MAI-UI Technical Report: Real-World Centric Foundation GUI Agents
Abstract: The development of GUI agents could revolutionize the next generation of human-computer interaction. Motivated by this vision, we present MAI-UI, a family of foundation GUI agents spanning the full spectrum of sizes, including 2B, 8B, 32B, and 235B-A22B variants. We identify four key challenges to realistic deployment: the lack of native agent-user interaction, the limits of UI-only operation, the absence of a practical deployment architecture, and brittleness in dynamic environments. MAI-UI addresses these issues with a unified methodology: a self-evolving data pipeline that expands the navigation data to include user interaction and MCP tool calls, a native device-cloud collaboration system routes execution by task state, and an online RL framework with advanced optimizations to scale parallel environments and context length. MAI-UI establishes new state-of-the-art across GUI grounding and mobile navigation. On grounding benchmarks, it reaches 73.5% on ScreenSpot-Pro, 91.3% on MMBench GUI L2, 70.9% on OSWorld-G, and 49.2% on UI-Vision, surpassing Gemini-3-Pro and Seed1.8 on ScreenSpot-Pro. On mobile GUI navigation, it sets a new SOTA of 76.7% on AndroidWorld, surpassing UI-Tars-2, Gemini-2.5-Pro and Seed1.8. On MobileWorld, MAI-UI obtains 41.7% success rate, significantly outperforming end-to-end GUI models and competitive with Gemini-3-Pro based agentic frameworks. Our online RL experiments show significant gains from scaling parallel environments from 32 to 512 (+5.2 points) and increasing environment step budget from 15 to 50 (+4.3 points). Finally, the native device-cloud collaboration system improves on-device performance by 33%, reduces cloud model calls by over 40%, and preserves user privacy.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces MAI-UI, a family of smart “screen agents” that can use phones and apps the way a person would. These agents read your natural language instructions, understand what’s on the screen, tap and type for you, ask you questions when your request is unclear, and even use special tools to speed things up. They’re designed to work both on your device and in the cloud, switching between them to balance speed, cost, and privacy.
What questions did the researchers ask?
The team wanted to solve four practical problems that stop today’s GUI agents from working well in the real world:
- How can an agent handle unclear instructions? It should be able to ask users for more details or permission when needed.
- How can we go beyond tapping and swiping only? Long tap/scroll sequences can be fragile, so the agent should also use external tools to do tasks quickly and reliably.
- How can we combine on-device and cloud models? Cloud-only tools can be costly and risky for privacy, and device-only models can be too weak. We need smart teamwork between device and cloud.
- How can we make agents robust to changing apps and screens? Real apps update layouts, show pop-ups, and differ across devices. Agents need training that prepares them for this chaos.
How did they do it?
To build MAI-UI, the researchers used several ideas and systems. Here are the main parts, explained in simple terms:
Building the agent’s “screen sense” and skills
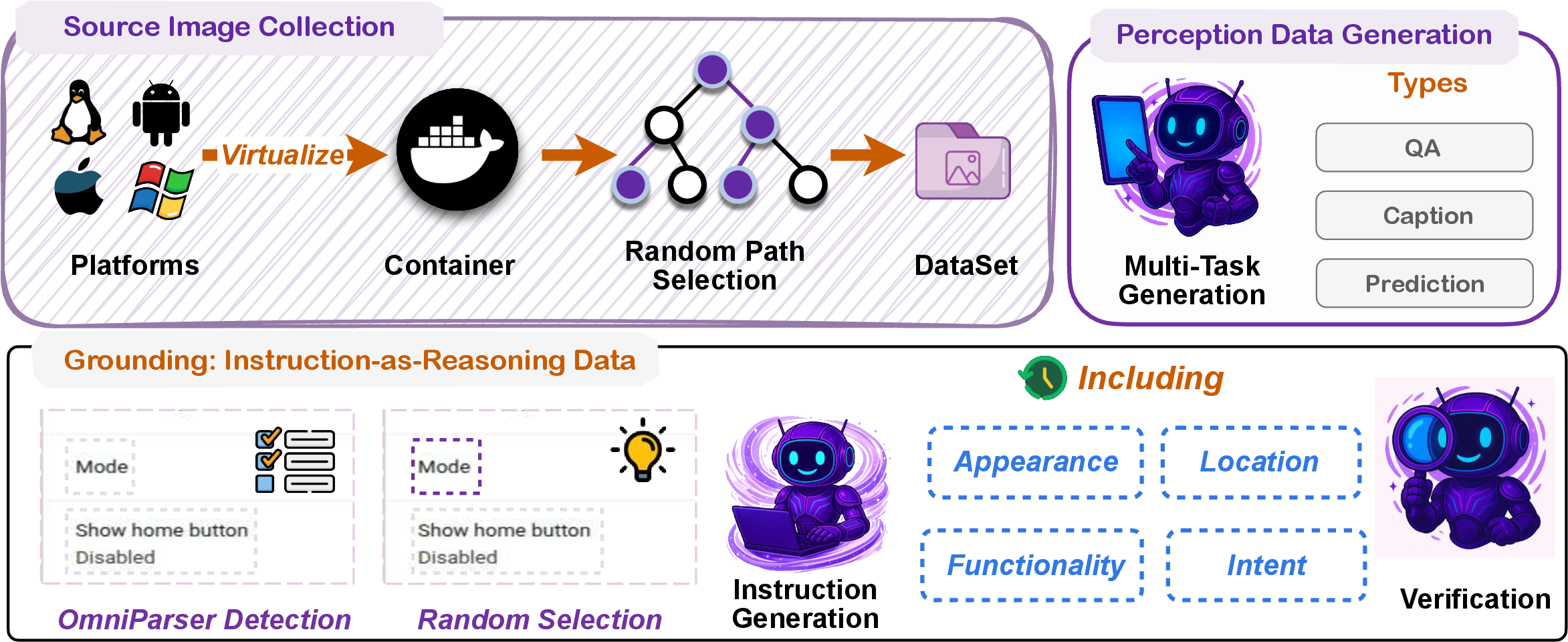
- Screen understanding and “grounding”: The agent learns to find the right buttons or fields based on what you ask. Think of grounding like “spot the button” given a screenshot and an instruction.
