- The paper introduces a unified GUI agent framework that enables multi-turn decision-making across desktop, mobile, browser, and edge platforms.
- The paper proposes a hybrid data flywheel and MRPO-based reinforcement learning algorithm to enhance training efficiency and cross-platform generalization.
- The paper demonstrates state-of-the-art performance on diverse GUI benchmarks, validating improvements in tool invocation, memory management, and multi-agent collaboration.
Motivation and Model Overview
"Mobile-Agent-v3.5: Multi-platform Fundamental GUI Agents" (2602.16855) presents GUI-Owl-1.5, a native multimodal agent model designed for autonomous operation across desktop, mobile, browser, and edge platforms. The system addresses the performance gap and practical usability bottlenecks in GUI agents by introducing extensive architectural, data, and training innovations. GUI-Owl-1.5 is instantiated in instruct/thinking variants ranging from 2B up to 235B parameters and supports cloud-edge collaboration and real-time interaction scenarios. Model variants are tailored to edge deployment (fast, lightweight instruct models) or cloud-based orchestration (reasoning-enriched thinking models), supporting distributed multi-agent coordination.
Figure 1: Multi-platform architecture and interface abstraction of Mobile-Agent-v3.5, highlighting unified environment and agent capability.
The agent is formulated as a multi-turn decision-making policy. The input at each step encompasses a screenshot and a natural language command, while the output includes an explicit reasoning chain, a planned action summary, and a structured function call for execution. The closed-loop design enables interaction with dynamical environments, expanding the action space to support external tool invocation and multi-device orchestration.
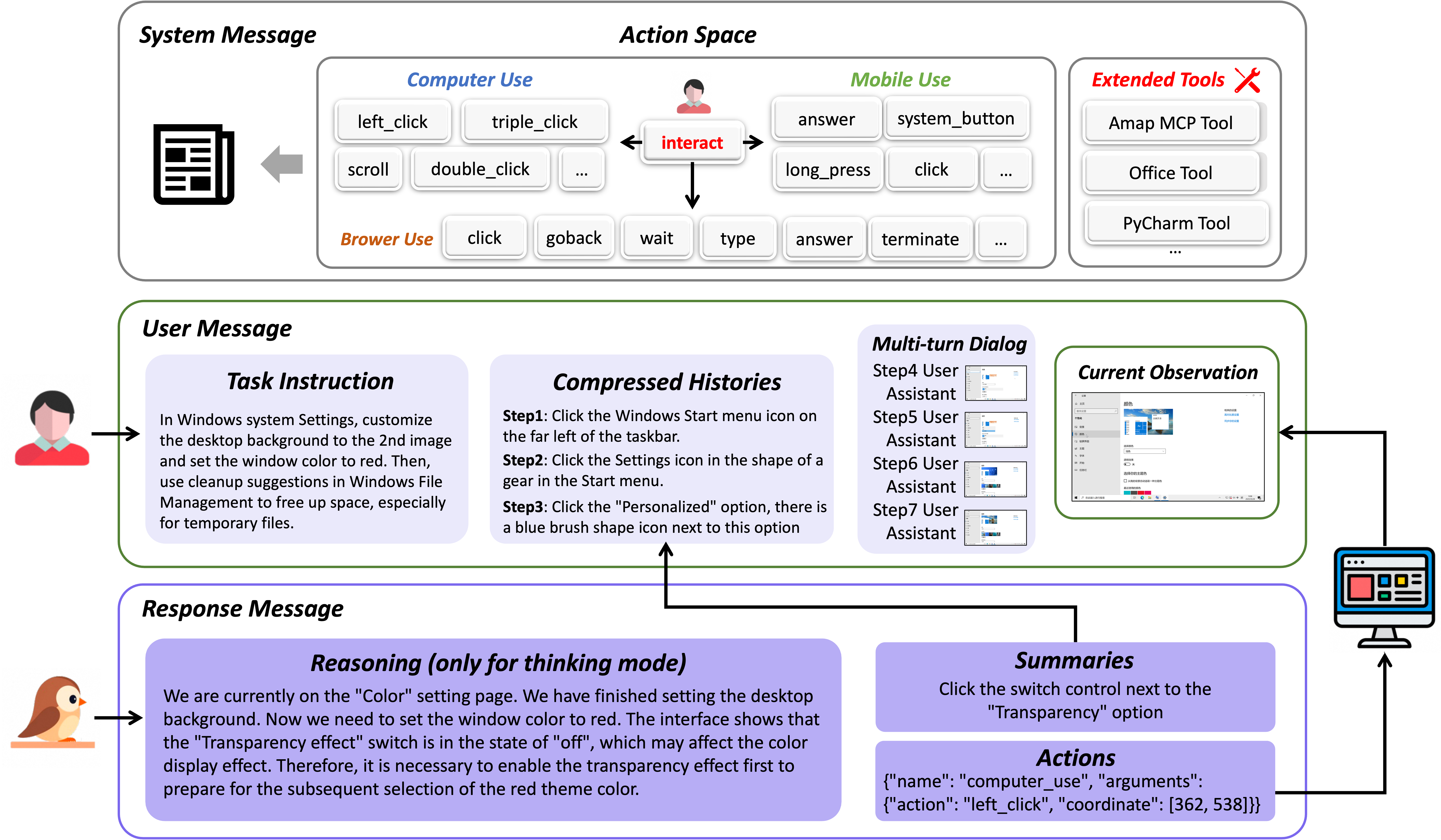
Figure 2: The interaction flow of GUI-Owl-1.5 depicting closed-loop reasoning, multimodal context, and action outputs.
Hybrid Data Flywheel: Data Construction and Trajectory Generation
A key challenge in GUI agent training is efficient, high-quality data acquisition across heterogeneous environments. The paper establishes a Hybrid Data Flywheel for both grounding and trajectory supervision:
- Grounding data is synthesized via annotated UI element generation, multi-window spatial configurations, tutorial-based QA mining, trajectory extraction, and infeasible query construction, addressing diversity insufficiency in offline datasets.
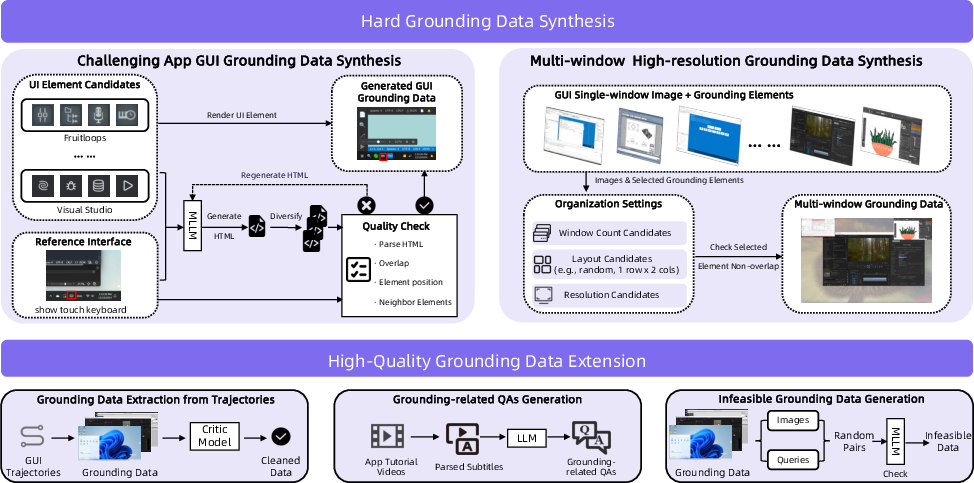
Figure 3: The grounding pipeline integrates synthetic scenarios, knowledge extraction, and trajectory mining for high-quality GUI element alignment.
