UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
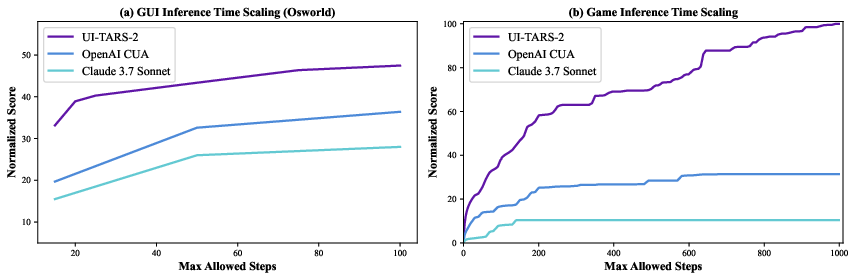
Abstract: The development of autonomous agents for graphical user interfaces (GUIs) presents major challenges in artificial intelligence. While recent advances in native agent models have shown promise by unifying perception, reasoning, action, and memory through end-to-end learning, open problems remain in data scalability, multi-turn reinforcement learning (RL), the limitations of GUI-only operation, and environment stability. In this technical report, we present UI-TARS-2, a native GUI-centered agent model that addresses these challenges through a systematic training methodology: a data flywheel for scalable data generation, a stabilized multi-turn RL framework, a hybrid GUI environment that integrates file systems and terminals, and a unified sandbox platform for large-scale rollouts. Empirical evaluation demonstrates that UI-TARS-2 achieves significant improvements over its predecessor UI-TARS-1.5. On GUI benchmarks, it reaches 88.2 on Online-Mind2Web, 47.5 on OSWorld, 50.6 on WindowsAgentArena, and 73.3 on AndroidWorld, outperforming strong baselines such as Claude and OpenAI agents. In game environments, it attains a mean normalized score of 59.8 across a 15-game suite-roughly 60% of human-level performance-and remains competitive with frontier proprietary models (e.g., OpenAI o3) on LMGame-Bench. Additionally, the model can generalize to long-horizon information-seeking tasks and software engineering benchmarks, highlighting its robustness across diverse agent tasks. Detailed analyses of training dynamics further provide insights into achieving stability and efficiency in large-scale agent RL. These results underscore UI-TARS-2's potential to advance the state of GUI agents and exhibit strong generalization to real-world interactive scenarios.
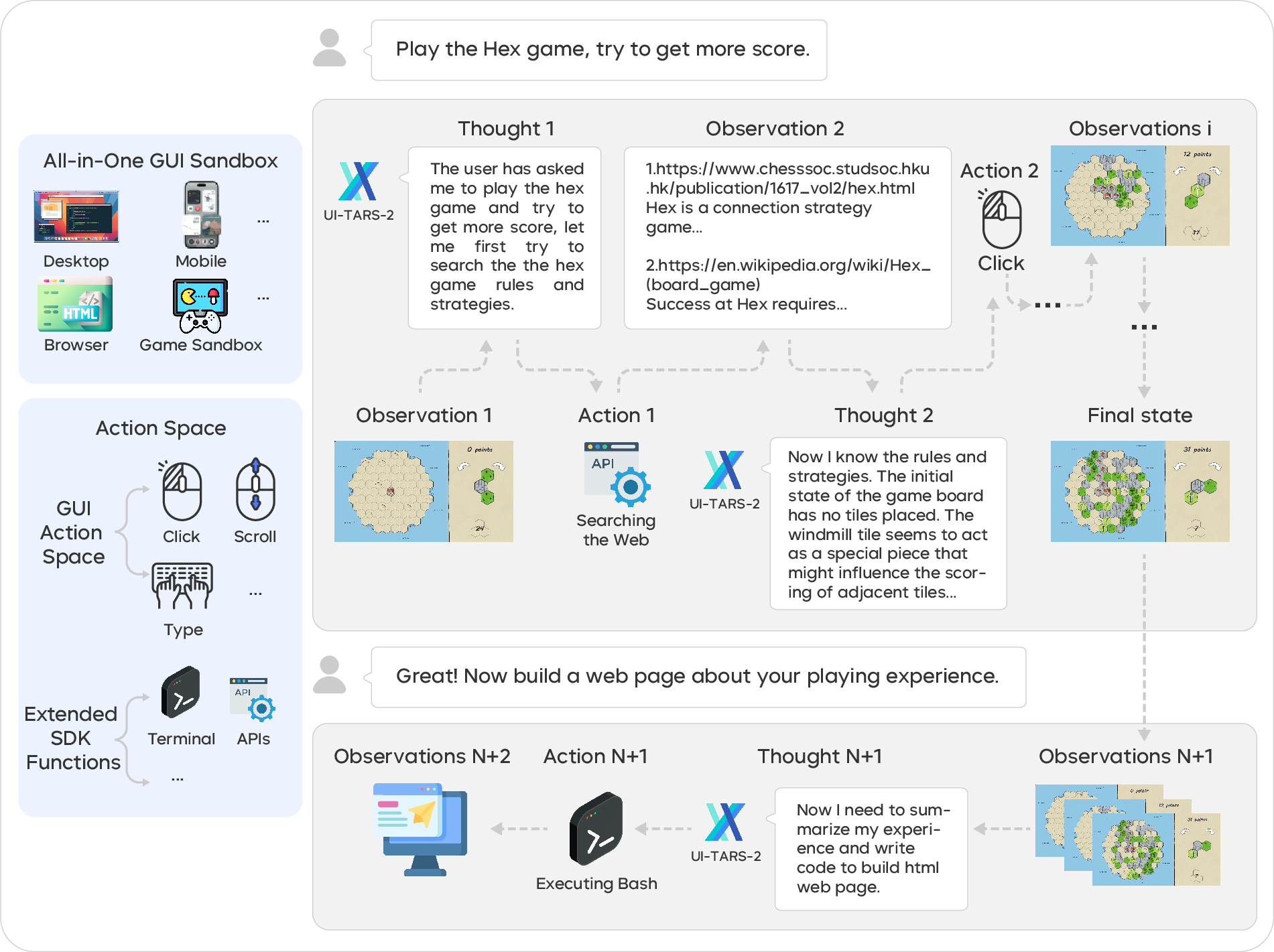

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces UI-TARS-2, a smart computer helper (an “agent”) that can use apps and websites by seeing the screen, thinking, and then clicking, typing, or using tools—much like a person. The goal is to make an AI that can handle long, multi-step tasks on real computers and phones, not just answer text questions. The team built new ways to collect training data, new training methods so the agent learns safely from trial and error, and a “sandbox” (a safe practice playground) where the agent can practice millions of times.
What questions did the paper ask?
Here are the main problems the paper tried to solve in simple terms:
- How can we get enough good training data for an AI that needs to act over many steps on a computer screen?
- How can we train the AI with trial-and-error learning (reinforcement learning) without it becoming unstable or confused on long tasks?
- How can we help the AI do more than just click and type—like using files, terminals, and tools—so it can solve real-world jobs?
- How can we run huge numbers of safe, reliable practice sessions so the AI gets better quickly?
How did they build and train the agent?
The researchers combined several ideas to make UI-TARS-2 stronger and more reliable.
A “data flywheel” that keeps improving
Think of a flywheel as a spinning wheel that keeps gaining momentum. The team:
- Starts with a base model that already knows a lot.
- Has the model try tasks and generate new examples.