- Action toolbox: The agent can
click,swipe,type,wait, andterminatea task. It can alsoask_user(to clarify your request),answer(just respond with text), andmcp_call(use an external tool via the Model Context Protocol, like calling a map or GitHub API). - Diverse training data: They collected many real screenshots and tasks, and generated multiple styles of instructions (by appearance, function, location, and intent). This is like teaching the agent to think in different ways, not just one.
Teaching interaction and tool use
- Agent-user interaction: The training includes tasks that purposely leave out key details (like missing dates or names). When the agent gets stuck, it uses
ask_userto request the missing info and continues afterward. - MCP tools: Instead of doing 20 steps on a screen, the agent can call a tool to do a complex thing in one go. For example, it can interact with GitHub or navigation services through clean, structured APIs.
Training with practice (reinforcement learning)
- Practice in virtual phones: The agent trains in many containerized Android environments (like safe, reusable “virtual phones” in the cloud). This lets it practice thousands of tasks in parallel, quickly.
- Handling long tasks: Real tasks can take many steps. They built an asynchronous system so the agent keeps working while other parts wait, and used clever GPU sharing so even very long screen histories can be trained end-to-end.
- Fair judging: Some tasks are verified with rules (like “did we reach this page?”), and others are judged by another AI that checks the screenshots and actions. This lets them scale evaluation without tons of manual work.
Device-cloud teamwork
- Local agent and monitor: The on-device agent both acts and monitors. It checks whether it’s making progress or going in circles. If it detects a problem and the data isn’t sensitive, it hands off to the stronger cloud agent.
- Cloud helper: The cloud agent receives a short “error summary” and the full history, then takes over to recover and finish the task.
- Unified memory: A shared history ensures both agents see the same context, so switching is smooth and accurate.
What did they find, and why is it important?
Here are the key results from their tests on public benchmarks and real-like scenarios:
- Better “spot the button” accuracy: MAI-UI reached 73.5% on ScreenSpot-Pro (with a zoom-in trick), 91.3% on MMBench GUI L2, 70.9% on OSWorld-G, 49.2% on UI-Vision, and 96.5% on ScreenSpot-V2. These scores beat strong systems like Gemini-3-Pro and Seed1.8 on several tests.
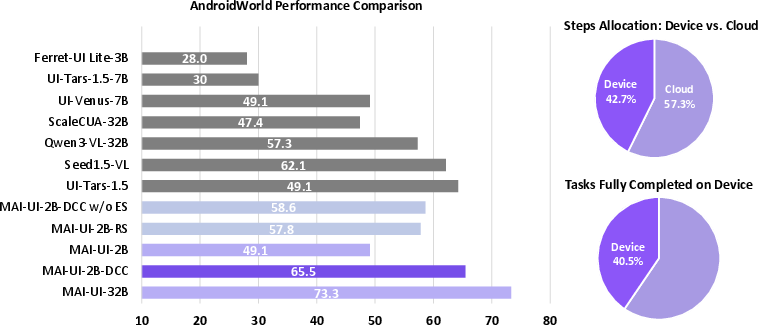
- Strong navigation on phones: On AndroidWorld (a tough, live environment), the largest MAI-UI model achieved 76.7% success, which set a new state of the art. The 32B, 8B, and 2B models also did very well for their sizes.
- Realistic tasks beyond tapping: On MobileWorld (tasks that need asking the user or using tools), MAI-UI reached 41.7% success overall. On tasks that require user interaction it got 37.5%, and on tasks with tool use it got 51.1%, big improvements over end-to-end tap-only agents.
- Reinforcement learning boosts: Scaling practice environments from 32 to 512 increased success by about +5.2 points, and allowing longer task steps (15 to 50) added about +4.3 points. This shows more practice and longer horizons make the agent smarter and steadier.
- Device-cloud collaboration helps: Their system improved on-device performance by 33%, reduced cloud calls by over 40%, and protected privacy by keeping sensitive data local when possible.
These results matter because they show that a practical, helpful screen agent is possible: it can understand varied screens, navigate complex apps, ask when unsure, use powerful tools when needed, and work efficiently with both local and cloud models.
What does this mean for the future?
MAI-UI points toward everyday “phone helpers” that:
- Let you control complex apps with plain language.
- Ask you for missing details and permission, avoiding mistakes.
- Use external tools to finish tasks quickly and reliably.
- Mostly run on your device for speed and privacy, with cloud backup only when necessary.
- Handle real-world messiness like pop-ups, updates, and different layouts.