- Trajectory corpora are generated using a DAG-based synthesis protocol supporting both real device and scalable virtual environments. Human annotation supplements unsolved or hard cases; automated rollouts benefit from precise sub-task validation and coverage expansion.
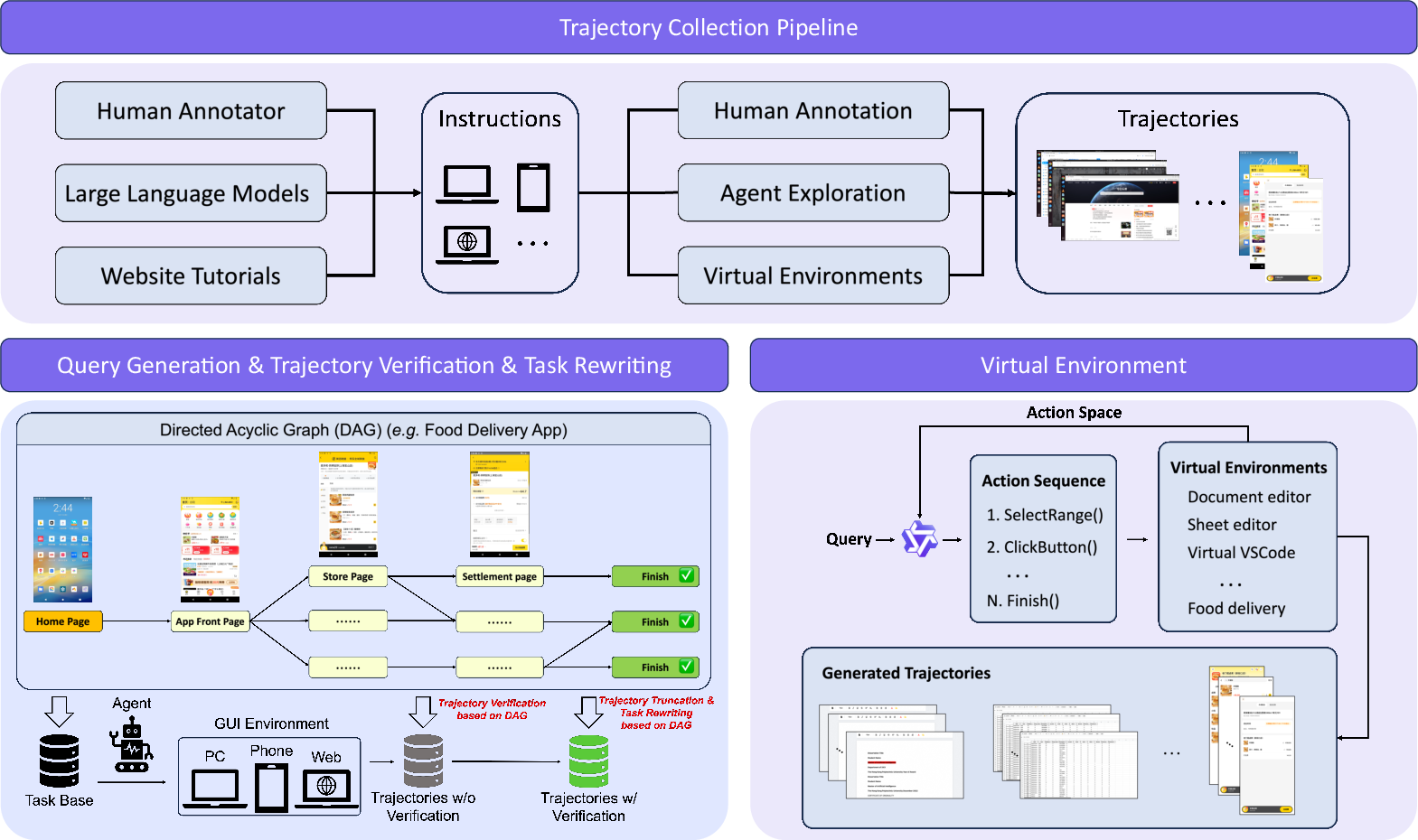
Figure 4: Unified trajectory data pipeline combining DAG synthesis, automated rollout, annotation, and virtual env feedback.