- Keeps the best examples as high-quality lessons and uses the rest as broader practice material.
- Trains the model again on this improved data—and repeats the cycle. Over time, better models create better data, which creates even better models.
To get realistic data:
- They recorded real people using computers while “thinking out loud,” then turned the speech into text to capture both actions and reasoning.
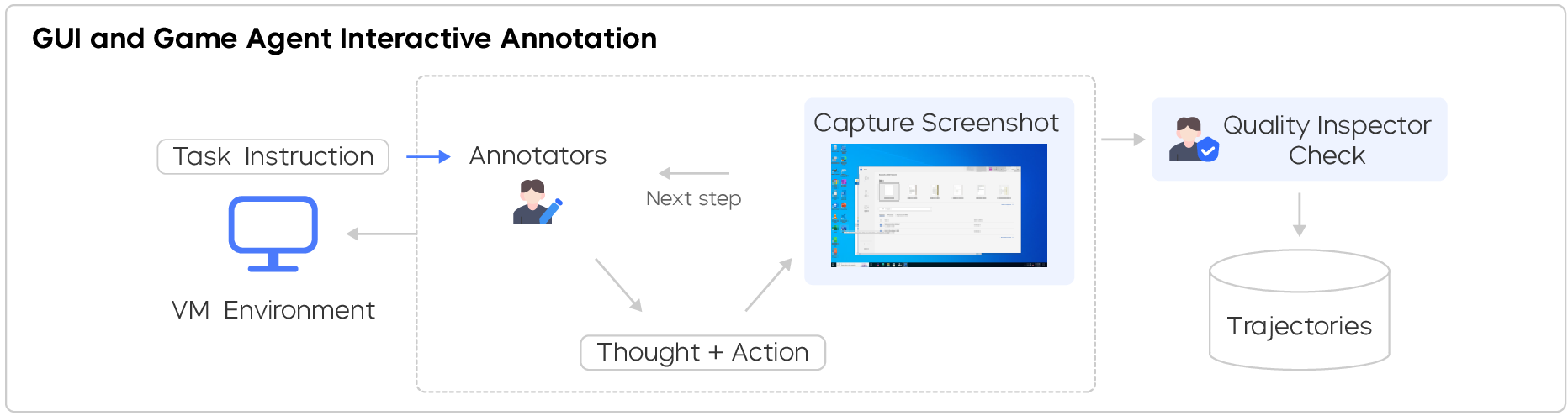
- They also built an interactive system where a human can watch the AI in real time and nudge it when it makes mistakes, so the AI learns from the kinds of situations it actually gets itself into.
Practicing safely at scale
They built big “sandboxes” where the agent can practice:
- Virtual computers in the cloud (Windows, Ubuntu, Android) for GUI tasks—like a huge computer lab the AI can log into.
- A fast, GPU-accelerated browser “game gym” for practicing web games with accurate screenshots, clicks, and timing.
- A shared file system and terminal access, so the AI can also copy files, run commands, or use tools when that’s the easiest way to solve a task.
These sandboxes are designed to be stable (few crashes), reproducible (you get the same setup each time), and scalable (you can run millions of practice sessions).
Learning from many-step tasks (multi-turn reinforcement learning)
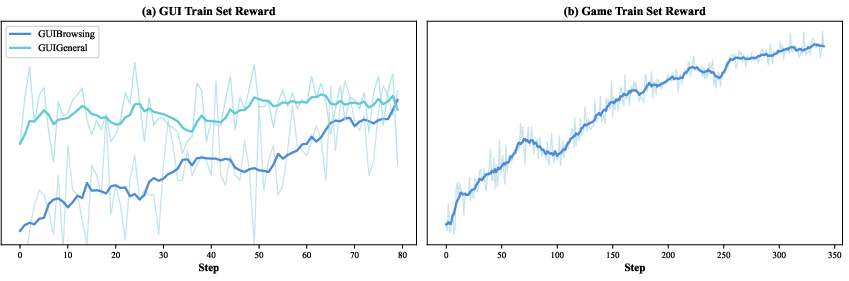
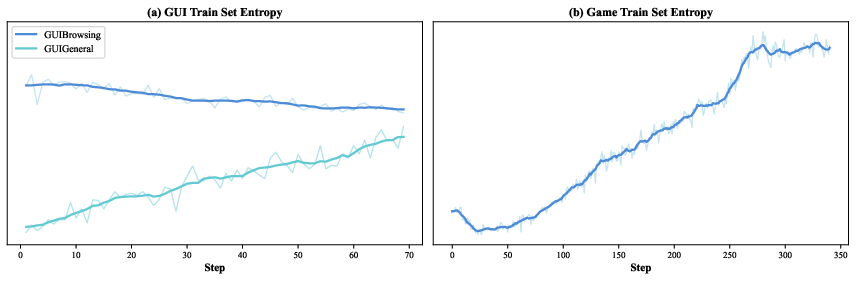
Reinforcement learning (RL) is like training a player: it tries actions, sees what happens, and gets a reward when it succeeds. Long, multi-step computer tasks are hard because rewards often come late and training can get unstable. The team made RL more stable by:
- Using verifiable rewards: clear “win” checks for games, answer checks for info-seeking tasks, or an AI “referee” to judge success when there’s no exact answer.
- Running practice sessions asynchronously, so slow, tricky tasks don’t block progress.
- Starting training as soon as a reasonable batch of examples is ready (instead of waiting for everything), to keep learning continuous.
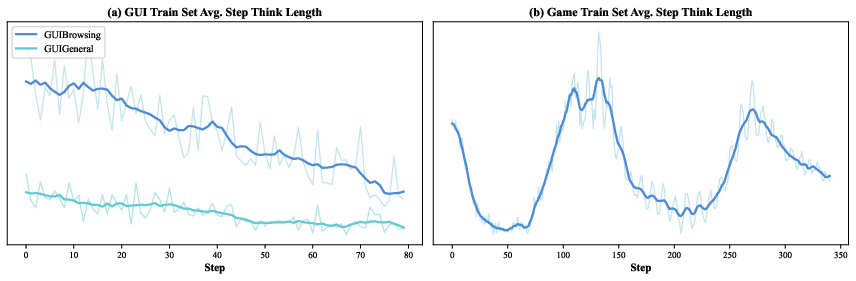
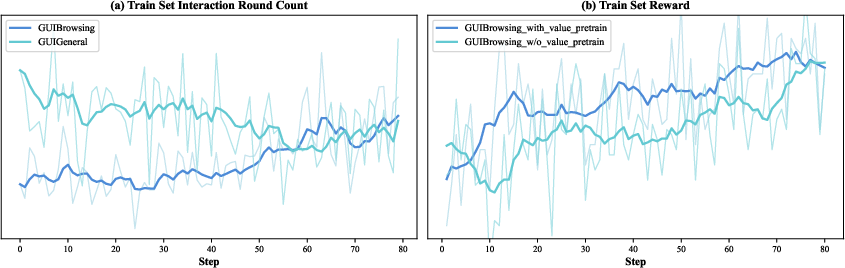
- Tuning the math under the hood so the model doesn’t get confused by very long action sequences (for example, better “advantage” estimation and pretraining the value function, which is like teaching the scorekeeper to be accurate before the game gets complex).
In simple terms: they redesigned the “coach, player, and scoreboard” so the player can learn from long games without getting stuck or misled.