This could make phones more accessible, save time on repetitive tasks, and enable new mobile workflows (like managing code or business tasks on the go). For researchers and developers, the paper provides a roadmap: build diverse training data, teach interaction and tool use, practice in scalable virtual environments, and design smart device-cloud collaboration.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Real-device evaluation: No systematic assessment on physical smartphones (latency, energy, thermals, memory footprint, on-device throughput), only containerized AVDs; sim-to-real transfer remains unquantified.
- Device–cloud routing policy: Lacks precise criteria and algorithms for when and how to hand off (trigger thresholds, privacy detection logic, confidence calibration), and no precision/recall metrics for the on-device monitor’s deviation detection.
- Privacy detection and enforcement: No concrete method for identifying sensitive content in screenshots/text, nor audits, redaction, encryption, or data-minimization policies for the unified trajectory memory and cloud handoffs.
- User interaction quality: The ask_user mechanism is trained with synthetic users; no user study or metrics on dialogue quality, clarification effectiveness, refusal handling, or impact on task success and safety.
- MCP tool use generalization: No evaluation on generalization to unseen tools, schema evolution, tool selection accuracy, tool failure handling, authentication/authorization, rate limits, or security safeguards against harmful tool invocations.
- Safety and risk controls: No red-teaming or safety benchmarks for preventing unsafe actions (e.g., destructive operations, privacy breaches), nor explicit consent flows or policy enforcement beyond “ask_user.”
- Long-horizon tasks: RL training caps at 50 steps; scalability to 100–200+ step tasks (common in real workflows) and robust credit assignment under sparse rewards are untested.
- Verifier reliability: MLLM-as-a-judge shows 83% agreement with humans; impact of label noise on RL stability and performance, calibration strategies, and cost/latency trade-offs are not analyzed.
- Dataset transparency and contamination: Missing details on dataset composition, deduplication across training and evaluation, leakage prevention for ScreenSpot/OSWorld/UI-Vision/AndroidWorld, and release plans for reproducibility.
- Bias and coverage in MobileWorld: Benchmark is self-hosted with open-source apps; lack of validation on widely used proprietary apps, diverse locales (languages, RTL), OEM skins, accessibility settings, and app version churn.
- Pop-up/permission robustness: While motivated, robustness to dynamic prompts/pop-ups/notifications is not quantitatively evaluated with targeted stress tests or ablations.
- Error recovery efficacy: The monitor’s “error summary” is introduced, but no ablation quantifies its contribution to recovery or overall success versus baselines without summaries.
- Zoom-in strategy trade-offs: Gains reported but no analysis of computational overhead, failure modes (loss of global context), or consistency across model sizes and screen densities.
- RL algorithm details: Missing hyperparameter sensitivities (group size, clip bounds, replay buffer size), ablations for reward design (loop penalties), and comparisons with alternative PPO/DAPO variants or off-policy methods.
- Tool–UI arbitration: No decision policy analysis for when to prefer MCP calls over UI operations (cost, reliability, error propagation), nor ablations quantifying success/latency improvements attributable to MCP.
- Internationalization and accessibility: No evaluation under multilingual UI text, non-Latin scripts, accessibility mode changes, or varying DPI/resolution; reliance on a11y/OmniParser may fail on obfuscated UIs.
- Security model: AVDs are rooted; differences from stock devices (permissions, sandboxing) may overstate capability; no secure execution sandbox or rollback strategy on real devices.
- On-device deployment specifics: Absent details on model quantization, memory/computation budgets, accelerators used, and latency distributions across commodity phones; the “33% improvement” lacks metric definition and methodology.
- Cost accounting: No end-to-end cost/latency analysis for device–cloud collaboration (network variability, inference pricing, MCP call fees), or trade-offs between call reductions and success rates.
- Multi-task and concurrency: No discussion of concurrent tasks, background app interference, notification storms, or memory race conditions in the “unified trajectory memory.”
- Cross-platform scope: Work targets Android; generalization to iOS and desktop OSs (windowed GUIs, different accessibility APIs) is unaddressed.
- Evaluation rigor: Reported SOTA lacks statistical significance (confidence intervals, variance across seeds/devices), and some baselines are “evaluated by us” without standardized protocols.
- Ethical considerations: Synthetic trajectories and judge-driven labels may encode biases; no audit or fairness analysis across app categories and user populations.
Practical Applications
Below is an overview of practical, real-world applications that follow from the paper’s findings, methods, and system innovations. Each item notes sector relevance, actionable use cases, potential tools/products/workflows, and key assumptions/dependencies affecting feasibility.
Immediate Applications
- Hybrid mobile automation assistant (SDK)
- Sector: software, enterprise IT, consumer devices
- Use case: Ship a privacy-aware assistant inside mobile apps or OEM firmware that can perform multi-step UI tasks (e.g., change settings, file expense reports, post to social media) using on-device models, escalating to cloud only when needed.
- Tools/products/workflows: “Hybrid Agent SDK” combining a Local GUI Agent, Cloud GUI Agent, and Local Unified Trajectory Memory; out-of-the-box action space (
click,swipe,type,ask_user,mcp_call). - Assumptions/dependencies: Access to UI capture/execution APIs; MCP tool connectors for target services; device compute to run 2B models; network availability for cloud fallback; consent handling for sensitive ops.
