- The paper presents GUI-Owl as a unified policy network for multimodal GUI automation, achieving state-of-the-art results across benchmark suites.
- It introduces a modular multi-agent framework (Mobile-Agent-v3) that decomposes tasks into Manager, Worker, Reflector, and Notetaker roles for cross-platform efficiency.
- The work pioneers a self-evolving trajectory data pipeline and scalable reinforcement learning for continuous improvement and long-horizon reasoning.
Mobile-Agent-v3: Foundational Agents for GUI Automation
Introduction and Motivation
The paper presents GUI-Owl, a foundational multimodal agent for GUI automation, and the Mobile-Agent-v3 framework, which extends GUI-Owl into a modular, multi-agent system for robust automation across desktop and mobile environments. The work addresses the limitations of prior closed-source and end-to-end models, which either lack generalization to unseen tasks or fail to integrate with diverse agentic frameworks. GUI-Owl is designed to unify perception, grounding, reasoning, planning, and action execution within a single policy network, supporting both autonomous and collaborative multi-agent operation.
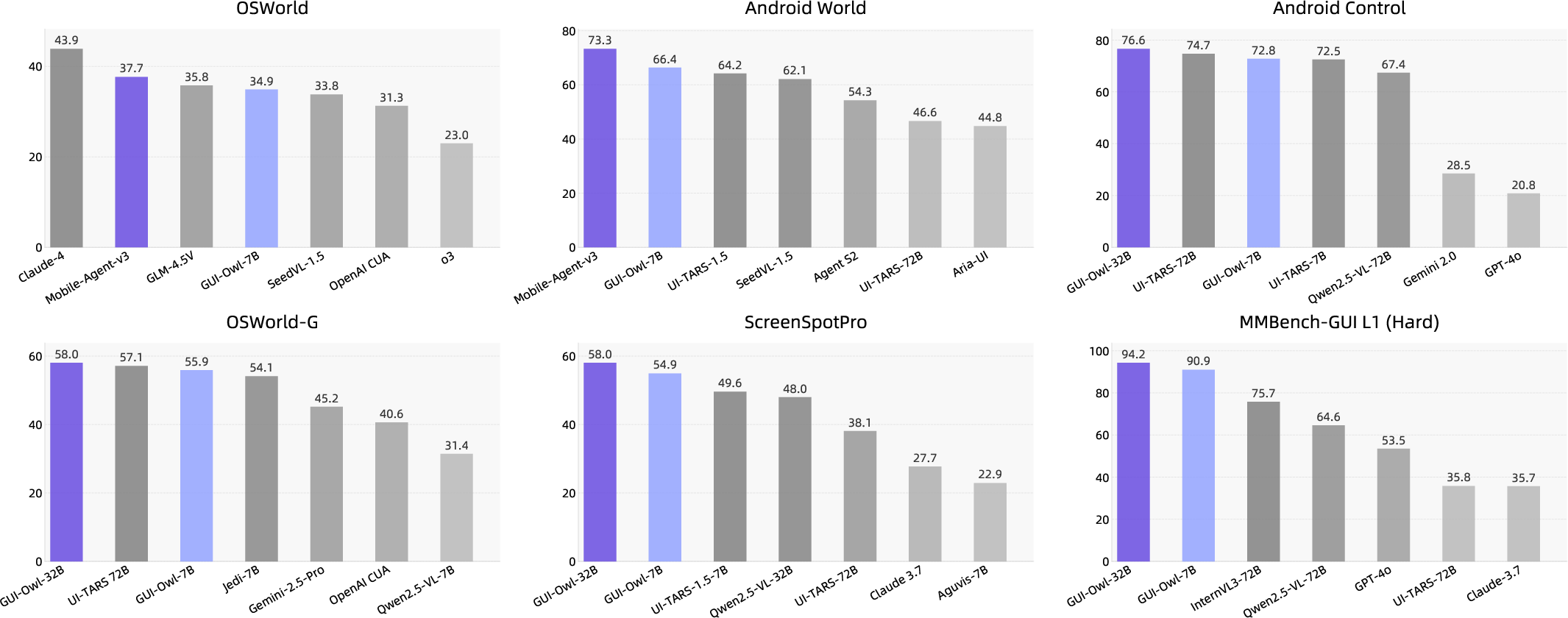
Figure 1: Performance overview on mainstream GUI-automation benchmarks.