Mixing specialists into one all-rounder
They trained several specialist versions of the agent—one great at browsing for information, one at general GUI tasks, one at games, and one that’s good with system tools. Then they blended these models’ “skills” together (by interpolating their parameters) to create a single well-rounded agent, without redoing all the training at once.
What did the experiments show?
Across many tests, UI-TARS-2 outperformed earlier versions and strong competitors:
- On computer and phone tasks (like using Windows, Android apps, or websites), it beat previous UI-TARS and often beat well-known AI agents from other companies.
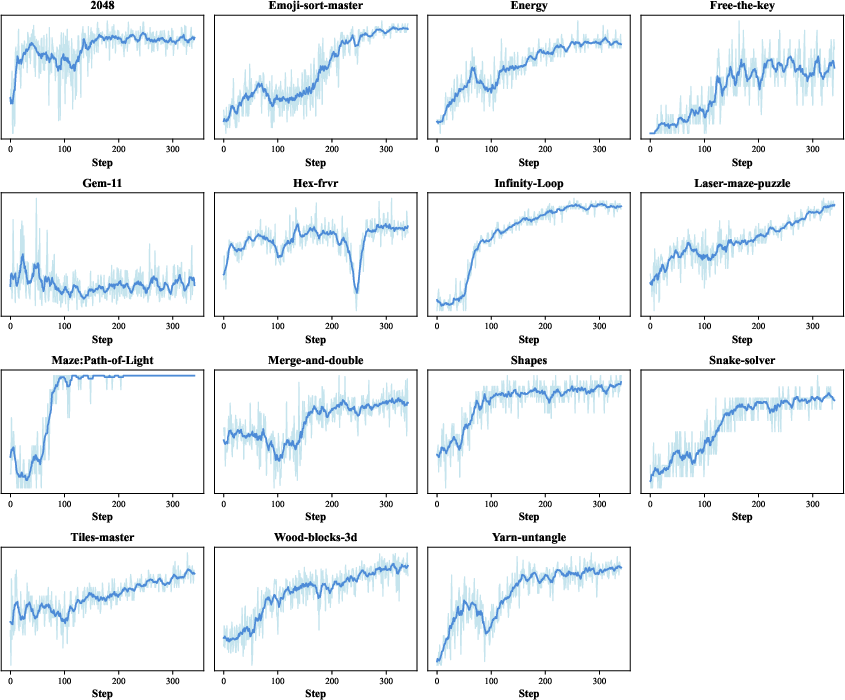
- On 15 different web games, it reached about 60% of human-level performance on average—impressive for screenshot-only play using clicks and keys.
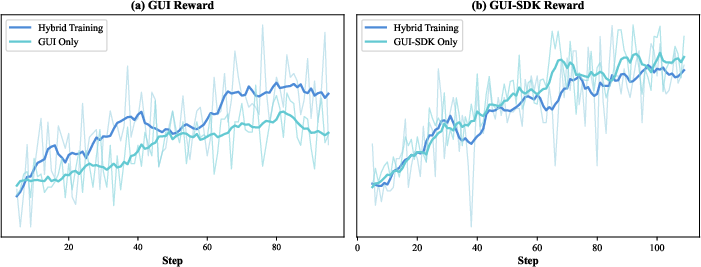
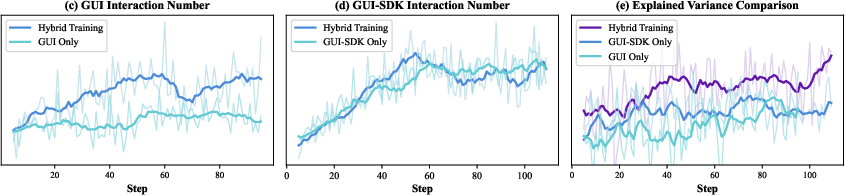
- With access to files and terminals (not just on-screen clicking), it handled tougher jobs like command-line tasks and software bug fixing, and it did much better on long, complex web research tasks.
- It generalized well: skills learned for GUIs and games also helped on information-seeking and software engineering tasks.
Why this matters: these results suggest the methods—especially the stable multi-step RL, the data flywheel, and the hybrid sandbox—really do build more capable, reliable agents.
Why it matters
- More practical computer helpers: Instead of only chatting, these agents can actually operate a computer—browse the web, manage files, use apps, and even fix code—step by step.
- Better training recipe: The paper shows a workable path to train agents on long, real tasks without the training falling apart.
- Scales to real life: The sandbox platform makes it possible to run massive amounts of practice in realistic environments, which is key for steady improvement.
- Broad impact: The same ideas (data flywheel, stable multi-turn RL, hybrid environments) can help build agents for office work, research, education, and software development.
In short, UI-TARS-2 is a big step toward AI that can “use a computer like a person,” and the training blueprint it provides could help many future agents learn faster, handle longer tasks, and work more reliably in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved questions that future work could address:
- Data flywheel specifics and reproducibility
- Missing quantitative details on data volumes, domain/task distributions, and iteration cadence across CT/SFT/RL (e.g., number of trajectories per cycle, acceptance rates, and validator thresholds), hindering replication and ablation.
- The validation function V(s)→{0,1} and rejection sampling criteria are under-specified (who/what judges, reliability metrics, inter-rater agreement), making selection bias and noise levels unclear.
- No analysis of contamination risks from web-scraped tutorials/demonstrations or how overlap with evaluation benchmarks is prevented.
- In-situ annotation pipeline
- Ethical, privacy, and security safeguards for collecting think-aloud data on annotators’ personal machines are not detailed (PII handling, opt-outs, consent, data retention, redaction).
- ASR quality, alignment accuracy between audio thoughts and UI actions, and their impact on downstream learning are not quantified; no robustness analysis to transcription errors.
- Lack of cost, throughput, and annotator agreement statistics; no study on expert vs. novice data contributions (which improves what, at what cost?).
- Interactive SFT (on-policy supervision)
- No controlled comparison of interactive SFT versus post-hoc correction SFT (sample efficiency, generalization, failure recovery).
- Unclear safeguards against annotator bias and drift when the model proposes actions (risk of confirmation bias toward current policy).
- How the platform prioritizes tasks to target current weaknesses (curriculum design) is not specified or validated.
- Multi-turn RL design and stability
- PPO objective appears malformed in the text (missing parentheses/syntax), and key hyperparameters (clip ranges, target KL, entropy bonus, LR schedules, batch sizes, rollout horizons) are not reported.
- No ablations isolating the contribution of Decoupled-GAE, Length-Adaptive GAE, reward shaping, Value Pretraining, and “Clip Higher” to stability and performance across domains.
- Asynchronous rollouts with partially filled pools may introduce bias/off-policy effects; no analysis of how this impacts credit assignment and convergence.
- Long-horizon stability limits are unclear (max step counts, timeout policies, memory truncation effects) and not benchmarked.
- Rewarding and verifiability
- GUI-Browsing uses LLM-as-Judge even when ground-truth matching is possible; rationale, calibration, and bias analyses are missing (false positives/negatives, agreement with exact-match).
- Outcome Reward Model (ORM) is trained from/with the same model family, raising reward hacking and evaluator–policy coupling risks; no assessor–policy decoupling or cross-model validation reported.
- ORM only conditions on the last five screenshots due to context limits; no study of reward misestimation on long tasks or memory-based reward summarization.
- For non-verifiable GUI-General tasks, no external or human audit of reward correctness; robustness to spurious trajectories remains untested.
