- The paper introduces OmegaUse—a general-purpose GUI agent that uses a MoE-based architecture to achieve autonomous task execution with high spatial grounding accuracy.
- It employs a decoupled training paradigm, combining supervised fine-tuning and reinforcement learning via GRPO to ensure robust navigation and precision.
- The framework demonstrates cross-platform generalization, setting new benchmarks with OS-Nav and providing scalable methods for high-fidelity GUI data synthesis.
OmegaUse: A General-Purpose GUI Agent for Autonomous Task Execution
Introduction and Motivation
OmegaUse introduces a high-performance, general-purpose agent for autonomous task execution across both desktop and mobile graphical user interface (GUI) environments. Unlike system-specific or narrow-domain agents, OmegaUse targets unified generalization, supporting both "computer-use" and "phone-use" scenarios with a shared architecture and action space. The methodology is driven by two observations: model effectiveness is fundamentally gated by data quality and training paradigm, and current benchmarks lack comprehensive cross-platform coverage for realistic user workflows.
To address these, OmegaUse integrates an advanced data pipeline and a decoupled training paradigm, aiming for reliability, coverage, and efficiency in both grounding (UI element localization) and navigation (multi-step action planning). The core contributions include an MoE-based multimodal agent, hybrid data synthesis mechanisms, specialized reward shaping for RL-based refinement, and the OS-Nav benchmark suite for rigorous empirical assessment.
System Architecture
OmegaUse is structured via a decoupled design: one model dedicated to high-precision visual grounding (OmegaUse-G), and another for advanced planning and navigation. Both leverage an MoE backbone that activates a subset of the full parameter set to enable large-scale reasoning under computational constraints. The end-to-end pipeline incorporates hybrid data curation, supervised fine-tuning (SFT) to instill foundational syntax, followed by reinforcement learning via Group Relative Policy Optimization (GRPO) for precision and decision robustness.
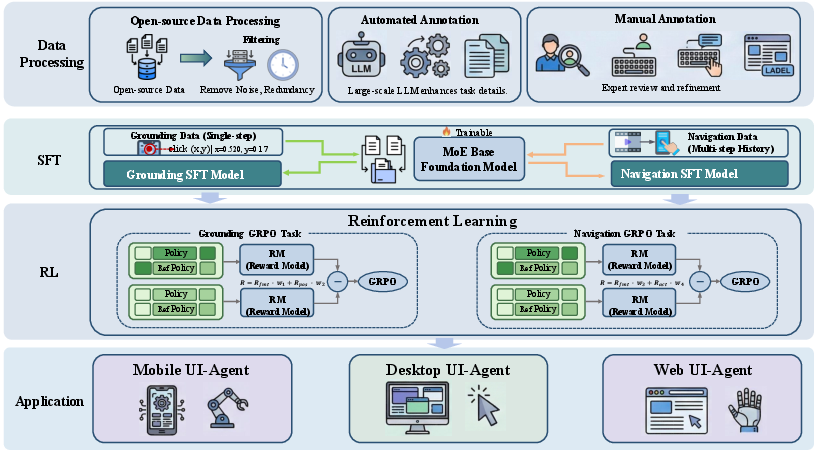
Figure 1: The overall architecture of the OmegaUse framework, illustrating distinct stages of data processing, model pretraining, RL specialization, and deployment across platforms.
Data Construction and Curation
Grounding Data Pipeline
Recognizing label noise and semantic ambiguity in current GUI grounding datasets, OmegaUse applies a rigorous three-stage curation procedure. Initially, large-scale datasets are merged, and noisy, misaligned, or ambiguous instances are heavily filtered, involving both automated screening and expert manual correction. This results in a precision-focused, high-fidelity training corpus of 111,000 instances (from an initial pool of 1.66 million). Emphasis is placed on strict correspondence between screenshots, UI coordinates, and textual descriptions to support accurate one-to-one grounding.
Navigation Data Pipeline
A hierarchical, multi-pronged approach combines:
- Curated open-source datasets: Noise is removed using rule-based and MLLM-augmented auditing.
- Automated bottom-up trajectory synthesis: Autonomous exploration collects execution triples, which are organized into state transition graphs, deduplicated using MLLM-guided semantic clustering.
- Top-down taxonomy-guided task generation: High-level application-specific task taxonomies drive diverse trajectory construction, augmented with expert task execution and human-in-the-loop validation.
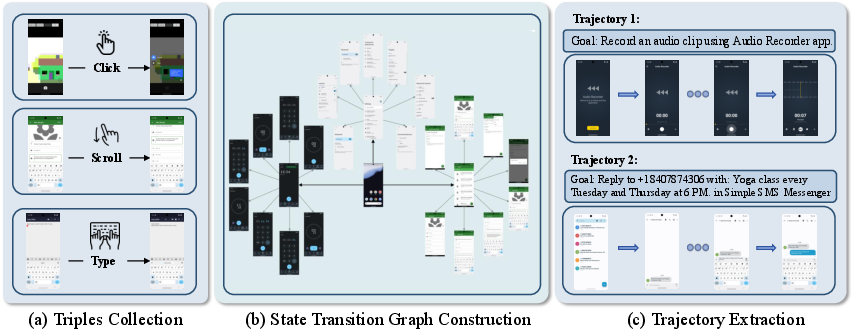
Figure 2: The bottom-up data construction pipeline, with autonomous exploration, semantic graph structuring, and trajectory extraction enriched by MLLMs.