GUI-Owl achieves state-of-the-art results on ten GUI benchmarks, including AndroidWorld (66.4 for GUI-Owl-7B, 73.3 for Mobile-Agent-v3) and OSWorld (29.4 for GUI-Owl-7B, 37.7 for Mobile-Agent-v3), outperforming both open-source and proprietary models of comparable size.
System Architecture and Agentic Framework
Mobile-Agent-v3 is a multi-agent framework that decomposes complex GUI tasks into modular roles: Manager, Worker, Reflector, and Notetaker, coordinated via a shared device interface and external knowledge retrieval (RAG). The Manager agent performs strategic planning and subgoal decomposition, the Worker agent executes GUI actions, the Reflector agent provides feedback and self-correction, and the Notetaker agent maintains persistent contextual memory.
Figure 2: Overview of Mobile-Agent-v3, illustrating multi-platform support and core agentic capabilities.
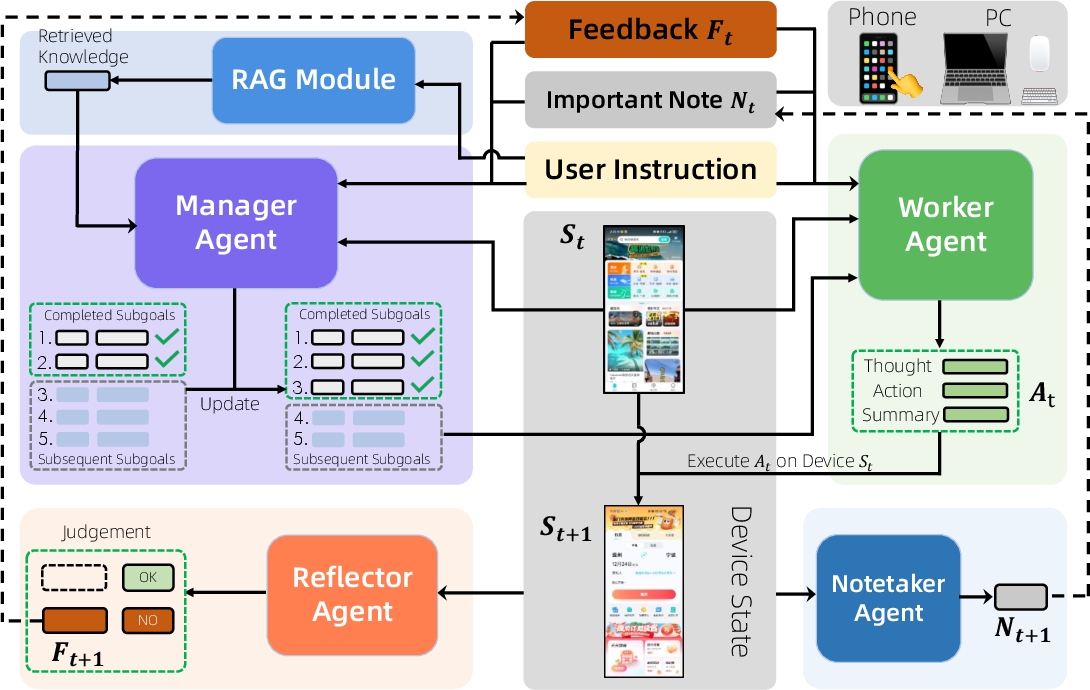
Figure 3: Mobile-Agent-v3 architecture, detailing the six core modules and their interactions.
The framework supports both phone and PC environments, enabling cross-platform automation. The agents communicate via structured messages containing task instructions, compressed histories, and current observations, with explicit reasoning and action summaries at each step.