- Environment coverage and robustness
- Generalization to non-mainstream apps, enterprise software, rapidly changing UIs (A/B tests, layout shifts), different screen DPIs/resolutions, and accessibility/UIs at various locales (beyond English/Chinese) is unreported.
- No stress tests for real-world instability (network latency, pop-ups, modal dialogs, rate limits, permission prompts) and recovery strategies.
- For games, reliance on HTML5/WebGL mini-games and time-acceleration raises questions about transfer to richer 3D/physics-heavy or console-like environments; fidelity impact of timing API modifications is not evaluated.
- Hybrid GUI-SDK and safety
- Terminal/file-system/tool access introduces safety risks (destructive commands, data exfiltration); no permissioning model, sandboxing policies, or incident containment strategy described.
- No formal evaluation of safe-guard effectiveness (e.g., red-teaming terminals/tools, adversarial prompts, constrained execution).
- Memory and policy architecture
- The hierarchical memory (working vs. episodic) is conceptually described but lacks implementation details (representation, retrieval, compression) and ablations showing when/how it helps or fails.
- No diagnostics on memory interference/forgetting over long episodes, or principled strategies for memory scaling and eviction.
- Parameter interpolation (merging vertical agents)
- Choice of interpolation weights αk, selection procedure, and stability across seeds/tasks are not specified; no comparison with alternatives (Fisher-weighted merging, task arithmetic, adapters).
- Assumption of linear mode connectivity post-RL is untested; potential for negative transfer or brittle performance on edge cases is not analyzed.
- Evaluation methodology and fairness
- Tool-access parity is unclear in baseline comparisons (e.g., GUI-SDK vs. GUI-only for competitors); no standardized “capabilities allowed” matrix to ensure fairness.
- Missing statistical rigor: number of runs, variance/error bars, significance tests, and seed sensitivity across benchmarks are not reported.
- Limited failure-mode taxonomy (why tasks fail, error decomposition across perception, reasoning, action, memory) and no qualitative diagnosis at scale.
- Scalability, cost, and environmental impact
- Compute budget, cluster specs, throughput numbers per stage, and cost/carbon footprint of thousands of VMs and large-scale rollouts are not provided.
- Fault-tolerance and reproducibility claims (checkpointing, determinism) are descriptive; reproducibility metrics (e.g., re-run variance across environments) are missing.
- Security and legal compliance
- No discussion of licensing/TOS compliance for recorded interactions with third-party apps/websites or for synthesized games.
- Attack surface of the unified sandbox and browser/VM infrastructure is not analyzed (supply-chain integrity, escape risks, dependency pinning).
- Benchmarks and external validity
- Several benchmarks are dynamic (web/mobile); procedures to freeze versions, avoid leakage, and ensure longitudinal comparability are not specified.
- Performance on extremely long-horizon, multi-application workflows (e.g., hours-long tasks, cross-app dependencies) is not evaluated; scalability beyond current horizons remains unknown.
- Transparency and release
- It is unclear which assets are released (full datasets vs. subsets, reward code/verifiers, sandbox orchestration scripts, trained checkpoints); without this, external replication and community benchmarking are limited.
Practical Applications
Immediate Applications
Below are applications that can be prototyped or deployed today using the paper’s released codebases, training recipe, and reported performance characteristics.
- Enterprise RPA with GUI-native agents (software, enterprise IT)
- Use UI-TARS-2 to automate multi-step workflows across desktop, web, and Android apps: onboarding/offboarding, invoice processing, report generation, CRM/ERP updates, and cross-app data transfers using GUI actions plus terminal/file-system via GUI-SDK.
- Tools/workflows: cloud VM pool + VM Manager; unified SDK for Windows/Ubuntu/Android; session IDs for reproducibility; MCP tool calls for external services; audit logs via VNC/RTC.
- Assumptions/dependencies: UI stability per app; credentials management; data privacy policies; guardrails to prevent destructive actions; task-specific verification criteria.
- GUI test automation and continuous QA (software, QA/DevOps)
- Replace or augment scripted UI tests with an agent that executes end-to-end user flows, validates outcomes (element states, screenshots, logs), and files bug reports with reproductions.
- Tools/workflows: deterministic VM/browser sandboxes; LLM-as-Judge or scripted verifiers; asynchronous rollout + streaming updates for high-throughput test sweeps; parameter interpolation to retain skills across app suites.
- Assumptions/dependencies: robust test oracles; stable staging environments; change detection for UI drift; cost control for high-concurrency runs.
- Information-seeking and web research agents (education, consulting, media)
- Deploy screenshot-only browsing agents for multi-hop questions (e.g., BrowseComp-style queries) and evidence gathering, with improved accuracy via hybrid GUI actions + SDK (downloading, file parsing, terminal grep).
- Tools/workflows: GUI-Browsing RL tasks; ORM (outcome reward model) scoring; verifiable question pipelines; on-policy SFT collection to target current failure modes.
- Assumptions/dependencies: lawful crawling and ToS compliance; verifiers for task success; model-context limits on long sessions.
- IT runbook and DevOps task automation (IT operations, SRE)
- Automate recurring terminal + GUI tasks: log inspection, service restarts, config edits, patch rollouts, and dashboard checks, combining terminal commands with UI clicks in the same container.
- Tools/workflows: shared file system bridging GUI and shell; terminal exposure via proxy URLs; stateful environments for long-lived sessions; reward shaping for safe termination.
- Assumptions/dependencies: fine-grained RBAC; blast-radius controls (dry-run, canarying); explicit rollback plans and verifiers.
- Assisted software maintenance on monorepos (software engineering)
- Use agents to reproduce issues, run tests, edit code, and validate fixes (SWE-Bench/TerminalBench–style tasks) within a sandbox; hand off diffs to developers with logs and reasoning traces.
- Tools/workflows: remote VS Code/Jupyter integration for human-in-the-loop; GUI-SDK for git/test runners; rejection sampling to collect high-quality exemplars; value-pretrained critics for stable RL finetuning.
- Assumptions/dependencies: repo size vs context limits; test determinism; IP/security policies for code access.
- Game QA and gameplay policy benchmarking (gaming, QA, research)
- Use the hardware-accelerated browser sandbox to validate game mechanics, check difficulty balance, and reproduce gameplay bugs with explicit state verifiers (score/level/lives).
- Tools/workflows: Chrome DevTools Protocol/Playwright compatibility; GPU screenshot acceleration; time control (pause/acceleration) for reproducibility; JSON logs with rewards/flags.
- Assumptions/dependencies: coverage of target game genres; maintenance of verification scripts; performance ≈60% of human may require human fallback in critical tests.
- Accessibility and assistive computer agents (healthcare, public sector)
- Provide voice-driven or instruction-driven agents to execute desktop/mobile tasks for users with motor/vision impairments; combine think-aloud style reasoning traces for transparency.
- Tools/workflows: VNC previews, step-by-step rationales (ReAct); guardrails for sensitive actions (payments/data).
- Assumptions/dependencies: strict consent and safety constraints; latency acceptable for real-time assistance; robust undo/confirmation flows.
- AgentOps sandbox for safe prototyping and evaluation (academia, enterprise platforms)
- Adopt the unified sandbox to run large numbers of monitored, reproducible rollouts across OSes and browsers for internal evaluations, benchmarks, and A/B tests of agent variants.
