- The paper presents AmbiSQL, an interactive system that detects and resolves ambiguities in Text-to-SQL queries using a detailed taxonomy.
- It employs a two-stage framework combining pre-trained LLMs and user-guided clarifications to iteratively refine ambiguous queries.
- Evaluation on BIRD and TAG benchmarks demonstrates a significant boost in SQL generation accuracy, with exact match improvements from 42.5% to 92.5%.
AmbiSQL: Interactive Ambiguity Detection and Resolution for Text-to-SQL
Introduction
The paper introduces AmbiSQL, an interactive system aimed at addressing ambiguities in Text-to-SQL systems, particularly when utilizing LLMs. While these models show promising results in translating natural language questions to SQL queries, they are often plagued by errors due to inherent ambiguities. The system proposed leverages a fine-grained taxonomy to detect and resolve ambiguities that impede accurate SQL generation by guiding users through multiple-choice questions to clarify their intent.
Ambiguity Taxonomy
AmbiSQL operates under a two-dimensional taxonomy to categorize ambiguities affecting SQL generation. The first dimension, DB-related ambiguities, encompasses unclear or underspecified references to database schemas or content. This includes ambiguities like unclear schema or value references and missing SQL-related keywords. The second dimension, LLM-related ambiguities, deals with those arising from the misuse of LLM reasoning, which includes unclear knowledge sources or insufficient reasoning context.
System Architecture
AmbiSQL is designed with a two-stage pipeline: Ambiguity Identification and Iterative Refinement. The first stage utilizes pre-trained LLMs to identify and categorize ambiguous phrases within the user queries based on the outlined taxonomy. In Stage 2, the system refines queries through user inputs derived from targeted multiple-choice questions, ensuring a clarified intention for accurate SQL generation.
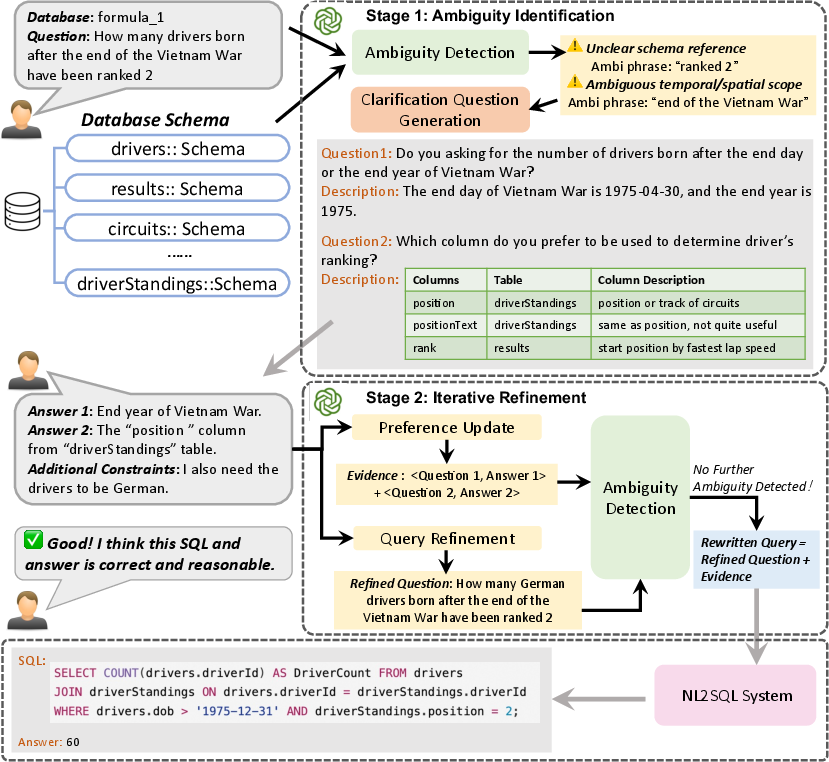
Figure 1: Overview of the AmbiSQL System.
Upon detecting ambiguities, AmbiSQL generates clarification questions tailored to each ambiguity type. These questions are supplemented with relevant database information or schema snippets to aid user responses. The system employs a user preference tree to manage clarifications and utilizes in-context learning to update preferences when user inputs conflict with previously stated intents.
User Interface and Evaluation
AmbiSQL's user interface, illustrated in Figure 2, facilitates user interactions with the system through panels designed for input, ambiguity resolution, and SQL generation. This interface supports both user-defined queries and pre-selected examples from a curated dataset, allowing comprehensive exploration of the system's capabilities.
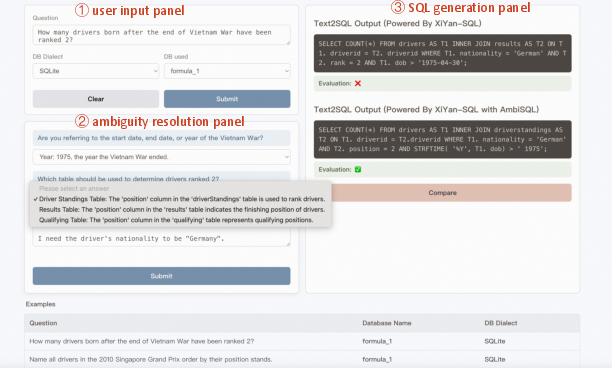
Figure 2: User Interface of AmbiSQL.
In a demonstration across five databases from the BIRD benchmark, AmbiSQL significantly improves SQL generation accuracy. When integrated with XiYan-SQL, a state-of-the-art Text-to-SQL system, AmbiSQL enhances exact match accuracy from 42.5% to 92.5%, underscoring the utility of interactive ambiguity resolution.
Experimental Results
Extensive testing against ambiguous queries from BIRD and TAG benchmarks indicates that AmbiSQL achieves strong precision (87.2%), recall (89.1%), and F1-score (88.2%) in ambiguity detection. It handles DB-related ambiguities with notable recall and LLM-related ambiguities with high precision, demonstrating comprehensive coverage of the ambiguity taxonomy.
Conclusion
AmbiSQL represents a notable advance in the interactive resolution of ambiguities in Text-to-SQL systems. By refining queries through user-driven clarifications, it aligns LLM-generated interpretations more closely with user intent. The enhanced accuracy in SQL query generation highlights its potential to improve benchmarks and real-world applications where query ambiguity is prevalent. Future work can explore extensions of AmbiSQL to other domains and further integration with varied Text-to-SQL frameworks for broader applicability.