Virtual environments enable trajectory generation for scenarios disrupted by anti-bot mechanisms or lacking accurate feedback, allowing atomic operation scripting and precise progress supervision. Ablations demonstrate that removing virtual environment data severely degrades performance on atomic and complex operations.
Unified Agent Capability Enhancement
GUI-Owl-1.5 adopts a unified enhancement pipeline:
- GUI knowledge injection leverages tutorial QA, web navigation data, and world modeling—training the model to anticipate interface state transitions post-action.
- Chain-of-thought augmentation synthesizes step-wise reasoning for each trajectory, including memory management, progress reflection, tool invocation rationale, and screen observation. This instills long-horizon task planning and in-context retention.
- Multi-agent collaboration data is collected with structured role decomposition (Manager, Worker, Reflector, Notetaker). This enables specialization within coordinated multi-agent setups and closed-loop feedback loops.
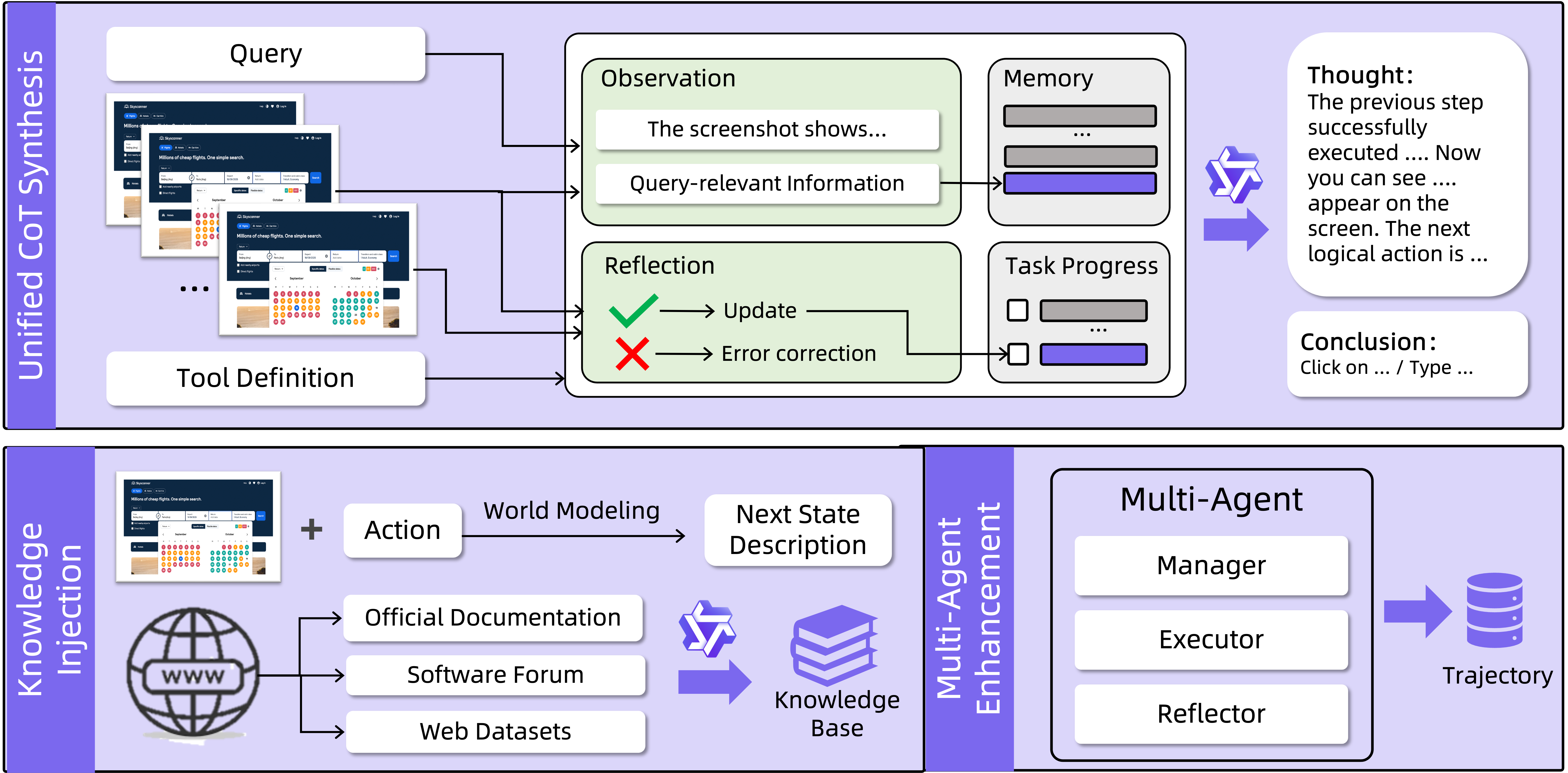
Figure 5: Agent capability enhancement pipeline: world modeling, CoT augmentation, memory management, and multi-agent collaboration.