- Tools/workflows: lease-based lifecycle management; session mapping; garbage collection; crash recovery; parameter interpolation to merge domain specialists into a single deployable checkpoint.
- Assumptions/dependencies: GPU/VM capacity; cost observability; clear success metrics and verifiers.
- On-policy interactive annotation to build internal datasets (academia, ML platforms)
- Stand up the four-layer annotation platform to collect corrective, on-policy SFT for organization-specific apps and flows, improving agent robustness in proprietary environments.
- Tools/workflows: live VM streaming; model suggestions + human overrides; periodic task/model refresh; ASR-transcribed think-aloud for reasoning alignment.
- Assumptions/dependencies: annotator training; privacy-by-design; secure data storage; data governance for mixed human/LLM content.
- Contact center “after-call” automation (finance, healthcare, telecom)
- Automate post-call wrap-up: updating tickets, filling EMR/CRM forms, attaching call notes, and scheduling follow-ups across multiple systems by acting in their UIs.
- Tools/workflows: deterministic task graphs; ORM for completion scoring; SDK functions for text/file transformations; audit trails of actions and screenshots.
- Assumptions/dependencies: PHI/PII handling; SLA-aligned accuracy; UI variability across tenants/versions.
- Education and digital literacy tutors (education)
- Agents that teach and assess computer skills by demonstrating tasks, prompting learners, and evaluating completion within a controlled sandbox (e.g., spreadsheets, presentations, email).
- Tools/workflows: scripted tasks with verifiable outcomes; replayable sessions; scaffolded hints (ReAct thoughts).
- Assumptions/dependencies: curriculum-aligned tasks; accessibility compliance; adaptation to diverse OS locales.
- Agent safety and robustness evaluation harness (policy, AI governance)
- Use the verifiable-task frameworks and sandboxes to test for unsafe behaviors (destructive actions, data exfiltration), UI spoofing susceptibility, and recovery from misleading states.
- Tools/workflows: adversarial tasks; outcome verifiers; reward shaping to penalize unsafe terminations; stateful rollouts for long-horizon risk.
- Assumptions/dependencies: red-team content curation; clear incident taxonomies; logging for forensics.
Long-Term Applications
These opportunities are plausible but require additional research, scaling, standardization, or integration beyond current capabilities.
- OS-level “co-pilot” for general computer use (software, consumer)
- Persistent agent that plans and executes long-horizon workflows across any app, with memory, tool use, and safe delegation/approval loops.
- Dependencies: stronger guarantees of accuracy and reversibility; richer verifiers for open-ended tasks; robust UI-change adaptation; privacy-preserving long-term memory.
- Autonomous IT operator and SRE-on-call assistant (IT operations)
- 24/7 agent that triages alerts, diagnoses incidents, executes runbooks, and coordinates rollback/redeploy with minimal human intervention.
- Dependencies: formalized verifiers for service health; reliable safety layers (approval gates, canaries); incident simulations for RL; compliance logging.
- Cross-domain agent merging at scale (multi-vertical enterprise)
- Systematically train vertical specialists (finance ops, HR, legal ops, procurement) and merge them via parameter interpolation into a unified enterprise agent.
- Dependencies: mode connectivity across diverse datasets/tools; conflict resolution strategies post-merge; evaluation suites per vertical.
- Standards for verifiable GUI tasks and reward schemas (policy, industry consortia)
- Sector-wide benchmarks, schemas, and APIs for defining success criteria of UI tasks, enabling comparable evaluations and safer deployments.
- Dependencies: consensus on metrics; open verifiers; sandboxes for regulated data; LLM-as-Judge reliability standards.
- Agentic governance for compliance-heavy domains (finance, healthcare, government)
- Policy frameworks, attestations, and continuous monitoring tailored to GUI agents that act on regulated systems (auditability by design).
- Dependencies: certified sandboxes; differential privacy/segmentation; legal guidance on autonomous UI actions; standardized incident response.
- Adaptive UI engineering for agent compatibility (software, design systems)
- UI patterns and accessibility layers designed to be agent-friendly (stable selectors, ARIA roles, embedded verifiable state endpoints) that reduce brittleness.
- Dependencies: collaboration between design systems and agent teams; developer tooling to surface “agentability” scores; cost–benefit validation.
- Real-world robotics and HRI transfer of multi-turn RL stability methods (robotics)
- Apply Decoupled/Length-Adaptive GAE, value pretraining, and asynchronous streaming rollouts to physical HRI tasks with verifiable subgoals.
- Dependencies: safe sim-to-real bridges; time-aligned verifiers; high-fidelity perception-action loops; fault tolerance for long-tail episodes.
- Autonomous scientific/market research agents (research, finance)
- Agents that iteratively design questions, gather evidence across the web and tools, synthesize reports, and maintain living literature/market maps.
- Dependencies: robust multi-hop reasoning under distribution shift; de-duplication, provenance tracking; licensing for data sources.
- Agent app store and plug-in ecosystems (platforms)
- Curated marketplaces of task packs (verifiers, flows, tools) that can be composed, trained, and merged into custom enterprise/consumer agents.
- Dependencies: capability descriptors and safety tags; sandbox distribution; economic/pricing models; versioning and rollback.
- Human–agent teamwork workflows with learned delegation (future of work)
- Agents that proactively propose plans, request clarifications, and defer to experts for edge cases, learning organizational norms over time.
- Dependencies: long-horizon preference learning; organizational memory; UX for approvals and exceptions; privacy constraints.
- Large-scale, in-situ cognitive data flywheels in the wild (academia, platforms)
- Continuous, think-aloud-style data collection across many tasks/devices to fuel long-horizon agent learning with real-world diversity.
- Dependencies: opt-in frameworks; anonymization; edge processing; incentives and governance to mitigate bias and leakage.
- Safety-first autonomous transaction agents (e-commerce, travel, logistics)
- Agents that plan, compare options, and execute purchases/bookings/returns with budget/constraint verifiers, operating across multiple services.
- Dependencies: reliable tool calling across vendors (MCP-like standards); strong anti-phishing defenses; chargeback/recourse protocols; explainability of decisions.
Glossary
- ADB: Android Debug Bridge, a tool for communicating with and controlling Android devices/emulators programmatically. Example: "The platform integrates PyAutoGUI and ADB interfaces, enabling cross-device operations with minimal adaptation overhead."
- ASR (automatic speech recognition): Technology that transcribes spoken language into text. Example: "The audio-recorded thoughts are first transcribed using automatic speech recognition (ASR) and then refined by LLMs to produce coherent, high-quality reasoning text."