Training Paradigm
Supervised Fine-Tuning (SFT)
For both grounding and navigation, initial supervised pretraining instills foundational instruction-following abilities and output formatting compliance. The grounding model learns to predict bounding boxes in standardized coordinate formats, while the navigation model masters structured action sequences within a unified action schema.
Reinforcement Learning: Group Relative Policy Optimization (GRPO)
Advanced RL via GRPO fine-tunes each model for its domain:
- Grounding: Specialized dual rewards objectively enforce both output syntax and localization accuracy. The "Inside-of-Bounding-Box" reward targets the spatial correctness of predicted clicks or regions.
- Navigation: Action-level, type-level, and coordinate-level rewards, including stepwise F1 and strict action-type matching, are calibrated for precise task decomposition and robust execution under distributional shifts.
Separation between grounding and navigation RL avoids interference and enables targeted specialization.
Unified Action Space and Generalization
OmegaUse defines a unified, hierarchical action space encompassing cross-platform primitives (e.g., click, type, drag) and platform-specific extensions (e.g., hotkeys, mobile gestures), harmonizing disparate workflows and enabling robust generalization. This abstraction, combined with high-coverage hierarchical task taxonomies, positions OmegaUse to transfer across diverse desktop and mobile operating systems without extensive retraining or hand-designed modules.
Offline Benchmarking: OS-Nav
Current benchmarks fail to comprehensively evaluate cross-terminal or real-world autonomy. OS-Nav, introduced with OmegaUse, addresses this gap by covering:
- ChiM-Nav: Chinese mobile apps, focusing on long-horizon, multi-step interactions
- Ubu-Nav: Ubuntu desktop workflows with authentic system-level sequences
All trajectories are annotated, verified, and refined using a human-AI collaborative pipeline, ensuring gold-standard evaluation data and enabling assessment of consistency, generalization, and reasoning under realistic conditions.
Experimental Results
GUI Grounding
On ScreenSpot-V2, OmegaUse achieves a state-of-the-art 96.3% average success rate, outperforming all dense and MoE-based competitors, notably surpassing UI-Venus-Ground-72B and Seed1.5-VL. Performance is near-perfect for text-based elements across both mobile and desktop categories. On the harder ScreenSpot-Pro, OmegaUse (55.47% average) matches or outperforms comparably sized open-source models on OS-level icons and text, although it is outscored by much larger models (e.g., UI-Venus-Ground-72B) on aggregate.
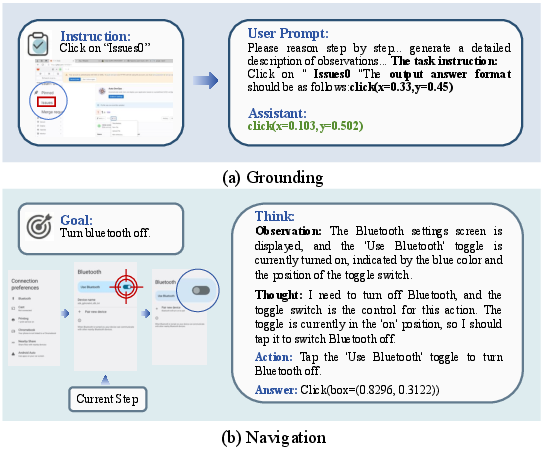
Figure 3: An overview of OmegaUse's core capabilities in realistic GUI scenarios.
GUI Navigation
On AndroidControl, OmegaUse achieves the highest recorded results—Type Accuracy of 87.6% and Step Success Rate of 79.1%, outperforming both open-sourced and closed models, including the larger UI-Venus-Navi-72B. On AndroidWorld, it reaches a 55.7% end-to-end success rate, functioning as a pure vision-language agent (without A11y or extra planners).
On OS-Nav:
- ChiM-Nav: OmegaUse leads all baselines with 87.78% Type Acc. and 74.24% Step SR.
- Ubu-Nav: OmegaUse achieves 55.9% average, significantly outperforming both coordinate and non-coordinate action categories.
These results underscore both the cross-platform generalization and operational robustness under complex, real-world conditions.
Implications and Future Directions
OmegaUse advances GUIs agents in several ways. The decoupled MoE-based system achieves parameter efficiency with competitive, sometimes superior, performance compared to much larger dense models. The hybrid data pipeline—particularly the automated synthesis and human-in-the-loop refinement—offers a blueprint for future dataset construction in multimodal agentic domains. The two-stage decoupled training unlocks new potential for combining modular competence with robust end-to-end autonomy.
The release of OS-Nav establishes a new standard for community-driven, cross-domain benchmarking. Practically, OmegaUse can be directly applied to personal digital assistants, automated testing, cross-application control, or complex accessibility scenarios, reducing the engineering required for transfer learning across ecosystems.
Open research directions include scaling towards yet more complex workflows, integrating dynamic self-correction and robust safety constraints, and pursuing lifelong RL-based adaptation in constantly evolving digital environments.
Conclusion
OmegaUse constitutes a significant step toward reliable, general-purpose, efficient GUI agents. Through Mixture-of-Experts architectures, sophisticated data and training pipelines, and comprehensive evaluation on OS-Nav and standard benchmarks, OmegaUse demonstrates that parameter-efficient, high-capacity agents can excel at spatial grounding and sequential planning simultaneously across diverse digital landscapes. The methodological innovations in data synthesis, modular RL, and unified action abstraction lay groundwork for future advancements in AI-powered interface control and real-world autonomy (2601.20380).