- Mobile RPA for business apps
- Sector: enterprise, e-commerce, logistics, finance
- Use case: Automate repetitive mobile workflows (e.g., order fulfillment, invoice approval, CRM updates) across multiple apps; replace brittle scripts with visual grounding and reinforcement-trained navigation.
- Tools/products/workflows: Policy-driven task routing (device/cloud), MCP tools to compress flows (e.g., GitHub, Amap, “Stockstart”), trajectory monitor for error summaries and recovery.
- Assumptions/dependencies: App terms of service; stable UI rendering and accessibility; audited MCP schemas; enterprise identity/authorization integration.
- Scalable automated UI testing and accessibility auditing
- Sector: software engineering, QA, accessibility
- Use case: CI/CD pipelines that automatically exercise app flows at scale (512+ parallel instances), generate trajectories, detect regressions, and validate accessibility labels via GUI grounding.
- Tools/products/workflows: Containerized Android RL farm (AVD snapshots; REST API), Environment Manager for orchestration, MLLM-as-a-Judge verifiers, rule-based checkers for deterministic tasks.
- Assumptions/dependencies: Emulator parity with real devices; test data seeding via self-hosted backends; reliability of 83% judge-human agreement; accessibility tree availability or robust vision-only grounding.
- Customer support co-pilot for “do-it-for-me” sessions
- Sector: customer support/BPO, telecom, banking, government services
- Use case: Agents can carry out in-app resolutions (e.g., change plan, reset password, submit claims) with
ask_userto clarify intent and explicit consent gates; reduce handoffs and call time. - Tools/products/workflows: In-app embedded agent, “ask_user” dialogue templates, cloud escalation with error summary for tricky flows, audit trails in unified memory.
- Assumptions/dependencies: Strong authentication and authorization; consent logging; guardrails preventing unsafe actions; adherence to jurisdictional privacy laws.
- Accessibility assistant for low-vision/elderly users
- Sector: healthcare, assistive tech, consumer devices
- Use case: Voice-driven control of complex app UIs; clarify vague instructions; automate long sequences (e.g., booking appointments, refilling prescriptions).
- Tools/products/workflows: On-device 2B model for privacy;
ask_userto resolve ambiguity; zoom-in strategy for small UI elements; error recovery via device-cloud handoff. - Assumptions/dependencies: Local speech I/O; low-latency inference; robust grounding (small targets, pop-ups); inclusive design approvals.
- Policy-compliant in-app consent manager
- Sector: finance, healthcare, public sector
- Use case: Enforce explicit consent before sensitive actions (e.g., transfers, health-data access) with
ask_userand trajectory monitoring; block or escalate uncertain contexts. - Tools/products/workflows: Alignment monitor trained to detect deviations; consent templates; rule-based verifiers for success/failure; audit logs.
- Assumptions/dependencies: Accurate detection of sensitive contexts; regulatory compliance (HIPAA, PCI DSS, GDPR); clear consent UX and records.
- App store moderation and compliance checking
- Sector: platforms/app stores
- Use case: Automated review agents navigate app UIs to check policy compliance (e.g., permissions, advertising standards, data-collection disclosures).
- Tools/products/workflows: Containerized app analysis, rule-based verifiers, MLLM-as-a-Judge for non-deterministic checks, trajectory archives.
- Assumptions/dependencies: Sandbox-controlled app execution; reliable screenshots and state verification; model generalization to diverse app genres and versions.
- Cross-app personal productivity flows
- Sector: consumer productivity
- Use case: Multi-app tasks (e.g., collect receipts from messages, file expenses in enterprise app, notify team in Mattermost) with MCP shortcuts where available.
- Tools/products/workflows: Mixed UI+API flows through
mcp_call; unified trajectory memory across apps; long-horizon RL improvements for reliability. - Assumptions/dependencies: MCP tool coverage; multi-app permissions; data sensitivity routing; battery and thermal constraints during extended sessions.
- Academic benchmarking and reproducible agent research
- Sector: academia, research labs
- Use case: Adopt MobileWorld for realistic tasks; use the open containerized environment manager for parallel rollouts; study long-horizon GRPO training and curriculum design.
- Tools/products/workflows: Dockerized AVD images; RL primitives (
reset,step,evaluate); hybrid parallelism (TP+PP+CP) training recipes; MLLM-as-a-Judge baselines. - Assumptions/dependencies: Compute budget to scale parallel environments; reproducibility across hosts; license compatibility for integrated apps.
- Data generation for GUI reasoning datasets
- Sector: data engineering, ML tooling
- Use case: Generate diverse instruction-perception-grounding corpora (appearance, function, location, intent) with rejection sampling and partial trajectory reuse to reduce annotation waste.
- Tools/products/workflows: Self-evolving pipeline; instruction-as-reasoning prompts; fine-grained correctness judgment; trajectory prefix extraction.
- Assumptions/dependencies: Quality of MLLM-based generation; filtering discipline; legal usage of app assets and screenshots.
- Cost-optimized cloud routing in agent platforms
- Sector: cloud platforms, MLOps
- Use case: Reduce cloud calls by >40% via on-device monitoring and selective escalation; improve on-device success by 33% with native collaboration.
- Tools/products/workflows: Local monitor with error summary; routing policies based on sensitivity and task state; metrics dashboards for cost and privacy.
- Assumptions/dependencies: Reliable deviation detection; privacy classification; consistent device-cloud context synchronization.