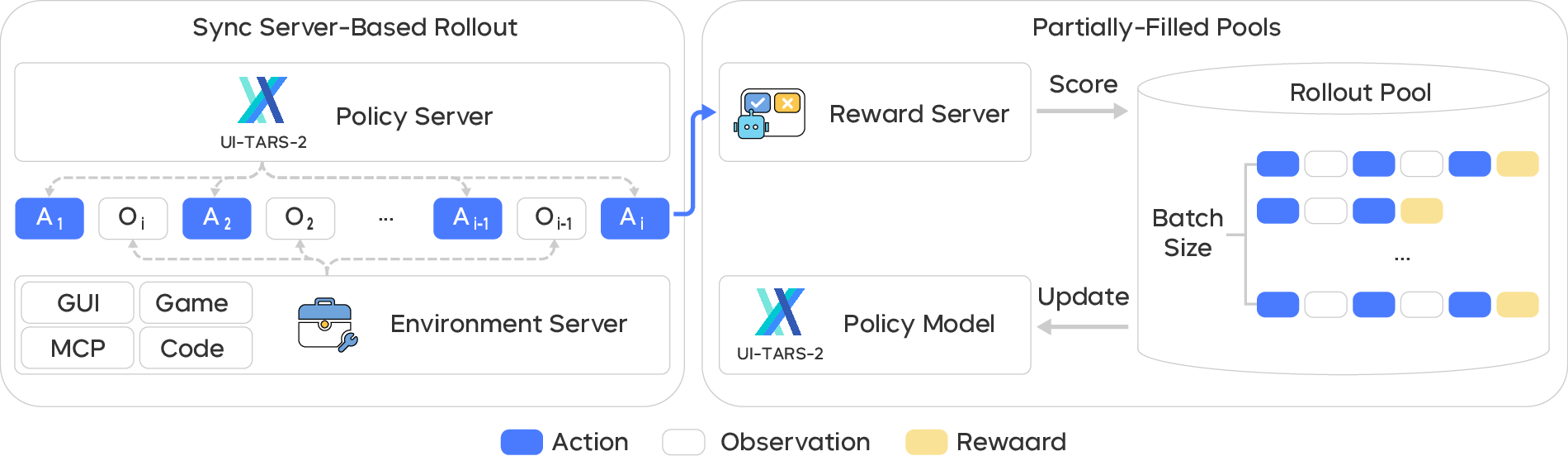
- asynchronous inference: An inference setup where model predictions are served without blocking, allowing concurrent processing and decoupling from the interaction framework. Example: "We adopt a fully asynchronous inference system utilizing online server-mode processing."
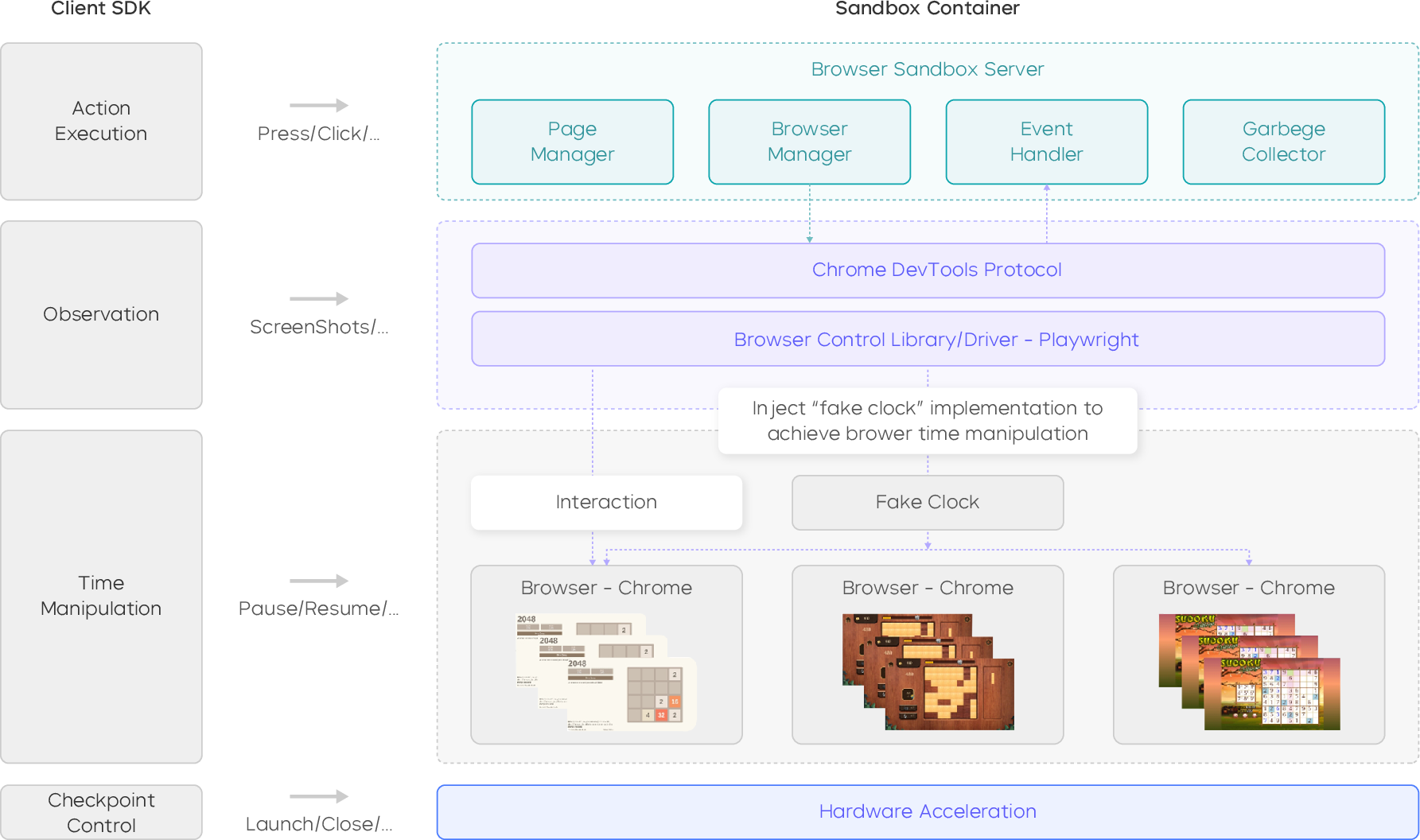
- browser sandbox: A controlled, reproducible browser-based execution environment for interactive tasks and games. Example: "we built a browser sandbox that serves as the execution and observation backbone."
- Chrome DevTools Protocol: A low-level protocol for instrumenting, inspecting, debugging, and profiling Chromium-based browsers. Example: "the sandbox is compatible with the Chrome DevTools Protocol and popular drivers such as Playwright"
- Clip Higher: A PPO variant that decouples clipping thresholds to encourage exploration by allowing larger increases in action probabilities. Example: "#1.{Clip Higher}"
- credit assignment: The challenge of attributing outcomes to specific actions in long sequences within reinforcement learning. Example: "credit assignment across long sequences of actions remains challenging."