End-to-End GUI Interaction and Reasoning
GUI-Owl models GUI interaction as a multi-turn decision process, where the policy π maps the current observation and history to a distribution over the action space. The interaction flow is organized into system messages (action space), user messages (task, history, observation), and response messages (reasoning, action summary, output).
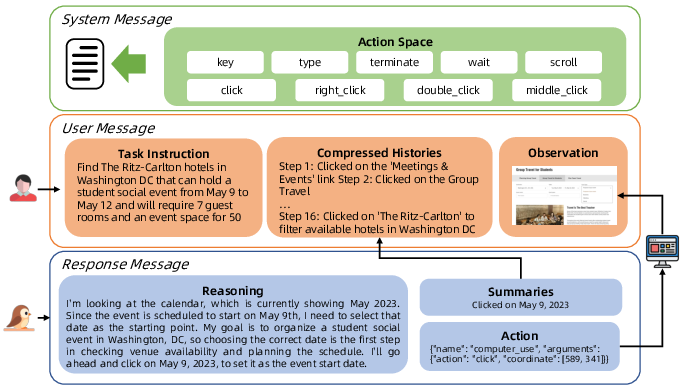
Figure 4: Interaction flow of GUI-Owl, showing the structured message exchange and reasoning process.
The model supports flexible prompts and explicit intermediate reasoning, which improves adaptation to complex tasks. Only concise conclusions are stored in history to manage context length and inference speed.
Self-Evolving Trajectory Data Production
A key innovation is the self-evolving trajectory data production pipeline, which leverages GUI-Owl's own rollouts to generate high-quality interaction data, reducing manual annotation and enabling continuous self-improvement. The pipeline includes dynamic environment construction, high-quality query generation, trajectory correctness judgment, and query-specific guidance synthesis.