Long-Term Applications
- OS-native, cross-app goal-driven agents
- Sector: consumer devices, mobile OS vendors
- Use case: System-level assistants that complete complex goals across apps autonomously, maintaining audited histories and robust recovery.
- Tools/products/workflows: Deep OS integration of Local Agent, unified trajectory memory in system services, MCP tool registries.
- Assumptions/dependencies: OEM partnerships; secure sandboxing; comprehensive permission and policy frameworks.
- Regulated-sector automation with formal guardrails
- Sector: healthcare, finance, government
- Use case: End-to-end mobile processes (claims, onboarding, benefits disbursement) with formal consent, verifiable logs, and policy-aware routing and verifiers.
- Tools/products/workflows: Rule-based success criteria; policy engines; compliance dashboards; immutable audit trails.
- Assumptions/dependencies: Standards alignment (HIPAA, SOX, PCI DSS, GDPR); third-party audit certification; robust red-teaming for safety and reliability.
- Self-healing UI automation for QA
- Sector: software engineering
- Use case: RL-trained agents that adapt test flows to app changes (layout shifts, pop-ups), minimizing manual maintenance of brittle scripts.
- Tools/products/workflows: Dynamic curriculum; frontier/exploration/near-mastery task stratification; error-summary-driven recovery.
- Assumptions/dependencies: Persistent RL investment; reliable verifiers; continuous environment snapshots; handling of out-of-domain UI patterns.
- Cross-device “ambient” agent continuum
- Sector: IoT, smart home, automotive
- Use case: Unified agent that operates seamlessly across phone, tablet, desktop, and embedded devices for hands-free, natural language control.
- Tools/products/workflows: Shared trajectory memory across devices; device-cloud mediation; vision-based grounding generalized beyond mobile.
- Assumptions/dependencies: Cross-OS UI control APIs; federated privacy guarantees; consistent MCP connectors.
- Agent marketplace and automation recipes
- Sector: platforms, developer ecosystems
- Use case: Users install vetted “recipes” (task graphs) that combine UI flows and MCP tools to automate common goals (e.g., travel booking, budget setup).
- Tools/products/workflows: Recipe registries; schema validation; safety filters; community-curated tool packs.
- Assumptions/dependencies: Standardized MCP schemas; content moderation; recipe provenance and security.
- Standardization of agent–user interaction and consent
- Sector: policy, standards bodies
- Use case: Guidelines for
ask_userclarifications, consent prompts, sensitive-context detection, and audit logging across industries. - Tools/products/workflows: Reference UX patterns; audit schemas; compliance test suites.
- Assumptions/dependencies: Multi-stakeholder alignment; alignment with accessibility standards; evolving legal frameworks.
- Generalized desktop GUI agents with device-cloud collaboration
- Sector: enterprise IT, productivity software
- Use case: Extend methodology to Windows/macOS enterprise apps, blending UI operations with tool APIs for complex desktop workflows.
- Tools/products/workflows: Desktop containerization; accessibility tree parsers; OS-level automation hooks; hybrid verifiers.
- Assumptions/dependencies: OS automation APIs; security constraints (admin/root); model performance on desktop layouts.
- Privacy-preserving federated training for GUI agents
- Sector: MLOps, privacy tech
- Use case: Train and adapt agents on-device using local trajectories, sharing only model updates to improve robustness without exposing user data.
- Tools/products/workflows: Federated RL/SFT; differential privacy; client-side verifiers; on-device curriculum scheduling.
- Assumptions/dependencies: Efficient on-device training; secure aggregation; verifiable privacy guarantees.
- Financial operations agent with multi-layer safeguards
- Sector: finance, fintech
- Use case: Autonomously manage mobile banking tasks (budgeting, transfers, investment moves) using MCP financial tools and strict
ask_userconsent and trajectory monitoring. - Tools/products/workflows: Multi-layer risk checks; anomaly detection; rule-based final-state verifiers; transparent audit logs.
- Assumptions/dependencies: Bank API/MCP availability; regulatory approvals; robust fraud detection; strong identity assurance.
- Clinical and patient-facing app navigator
- Sector: healthcare
- Use case: Navigate patient portals, schedule appointments, refill prescriptions, collect measurements—proactively clarifying instructions and preserving privacy via device-first routing.
- Tools/products/workflows: Healthcare MCP connectors; sensitive-context classifiers; HIPAA-compliant audit trails; human-in-the-loop override.
- Assumptions/dependencies: EHR integrations; regulatory compliance; secure device policies; resilience to frequent app updates.
Notes on cross-cutting assumptions and dependencies:
- Model capabilities: Success depends on strong GUI grounding (small targets, variable layouts), long-horizon reliability, and robust error recovery; current benchmarks show SOTA, but generalization to diverse, evolving real-world apps is an ongoing challenge.
- Tooling ecosystem: MCP tool availability and high-quality schemas unlock many time-saving shortcuts; coverage gaps will require custom connectors.
- Infrastructure: The containerized environment and RL farm scale well for testing/training; deploying at production scale requires reliable orchestration, failover, and cost controls.
- Safety and compliance: Sensitive operations need explicit consent, audited histories, and policy-aware verifiers; human-in-the-loop designs remain prudent in high-stakes contexts.
- Device constraints: On-device models reduce latency and protect privacy but are limited by compute, battery, and thermal budgets; hybrid routing mitigates this at the cost of network dependence.