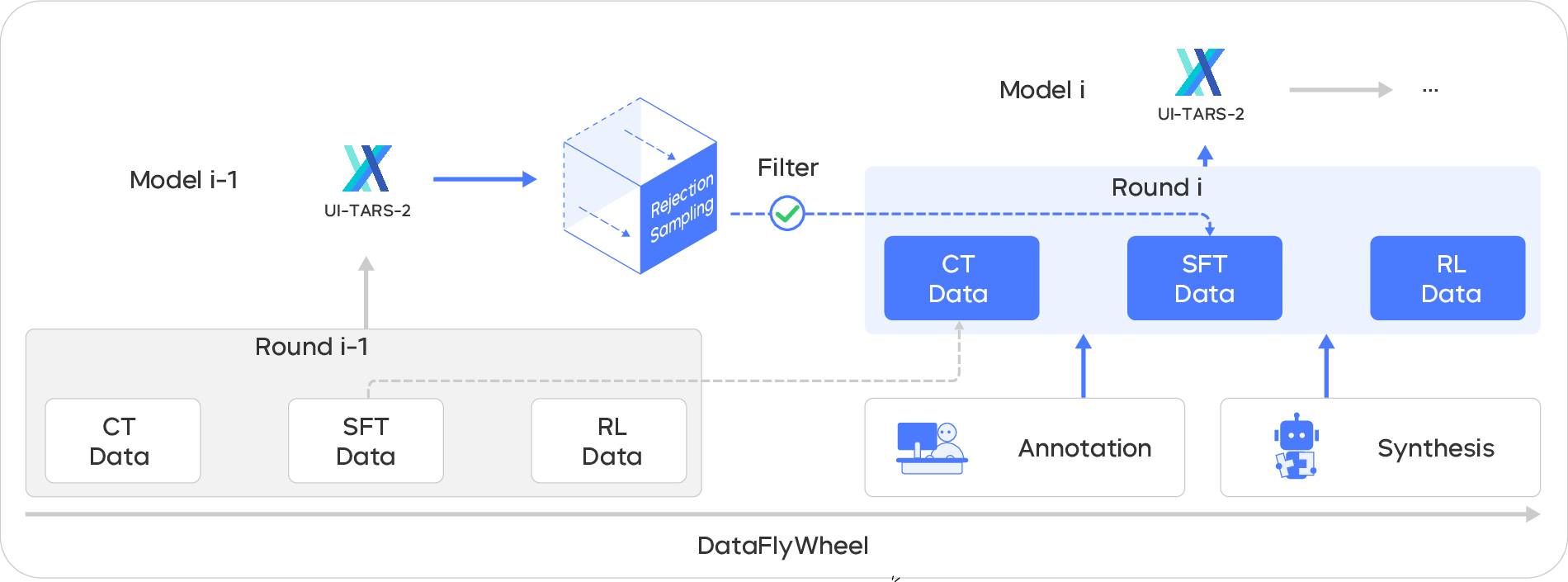
- Data Flywheel: A cyclical data-generation and training process where model improvements and data quality reinforce each other over iterations. Example: "we design a scalable Data Flywheel that co-evolves the model and its training corpus through continual pre-training, supervised fine-tuning, rejection sampling, and multi-turn RL."
- Decoupled Generalized Advantage Estimation (Decoupled-GAE): A technique that computes separate advantage estimations for policy and value to improve long-horizon stability. Example: "we employ the Decoupled Generalized Advantage Estimation (Decoupled-GAE), allowing the computation of advantage for the policy and value function to use different coefficients."
- end-to-end learning: Training that jointly optimizes perception, reasoning, and action within a single model. Example: "by unifying perception, reasoning, action, and memory through end-to-end learning"
- Episodic Memory: A memory module that stores compressed summaries of past episodes for long-term recall in agents. Example: "Episodic Memory maintains semantically compressed summaries of past episodes, preserving key intentions, and outcomes."
- explained variance: A metric indicating how well a value model accounts for variance in returns, used to assess convergence. Example: "Training continues until crucial metrics such as value loss and explained variance reach sufficiently low levels"
- GAE (Generalized Advantage Estimation): A method for estimating advantages that balances bias and variance via a decay parameter. Example: "the value model is updated using GAE with (equivalent to Monte Carlo return)"
- Gym-style interface: An API convention modeled after OpenAI Gym that standardizes environments via step/reset semantics. Example: "which evaluates LLM agents' game-playing abilities across six classic titles through a unified Gym-style interface"
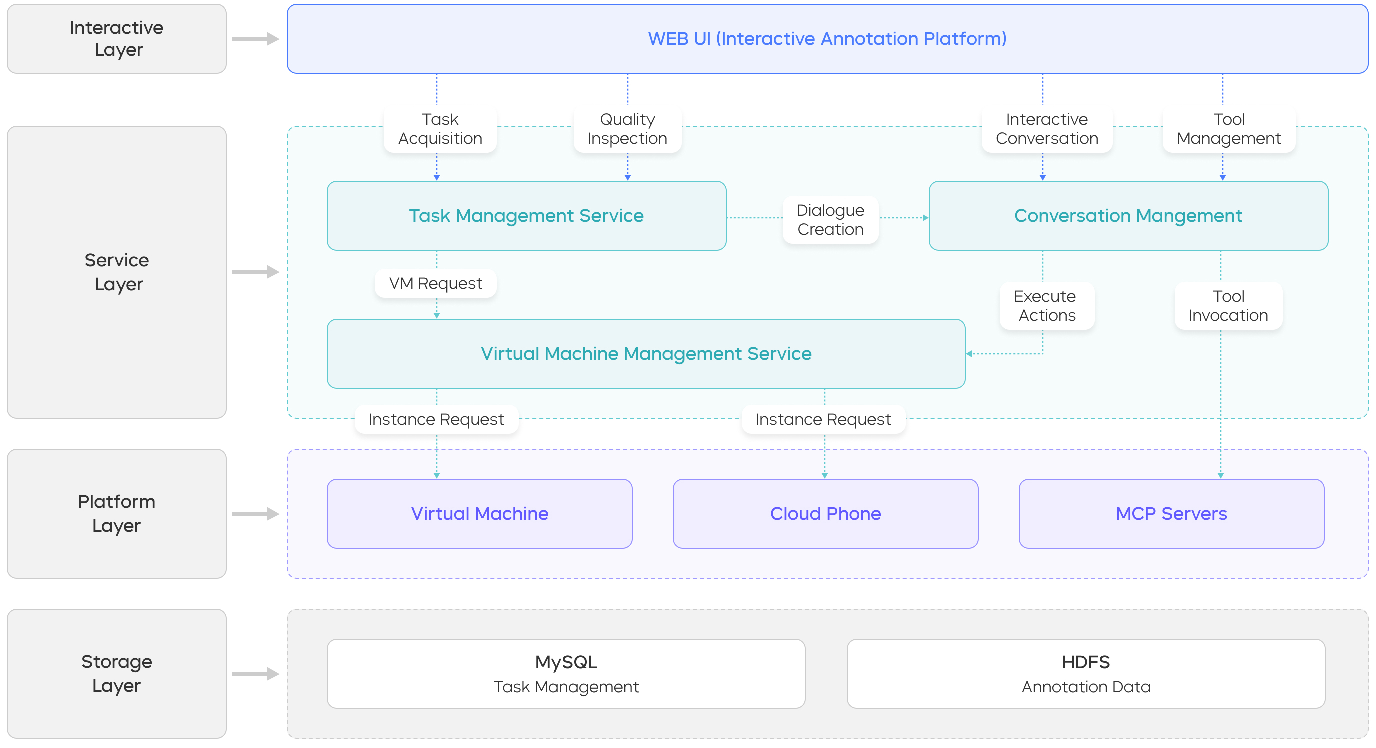
- human-in-the-loop: A training or annotation approach where humans interact during model rollouts to guide and correct behavior in real time. Example: "we propose a novel human-in-the-loop framework for online, interactive data annotation."
- In-Situ Annotation: Data collection conducted directly within users’ natural environments or workflows to capture authentic behavior and reasoning. Example: "In-Situ Annotation for Continual Pre-training"
- lease-based lifecycle mechanism: A resource management approach that allocates resources for limited “lease” periods and automatically reclaims them. Example: "A lease-based lifecycle mechanism automatically releases resources after task completion or failure, while overdue sessions are reclaimed to prevent waste."
- Length-Adaptive Generalized Advantage Estimation (Length-Adaptive GAE): A variant of GAE that adjusts the decay parameter based on sequence length to stabilize training. Example: "we employ Length-Adaptive Generalized Advantage Estimation (Length-Adaptive GAE) technique, adjusting the GAE parameter based on the sequence length."