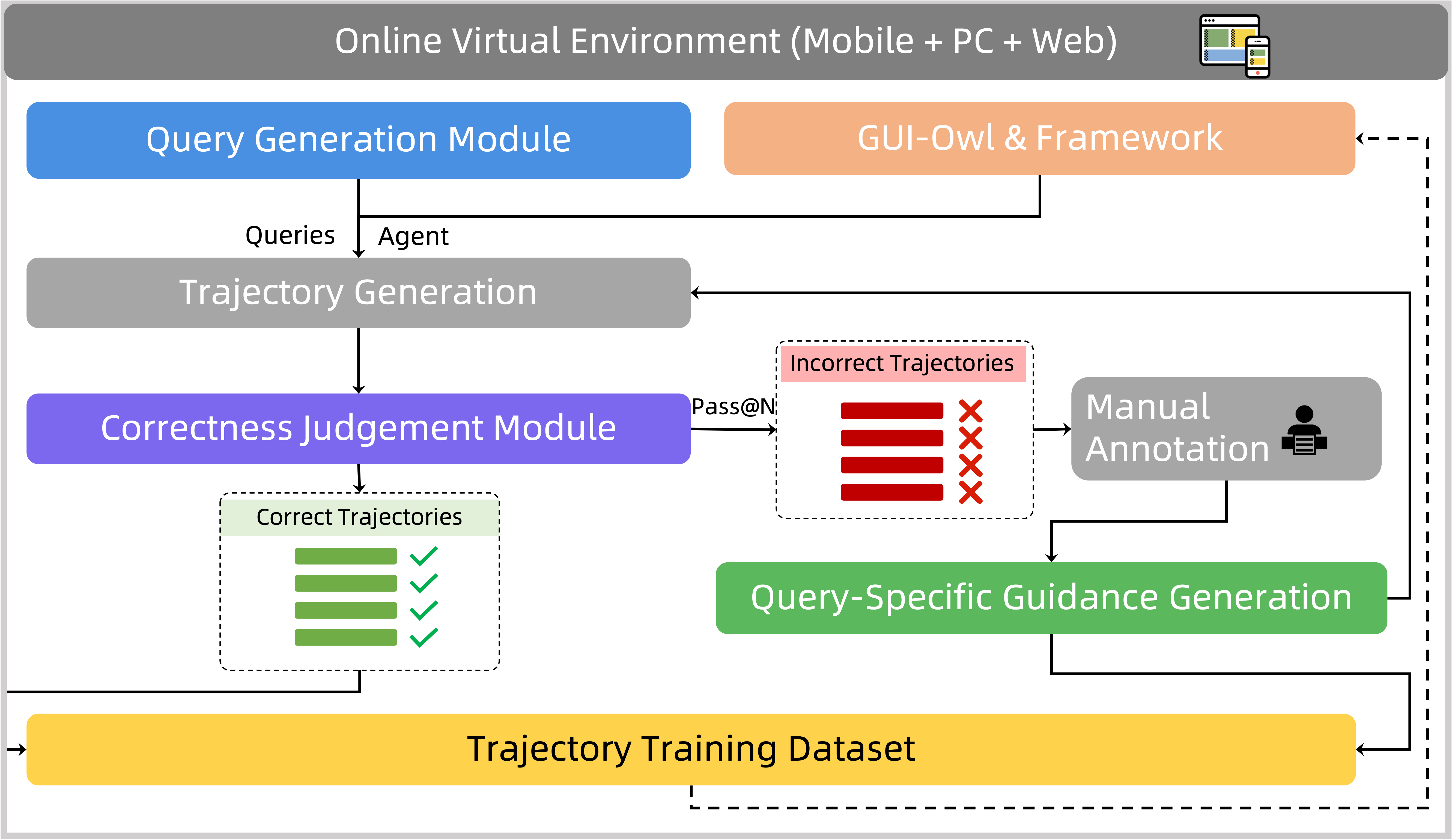
Figure 5: Self-evolving trajectory data production pipeline for scalable, high-quality data generation.
The trajectory correctness module employs step-level and trajectory-level critics, combining textual and multimodal reasoning channels for robust evaluation. Query-specific guidance is synthesized from successful trajectories using VLMs and LLMs, further improving data diversity and model robustness.
Grounding, Planning, and Action Semantics
GUI-Owl's foundational capabilities are enhanced via diverse data synthesis pipelines for grounding (UI element localization, fine-grained word/character grounding), task planning (distillation from historical trajectories and LLMs), and action semantics (before/after state analysis).
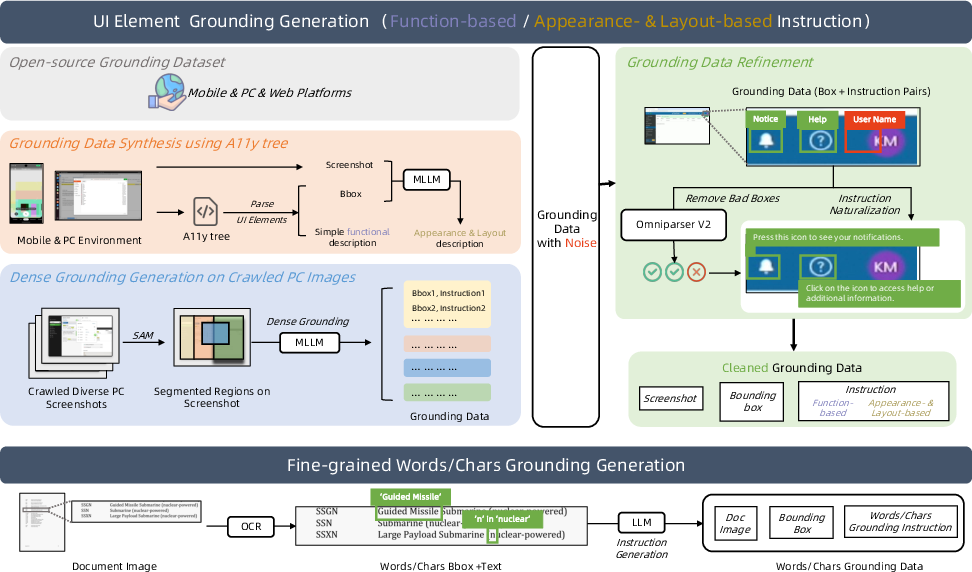
Figure 6: Grounding data construction pipeline, integrating multiple data sources and annotation strategies.