Glossary
- A11y tree: The accessibility tree representation of UI elements used for precise element localization. "Finally, we use the a11y tree or OmniParser V2~\citep{omniparser} to localize UI elements precisely."
- Agent–user interaction: An agent capability to ask clarifying questions, collect missing details, and seek consent from users during task execution. "Effective agentâuser interaction is therefore a critical yet often neglected capability."
- AndroidWorld: A challenging dynamic benchmark/environment for online mobile GUI navigation tasks. "In challenging dynamic real-time environments, MAI-UI-235B-A22B achieves a new state of the art success rate of 76.7\% on AndroidWorld, surpassing UI-Tars-2 \citep{uitars2}, Gemini-2.5-Pro \citep{GeminiComputerUse}, and Seed1.8 \citep{seed18}."
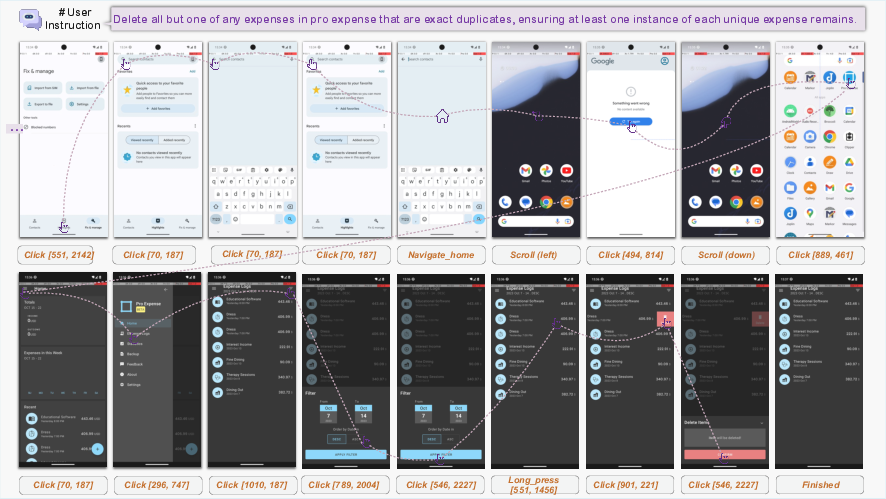
- AVD snapshot mechanism: A technique to capture and restore emulator state snapshots for reproducible task initialization. "We employ an AVD snapshot mechanism for reproducible task initialization and expose standard RL primitives (, , , , and ) through the containerized API server, enabling parallel deployment of emulator instances."
- Clip Higher: An asymmetric clipping strategy in policy optimization with a larger upper bound to encourage exploration. "Following DAPO \citep{yu2025dapo}, we employ the token-level loss with no KL divergence and an asymmetric clipping strategy with a larger upper bound to encourage exploration."
- Containerized solution: Packaging the entire GUI environment into containers to ensure isolation, consistency, and scalability for RL rollouts. "Inspired by an experimental feature in AndroidWorld \citep{android_world}, we built a containerized solution that encapsulates the entire GUI environment within a Docker image, comprising a rooted Android Virtual Device (AVD), self-hosted backend services, and a dedicated REST API server for orchestration."
- Curriculum (automatic curriculum): Adaptive scheduling of task sampling by difficulty to balance exploration and exploitation during training. "Building on this stratification, we implement an automatic curriculum that progressively adjusts task sampling throughout training."
- DAPO: A policy optimization method that uses asymmetric clipping to encourage exploration and stabilize training. "Following DAPO \citep{yu2025dapo}, we employ the token-level loss with no KL divergence and an asymmetric clipping strategy with a larger upper bound to encourage exploration."
- Device–cloud collaboration system: An architecture that adaptively routes computation between on-device and cloud agents based on context and data sensitivity. "In addition, MAI-UI integrates a native deviceâcloud collaboration system that routes computation by task state and data sensitivity."
- Environment Manager: A centralized coordinator that manages distributed container instances for scalable parallel rollouts. "To further scale environments across distributed infrastructure, we introduce a centralized Environment Manager that coordinates container instances across multiple physical machines."
- Experience replay: An RL technique that reuses past successful trajectories to maintain learning signals and stabilize training. "We maintain a replay buffer of successful trajectories collected during training."
- Exploration–exploitation tradeoff: The balance between trying new tasks (exploration) and improving known tasks (exploitation) in RL. "This adaptive strategy prevents training collapse from excessive difficulty while ensuring continuous learning signals, effectively addressing the exploration-exploitation tradeoff."
- Failover protocols: Automatic recovery mechanisms to replace failing environment instances with standby containers. "we introduce automatic detection and recovery mechanisms to handle container failures, with failover protocols that seamlessly replace compromised instances from a standby pool."
- GRPO: Group Relative Policy Optimization, a reinforcement learning algorithm that samples multiple outputs and uses normalized advantages for policy updates. "we then conduct a reinforcement learning (RL) stage using the GRPO algorithm."