Ablations confirm both virtual environment trajectories and CoT augmentation are critical for robust agent capabilities.
To tackle instability and inefficiency in RL optimization for GUI agents, especially across device families, the paper proposes Multi-platform Reinforcement Policy Optimization (MRPO):
- Device-conditioned unified policy learning, with alternating single-device-family optimization to mitigate cross-platform gradient interference and preserve generalization.
- An online rollout buffer oversamples and subsamples trajectory groups to enhance diversity under outcome collapse, maintaining strict on-policy guarantees.
- Token-ID transport is used to align log-probability computation between environment-side inference and training, avoiding artifacts due to tokenizer discrepancies.
- RL training strategies (unstable-set filtering and interleaved platform optimization) achieve faster convergence and greater stability compared to naive approaches.
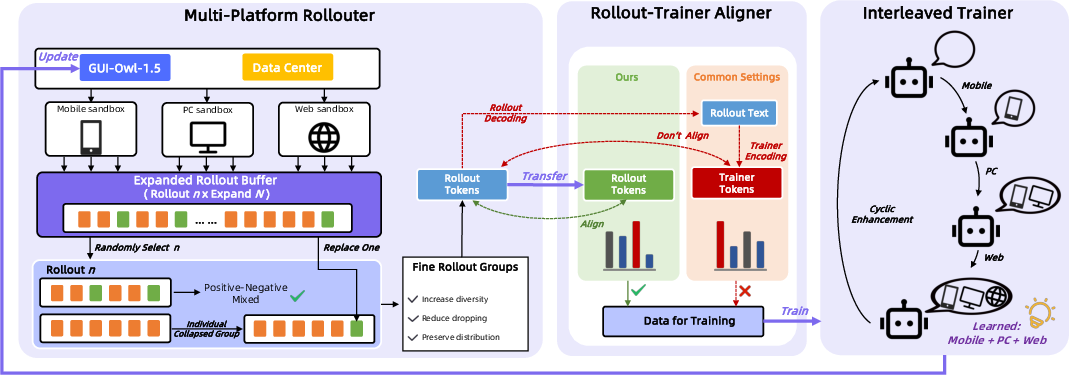
Figure 6: MRPO reinforcement learning pipeline with device-conditioned policy, rollout buffer, and token-ID alignment.