Grounding data is cleaned using detection results and rephrased for naturalness. Planning data is constructed from both historical trajectories and LLM-generated complex tasks. Action semantics are annotated via multimodal models and voting for consistency.
Scalable Reinforcement Learning Infrastructure
The training paradigm consists of pre-training, iterative tuning, and reinforcement learning phases. The RL infrastructure is fully asynchronous, decoupling rollout from policy updates, and supports both single-turn and multi-turn agentic tasks. Trajectory-aware Relative Policy Optimization (TRPO) is introduced for long-horizon, sparse-reward environments, using trajectory-level rewards and replay buffers for stability.
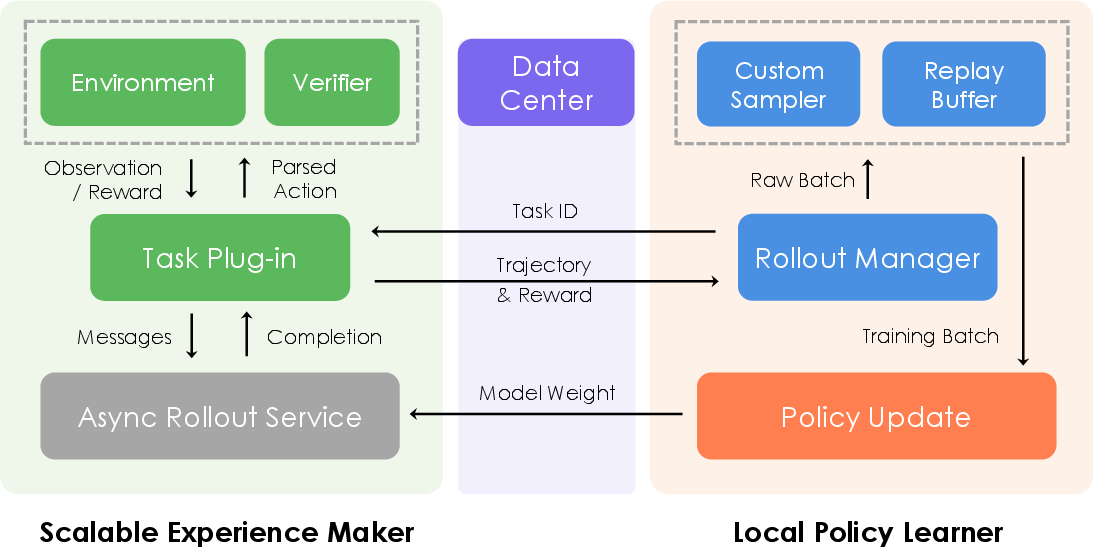
Figure 7: Scalable RL infrastructure, enabling parallel rollout and update for high-throughput agentic training.
TRPO computes normalized advantages for entire trajectories and distributes them uniformly across steps, mitigating credit assignment issues. Replay buffers inject successful trajectories to stabilize learning in sparse-reward settings.