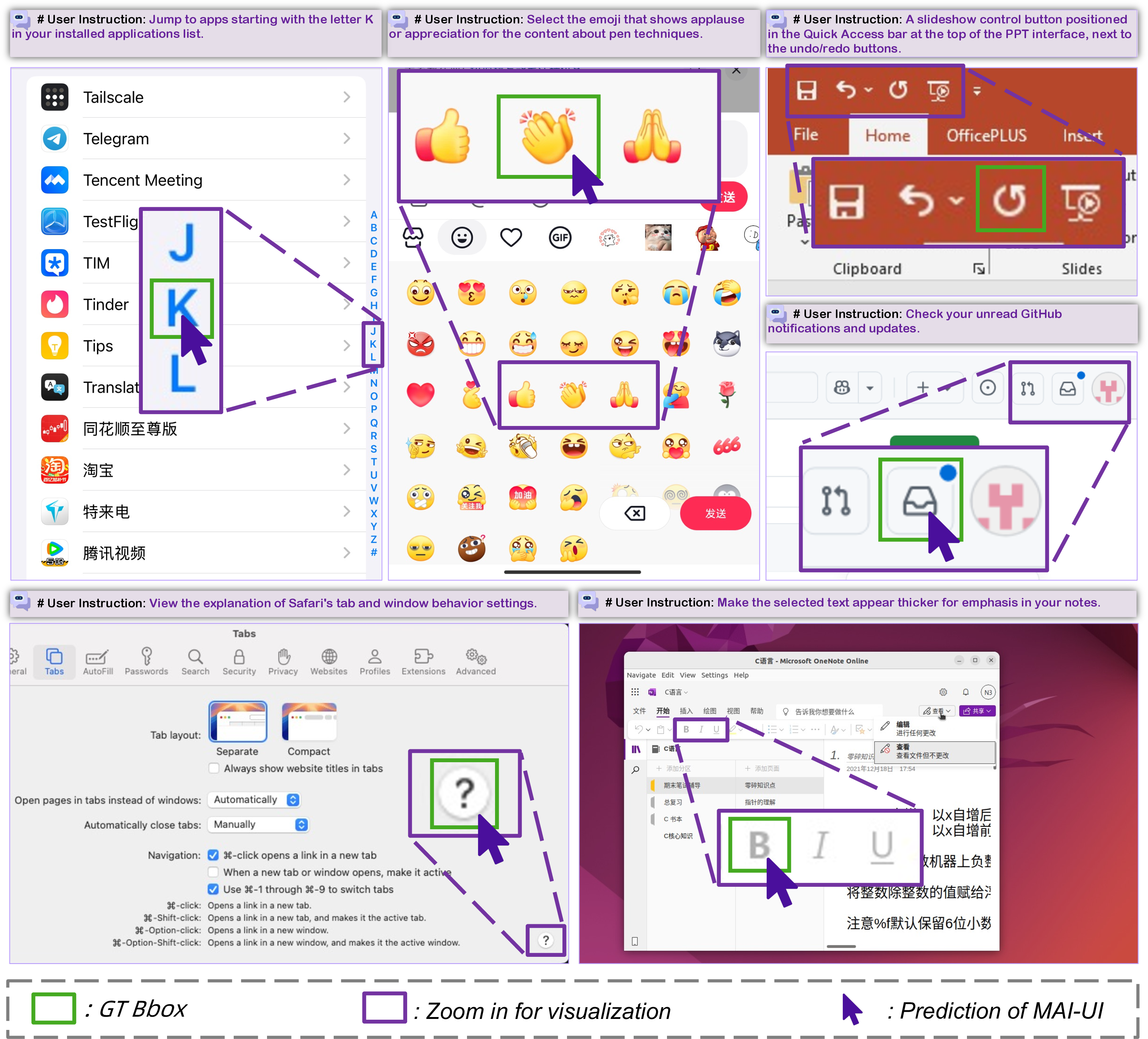
- GUI grounding: The task of locating the UI element on a screen that corresponds to a natural language instruction. "GUI grounding aims to localize the UI element corresponding to a natural language instruction on a graphical interface~\citep{wang2024ponderpressadvancing}."
- Hybrid multi-dimensional parallelism (TP+PP+CP): A combination of tensor, pipeline, and context parallelism to train ultra-long sequences across multiple GPUs. "To support end-to-end training of trajectories with millions of tokens, we leverage Megatron's hybrid multi-dimensional parallelism (TP+PP+CP) to shard each long rollout trajectory across GPUs along the tensor, pipeline, and context dimensions, enabling scalable training while keeping per-GPU memory bounded."
- Hybrid verification: A scalable evaluation approach that combines rule-based verifiers with MLLM-based judging to assess task completion. "To enable scalable evaluation, we develop a hybrid verification approach tailored to task characteristics."
- Importance sampling ratio: The ratio of current to old policy probabilities used in clipped policy optimization. "where $\quad r_{i,t}(\theta) = \frac{\pi_{\theta}(o_{i,t} \mid q, o_{i,<t})}{\pi_{\theta_{\text{old}(o_{i,t} \mid q, o_{i,<t})} \quad$ is the importance sampling ratio, and is the normalized advantage."
- KL divergence: A measure of difference between probability distributions; here omitted in the token-level loss to encourage exploration. "Following DAPO \citep{yu2025dapo}, we employ the token-level loss with no KL divergence and an asymmetric clipping strategy with a larger upper bound to encourage exploration."
- Long-horizon RL: Reinforcement learning for tasks requiring many steps and producing ultra-long trajectories. "Training RL agents for long-horizon tasks faces two interconnected challenges: traditional synchronous rollout pipelines become inefficient bottlenecks due to extensive multi-turn environment interactions, and the resulting ultra-long trajectory (up to millions of tokens per trajectory) exceed single-GPU memory capacity, necessitating advanced parallelism strategies to enable end-to-end policy training."