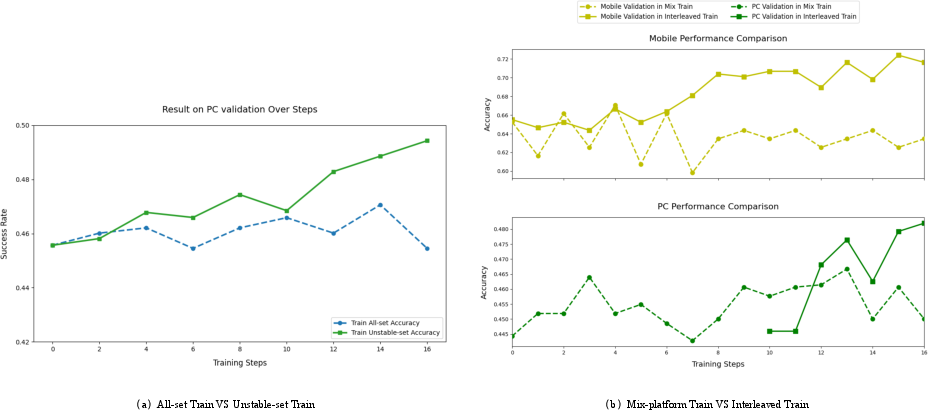
Figure 7: Ablation study showing benefits of unstable-task prioritization and interleaved multi-platform RL training.
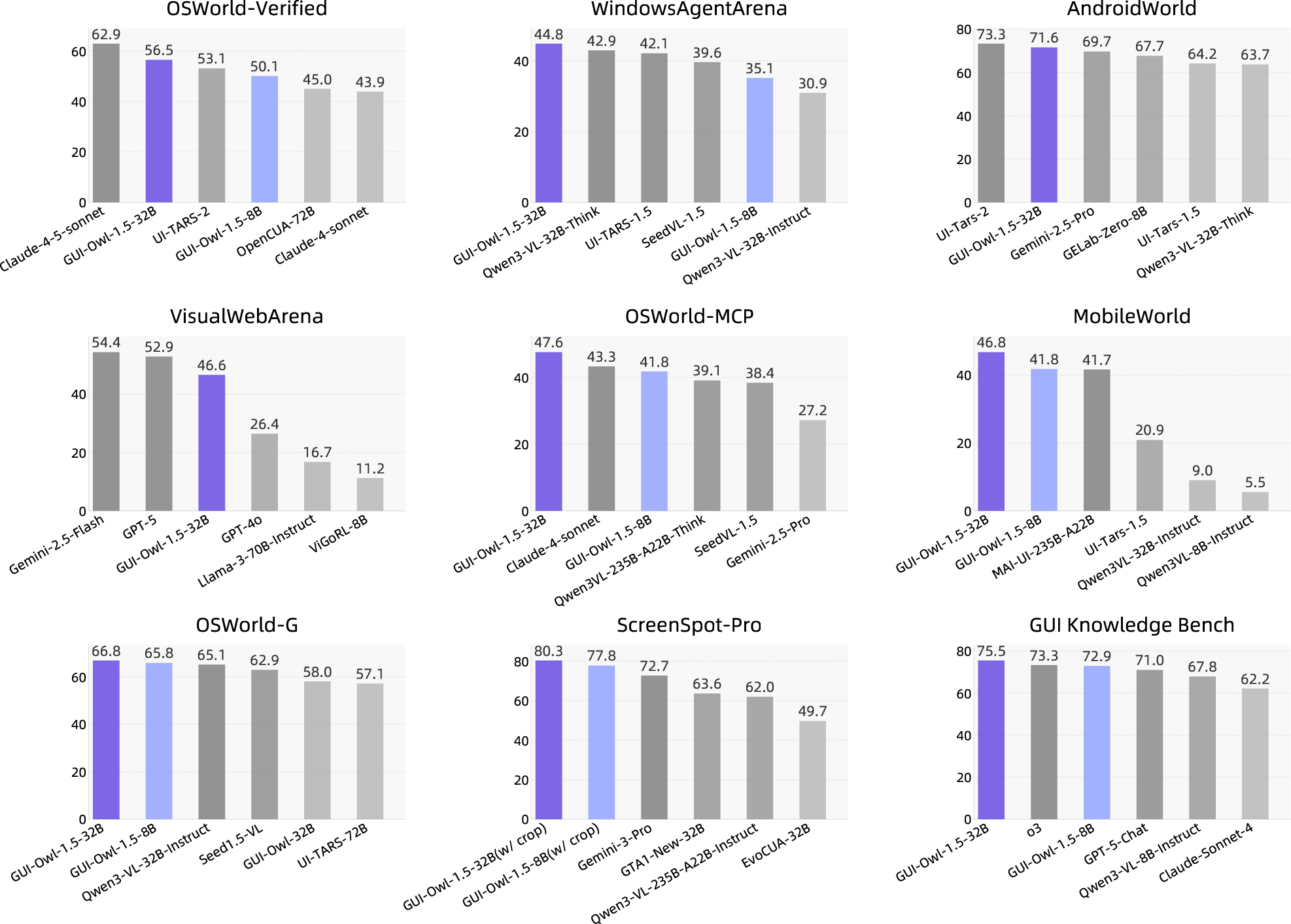
Empirical Results and Task Benchmarking
GUI-Owl-1.5 exhibits strong performance across more than 20 GUI benchmarks, including OSWorld, AndroidWorld, WebArena, ScreenSpot-Pro, OSWorld-MCP, MobileWorld, MemGUI-Bench, and GUI Knowledge Bench. On GUI automation, agentic tool use, grounding, memory, and knowledge tasks, the model achieves state-of-the-art or competitive accuracy for both single-device and multi-platform scenarios:
The thinking variants outperform instruct counterparts, notably on long-horizon tasks such as WebVoyager and Online-Mind2Web. The multi-agent and memory abilities, validated on MemGUI-Bench and GUI-Knowledge, confirm the efficacy of the enhancement pipeline.
GUI-Owl-1.5 demonstrates autonomous long-horizon task execution and robust memory management in both mobile and desktop environments:
- Android: Search and aggregate user information from multiple apps, synthesizing summaries using memory retention and cross-application reasoning.

Figure 9: Android operation: agent searches and summarizes cross-platform user information, utilizing memory and reasoning.
- Windows: Web search and notetaking, integrating task progress tracking and memorization for spreadsheet population.

Figure 10: Windows operation: agent performs multi-step web search and populates spreadsheet with retained information.
- Desktop: Coordinated tool invocation and API calls for script editing, execution, and output verification.