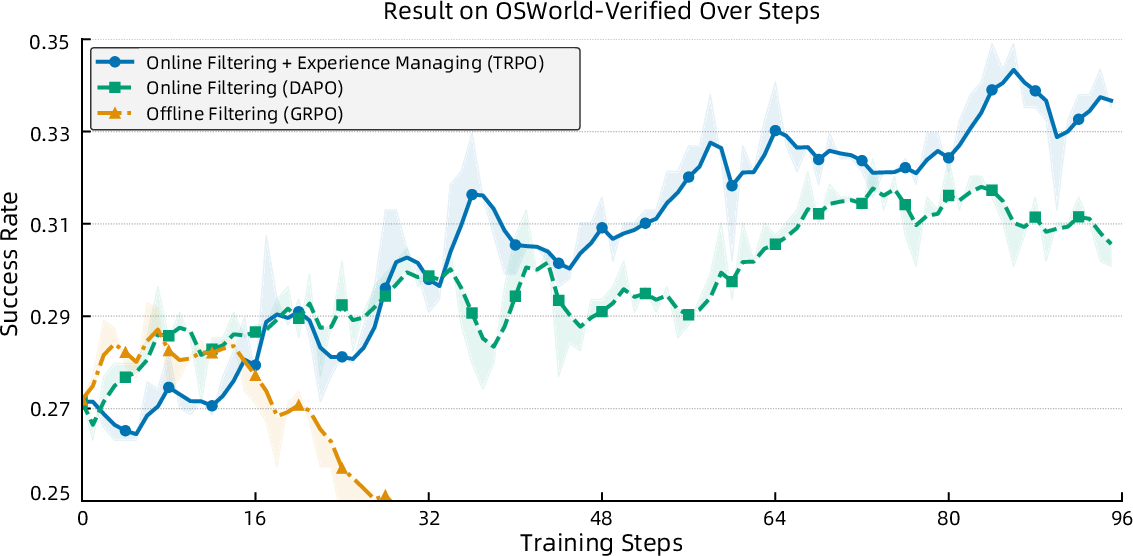
Figure 8: Training dynamics of GUI-Owl-7B on OSWorld-Verified, comparing offline and online filtering strategies.
Empirical Results and Analysis
GUI-Owl-7B and GUI-Owl-32B achieve state-of-the-art results across grounding, GUI understanding, and end-to-end agentic benchmarks. On MMBench-GUI-L2, GUI-Owl-7B scores 80.49, and GUI-Owl-32B scores 82.97, outperforming all existing models. On Android Control, GUI-Owl-32B achieves 76.6, surpassing UI-TARS-72B. In online environments, Mobile-Agent-v3 achieves 73.3 on AndroidWorld and 37.7 on OSWorld, demonstrating superior multi-agent adaptability.
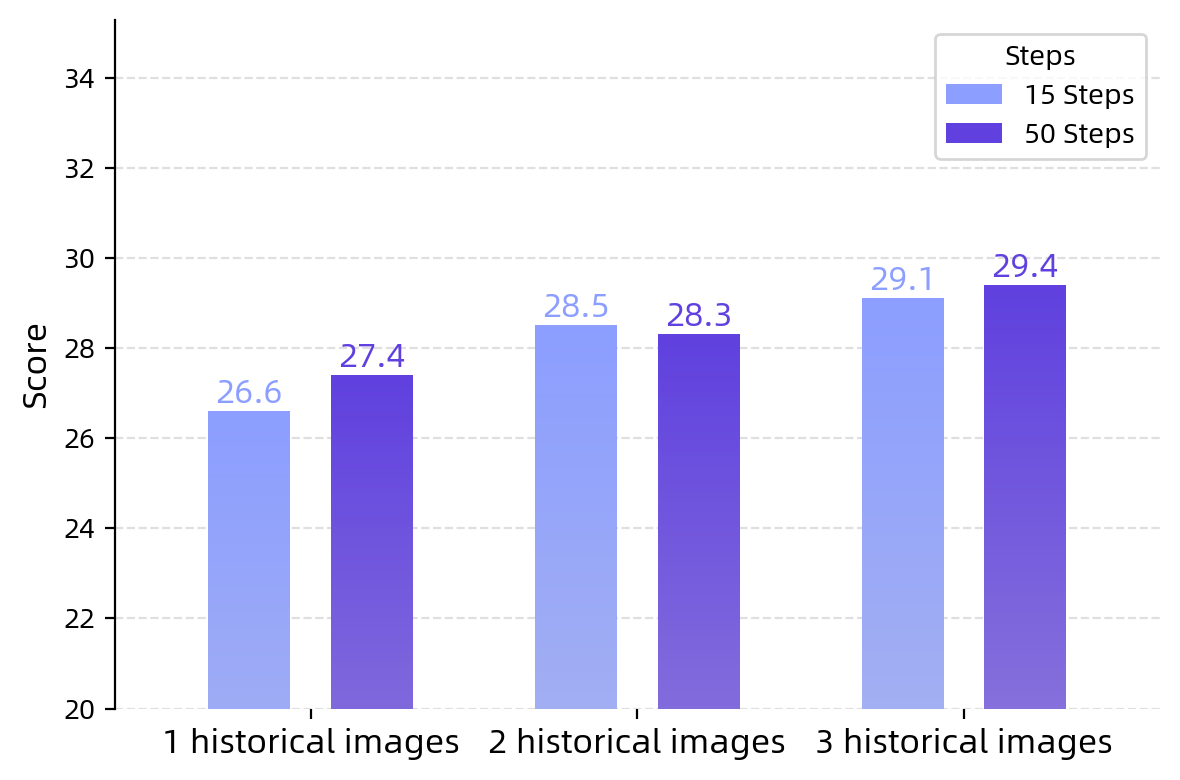
Figure 9: Performance scaling of GUI-Owl-7B on OSWorld-Verified with varying historical images and step budgets.