- LLM-as-Judge: Using a LLM to evaluate predicted outputs and determine correctness when deterministic verifiers are not available. Example: "we instead employ LLM-as-Judge to evaluate the agent’s prediction against the target answer."
- MCP: A tool invocation protocol (e.g., Model Context Protocol) for orchestrating external services and multi-tool reasoning. Example: "as well as MCP tool invocations for orchestrating external services and multi-tool reasoning."
- Mixture-of-Experts (MoE): A neural architecture where multiple expert submodels are selectively activated to improve capacity and efficiency. Example: "Mixture-of-Experts (MoE) LLM with 23B active parameters (230B total)."
- mode-connected: The property that different fine-tuned models from the same initialization can be connected via low-loss paths or linear interpolation in parameter space. Example: "remain approximately linearly mode-connected in parameter space"
- Monte Carlo return: The total accumulated reward computed from full trajectory rollouts without bootstrapping. Example: "with (equivalent to Monte Carlo return)"
- Multi-Condition Obfuscation: A data synthesis method that rewrites and removes distinctive features to create multi-constraint, obfuscated queries requiring deeper reasoning. Example: "#1.{GUI-Browsing} ... (1) Multi-Condition Obfuscation:"
- Multi-Hop Chain-Like Conditions: A task synthesis approach that links entities across web pages to create multi-step questions requiring sequential reasoning. Example: "(2) Multi-Hop Chain-Like Conditions:"
- multi-turn reinforcement learning (RL): Reinforcement learning in settings where agents interact over multiple steps or turns within an environment. Example: "a stabilized multi-turn RL framework"
- native agent models: Agents trained in a data-driven, end-to-end manner that unify perception, reasoning, and control within a single policy. Example: "Recent work on native agent models shifts toward data-driven, end-to-end learning"
- off-policy: Data or learning that uses trajectories not generated by the current policy the agent would follow. Example: "such data is typically off-policy: it does not reflect the actual distribution of actions that the model would take"
- on-policy: Data or learning that uses trajectories generated by the current policy being optimized. Example: "This design ensures that all supervision remains strictly on-policy"
- Outcome Reward Model (ORM): A learned model that scores task success from trajectories, producing scalar rewards when formal verifiers are unavailable. Example: "we employ UI-TARS-2 as a generative outcome reward model (ORM) that produces scalar rewards conditioned on the agent’s trajectory."
- out-of-distribution (OOD): Data or tasks differing from the training distribution, used to test generalization. Example: "We also leverage an OOD benchmark: LMGame-Bench"
- parameter interpolation: Combining parameters from multiple specialized models (e.g., via weighted sums) to merge capabilities without joint training. Example: "then merge them through parameter interpolation"
- Playwright: A browser automation framework for scripted interaction and testing. Example: "the sandbox is compatible with the Chrome DevTools Protocol and popular drivers such as Playwright"
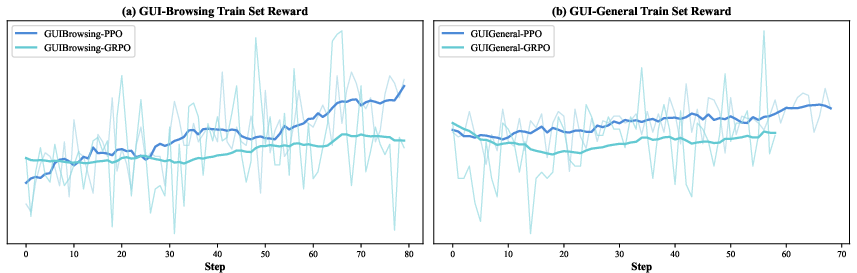
- Proximal Policy Optimization (PPO): A policy-gradient RL algorithm that constrains updates via clipped objectives for stability. Example: "UI-TARS-2 is trained using Proximal Policy Optimization (PPO)"
- PyAutoGUI: A cross-platform automation library for simulating GUI actions such as mouse and keyboard input. Example: "The platform integrates PyAutoGUI and ADB interfaces"
- QPS (Queries Per Second): A throughput metric measuring how many requests a system can process each second. Example: "capable of sustaining throughput at several thousand QPS (Queries Per Second) and handling high-concurrency execution."
- ReAct paradigm: An agent pattern that interleaves reasoning, actions, and observations in a loop. Example: "the agent follows the ReAct paradigm, which interleaves reasoning, action, and observation in a structured loop"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL framework emphasizing tasks with verifiable correctness signals for reliable optimization. Example: "we adopt a multi-turn RL framework built on RLVR (Reinforcement Learning with Verifiable Rewards)"
- rejection sampling (RFT): A data selection process where generated samples are filtered by a validator, with accepted ones used for training; here labeled RFT. Example: "it produces new trajectories via rejection sampling (RFT) or interactive annotation"
- reward shaping: Modifying reward signals (e.g., adding format rewards or penalties) to guide learning and discourage undesirable behaviors. Example: "#1.{Reward Shaping}"
- RTC (Real-Time Communication): Communication protocols enabling live streaming and interaction with remote sessions. Example: "all sessions are visualizable in real time via VNC (Virtual Network Computing) / RTC (Real-Time Communication)."
- stateful agent environments: Environments that preserve and carry forward execution state across multiple tool calls and steps. Example: "We implement stateful agent environments that preserve execution states across multiple tool invocations"
- streaming training: Starting training as soon as partial batches of completed trajectories are available, avoiding blocking on long-tail rollouts. Example: "#1.{Streaming Training with Partially-Filled Rollout Pools}"
- supervised fine-tuning (SFT): Post-training that adapts a model to specific tasks using labeled examples. Example: "supervised fine-tuning (SFT) — high-quality, task-specific instruction tuning"
- think-aloud protocol: An annotation method where participants verbalize thoughts during task execution to capture reasoning. Example: "we instead adopted a think-aloud protocol, where annotators verbalize their thoughts via audio while completing tasks."
- Value-Pretraining: Pretraining the value function offline under a fixed policy to reduce initialization bias and stabilize RL. Example: "we adopt the Value-Pretraining, which involves offline training of the value model to convergence under a fixed policy."
- VAPO: A referenced method providing enhancements for efficient and reliable RL; used as prior work for stability techniques. Example: "Following VAPO and VC-PPO, UI-TARS-2 integrates several critical enhancements"
- VC-PPO: A referenced PPO variant focusing on stability in long chains-of-thought; adopted as prior work. Example: "Following VAPO and VC-PPO, UI-TARS-2 integrates several critical enhancements"
- VLMs (Vision-LLMs): Models that jointly process visual and textual inputs to understand and act on visual interfaces. Example: "VLMs are employed to identify and extract its core functionalities."
- VNC (Virtual Network Computing): A remote desktop protocol for real-time visualization and control of computing sessions. Example: "all sessions are visualizable in real time via VNC (Virtual Network Computing) / RTC (Real-Time Communication)."
- VM (Virtual Machine): A virtualized computing environment running an operating system for isolated, reproducible execution. Example: "we developed a distributed virtual machine (VM) platform that runs mainstream desktop operating systems"
- Window timing APIs: Browser APIs controlling window timing behavior; here re-implemented to speed up or pause games without changing logic. Example: "re-implemented Window timing APIs allow time acceleration and pause at startup"
Collections
Sign up for free to add this paper to one or more collections.