- MCP (Model Context Protocol): A protocol that integrates external tools via structured API calls to augment agent capabilities beyond UI manipulation. "Integrating external tools via the Model Context Protocol (MCP) provides structured shortcuts that compress long, fragile UI operation sequences into a few API calls and unlock tasks previously infeasible on mobile."
- MLLM (Multimodal LLM): A LLM that processes both text and images/screenshots for tasks like exploration and data generation. "We prompt a multimodal LLM (MLLM) to generate a variety of novel tasks."
- MLLM-as-a-Judge: Using an MLLM to automatically evaluate trajectories and correctness at step and trajectory levels. "Trajectories produced by GUI agents rollouts are examined by an MLLM-as-a-judge module~\citep{gu2025surveyllmasajudge}."
- OmniParser V2: A tool for precisely localizing UI elements from screenshots. "Finally, we use the a11y tree or OmniParser V2~\citep{omniparser} to localize UI elements precisely."
- On-policy training: An RL training paradigm where data is collected using the current policy being optimized. "To address these challenges, we employ a strict on-policy, asynchronous RL training framework built on top of verl~\citep{sheng2024hybridflow}, illustrated in Figure~\ref{fig: rl_agentloop}, with two key optimizations:"
- OSWorld-G: A GUI grounding benchmark used to evaluate screen element localization accuracy. "Notably, MAI-UI achieves 67.9\% on ScreenSpot-Pro (73.5\% with zoom-in), 91.3\% on MMBench GUI L2, 70.9\% on OSWorld-G (75.0\% on OSWorld-G-Refine), 47.1\% on UI-Vision (49.2\% with zoom-in), and 96.5\% on ScreenSpot-V2, substantially surpassing the strongest counterparts."
- Pass@K success rate: A metric indicating the probability of success within K attempts used for task stratification. "Tasks are dynamically stratified into four difficulty levels based on the current policy's pass@K success rate (SR): frontier tasks (0--25\% SR) push model capability boundaries, exploration tasks (25--50\% SR) drive skill development, near-mastery tasks (50--75\% SR) approach proficiency, and exploitation tasks (75--100\% SR) reinforce learned behaviors."
- Point-in-Box reward: A training reward where predictions are correct if the point falls inside the ground-truth bounding box. "We utilize a direct point-in-box reward to measure correctness during training."
- Prefill caching: Reusing precomputed model states to accelerate multi-turn generation during asynchronous rollouts. "On the server side, we employ load balancing and prefill caching to accelerate generation efficiency in multi-turn settings."
- POMDP (Partially Observable Markov Decision Process): A formal model for decision-making under uncertainty with partial observations. "Mobile navigation task can be formulated as a {Partially Observable Markov Decision Process (POMDP)} ~\citep{uitars}, where: denotes the state space capturing the underlying environment; represents the observation space..."
- Qwen3-VL: A vision-language backbone model used to power MAI-UI’s perception and navigation. "We employ Qwen3-VL \citep{Qwen3-VL} as the backbone model."
- Replay buffer: A memory storing recent successful trajectories used to supplement training when current rollouts fail. "We maintain a replay buffer of successful trajectories collected during training."
- REST API server: A service interface to orchestrate environment operations (reset/step/observe/evaluate) across containers. "Inspired by an experimental feature in AndroidWorld \citep{android_world}, we built a containerized solution that encapsulates the entire GUI environment within a Docker image, comprising a rooted Android Virtual Device (AVD), self-hosted backend services, and a dedicated REST API server for orchestration."
- RL-native design: Environment features tailored for RL, including reproducible resets and exposed RL primitives for parallel deployment. "We employ an AVD snapshot mechanism for reproducible task initialization and expose standard RL primitives (, , , , and ) through the containerized API server, enabling parallel deployment of emulator instances."
- Rule-based verifiers: Deterministic checks with privileged access to verify task success in environments. "Deterministic tasks with clear success criteria use rule-based verifiers with root-level AVD access for precise state verification."
- ScreenSpot-Pro: A GUI grounding benchmark used to measure state-of-the-art performance. "On grounding benchmarks, it reaches 73.5\% on ScreenSpot-Pro, 91.3\% on MMBench GUI L2, 70.9\% on OSWorld-G, and 49.2\% on UI-Vision, surpassing Gemini-3-Pro and Seed1.8 on ScreenSpot-Pro."
- Self-evolving data pipeline: A training pipeline that iteratively updates both the model and dataset via rejection sampling, human annotation, and agent rollouts. "a self-evolving data pipeline that expands the navigation data to include user interaction and MCP tool calls"
- Trajectory synthesis: The process of generating action sequences and screenshots via human annotation and model rollouts to train navigation. "In the Trajectory Synthesis stage, we first expand the seed tasks, then combine model-based synthesis and human annotation to generate diverse trajectories."
- Unified Trajectory Memory: A device-side memory that records and projects unified history so either local or cloud agents can resume seamlessly. "a local unified trajectory memory that maintains consistent information exchange between local and cloud agents."
- Zoom-In Strategy: A two-pass inference method that refines predictions by cropping and re-evaluating a region around a coarse coordinate. "During inference, we introduce an optional zoom-in strategy for complex and high-resolution GUI scenarios."
Collections
Sign up for free to add this paper to one or more collections.