Performance improves with increased historical context and interaction steps, indicating strong long-horizon reasoning capability.
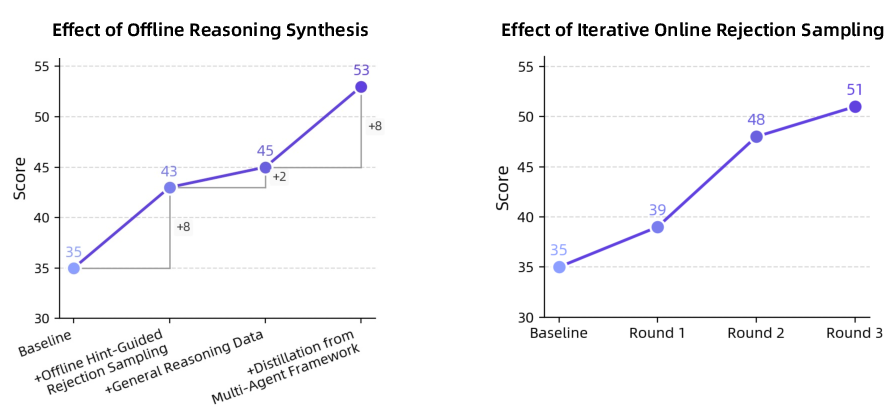
Figure 10: Effect of reasoning data synthesis on Android World, showing incremental gains from diverse reasoning sources.
Iterative training with synthesized reasoning data yields sustained improvements, highlighting the importance of reasoning diversity and online data generation.
Agentic Workflow and Case Study
The integrated workflow of Mobile-Agent-v3 is formalized as a cyclical process, with agents updating plans, executing actions, reflecting on outcomes, and persisting critical information. The system terminates upon task completion or execution stalemate.

Figure 11: Case study of a complete Mobile-Agent-v3 operation on desktop, illustrating manager, worker, and reflector outputs.
The case study demonstrates dynamic subgoal updating, error correction via reflection, and successful task completion through agent cooperation.
Implications and Future Directions
The modular, self-evolving architecture of Mobile-Agent-v3 and GUI-Owl establishes a robust foundation for general-purpose GUI automation. The integration of scalable RL, explicit reasoning, and multi-agent collaboration enables adaptation to complex, dynamic environments. The strong empirical results, particularly the ability to surpass proprietary models with open-source architectures, suggest that further scaling of data, reasoning diversity, and agentic specialization will continue to advance the field.
Potential future directions include:
- Extending agentic frameworks to more heterogeneous device ecosystems and web platforms.
- Incorporating more sophisticated external knowledge retrieval and tool-use capabilities.
- Exploring hierarchical agentic structures for even longer-horizon and multi-modal workflows.
- Investigating transfer learning and domain adaptation for rapid deployment in novel environments.
Conclusion
Mobile-Agent-v3 and GUI-Owl represent a significant advancement in foundational agents for GUI automation, combining end-to-end multimodal modeling, self-evolving data pipelines, and scalable multi-agent frameworks. The demonstrated performance and adaptability across diverse benchmarks and environments provide a strong basis for future research in generalist, agentic AI systems for real-world automation.