Figure 11: Desktop operation: agent combines tool calls and GUI actions for autonomous code editing and execution.
Practical and Theoretical Implications
GUI-Owl-1.5 refines the paradigm for generalist GUI agents, demonstrating robust cross-device orchestration, scalable RL training, and structured agent capability enhancement. The explicit separation of roles and memory, pipeline-based data generation, and rigorous RL strategies provide a foundation for capacity scaling and real-world integration in device automation, tool use, and agentic workflows.
Practically, GUI-Owl-1.5 is suited for real-world deployment ranging from lightweight edge devices to distributed cloud-agent setups for automation and system administration use cases. The open-sourced models and cloud sandbox enable reproducibility and extension. Theoretically, the hybrid training paradigm and interleaved RL scheduling may inform future developments in agent architectures for embodied, multi-platform, and tool-augmented interaction.
Conclusion
Mobile-Agent-v3.5 introduces GUI-Owl-1.5, a native, multi-platform GUI agent model featuring explicit architectural, data, and RL innovations. The model achieves state-of-the-art results across fundamental GUI automation, grounding, tool calling, memory, and knowledge benchmarks, validating its generalized and scalable agentic capabilities. The structured approach to data synthesis, agent enhancement, and RL optimization sets a new standard for foundational GUI agents, underpinning future theoretical and practical advances in autonomous agent design and deployment.