening and keep everything running smoothly.
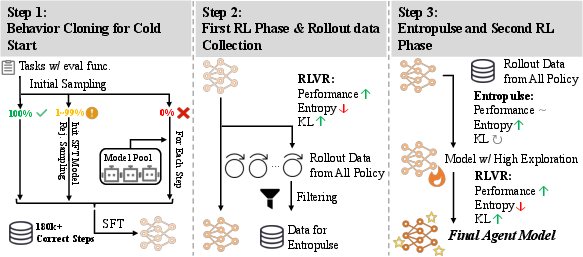
- How the AI learns: first copy, then practice with feedback
- Behavior Cloning (BC): First, the AI learns by copying good examples—like a student watching and imitating experts. They collect many successful task recordings using several strong LLMs, filter for success, and fine-tune the student model.
- Reinforcement Learning (RL): Next, the AI practices and gets feedback—like a coach giving points for good plays. They use clear, automatic “checkers” to decide if a task was done correctly (verifiable rewards).
- Step-level GRPO: A training method that assigns credit step by step inside each task. Imagine scoring each move in a game, not just the final win or loss. This helps the AI learn which exact actions helped.
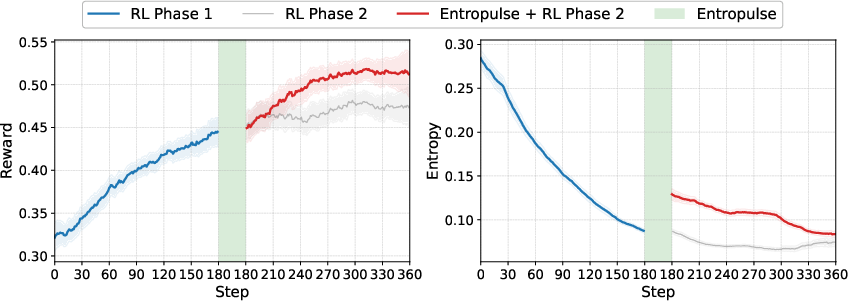
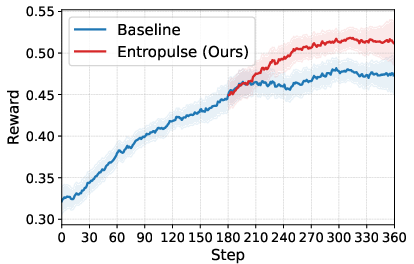
- Entropulse: keeping the AI curious so it doesn’t get stuck
- “Entropy” here means how much the AI explores different options. After long RL training, the AI can get too predictable and stop exploring—that’s bad for learning.
- Entropulse fixes this by switching between RL and short bursts of supervised fine-tuning (SFT) using the AI’s own successful past attempts. It’s like taking a break to review the best plays, which refreshes the AI’s curiosity and helps it try new strategies again.
4. What did they find, and why is it important?
Main results:
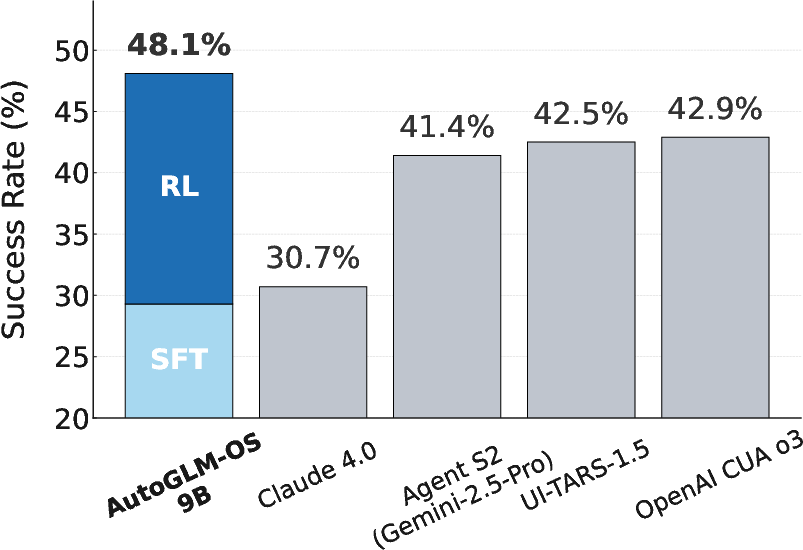
- New state of the art on OSWorld, a tough benchmark for desktop tasks
- Their 9B-parameter model (AutoGLM-OS-9B, based on GLM-4-9B-0414) reaches 48.1% success, beating strong systems like OpenAI’s CUA o3 (42.9%).
- A 14B-parameter version (with Qwen2.5-14B) also performs very well (~45.8%).
- Big improvements from the API-GUI combo
- Using both APIs and GUI actions beats GUI-only by a large margin, especially in complex office and professional tasks.
- The agent often needs only about one-third as many steps to finish a task compared to other approaches—so it’s more efficient.
- Scaling up training works
- Their large, stable virtual desktop cluster lets them train faster and more reliably.
- Entropulse keeps the AI exploring longer, boosting final performance compared to training without it.
Why this matters:
- It shows we can train general-purpose computer agents that actually work across many apps and workflows.
- The approach makes desktop automation more practical, accurate, and efficient.
5. What’s the impact and what comes next?
This research pushes AI closer to being a trustworthy digital assistant that can:
- Help with real office work (documents, spreadsheets, images).
- Coordinate across multiple apps smoothly.
- Learn new tools over time.
The authors also point to future needs:
- Robustness: handling new apps, pop-ups, and unusual cases reliably.
- Long-horizon autonomy: managing long, multi-step projects from start to finish.
- Safety and alignment: adding strong permission systems and checks so the agent acts safely when it can access files or sensitive data.
In short, ComputerRL shows a practical path to training AI that can use computers like skilled assistants—faster, safer, and smarter—by mixing better ways to act (API + GUI), bigger and more stable practice setups (many virtual desktops), and smarter training (Entropulse to keep learning going).
Collections
Sign up for free to add this paper to one or more collections.