- The paper finds that continuous features outperform discrete tokens in SpeechLLMs, particularly for ASR, ST, and ER tasks.
- It employs a consistent experimental framework across various LLM scales to evaluate strengths in phoneme recognition and overall task performance.
- The study reveals that discrete tokens reduce training time and bandwidth, but may suffer from generalization issues due to under-trained tokens.
Comparative Analysis of Speech Discrete Tokens and Continuous Features for Spoken Language Understanding in SpeechLLMs
The paper "Speech Discrete Tokens or Continuous Features? A Comparative Analysis for Spoken Language Understanding in SpeechLLMs" (2508.17863) offers a detailed evaluation of two prominent paradigms for integrating speech processing within Speech LLMs (SpeechLLMs): discrete tokens and continuous features. This study aims to bridge the performance assessment gap between these paradigms by employing consistent experimental conditions and a suite of spoken language understanding-related tasks.
Methodology and Approaches
Speech Representation Techniques
SpeechLLMs have gained prominence in the speech domain, leveraging large-scale LLMs to enhance multimodal understanding. Two primary representations for input into these models are discrete tokens and continuous features. Discrete tokens transform speech into sequences of symbols using techniques like K-Means clustering and Byte-Pair Encoding (BPE). This format is compatible with autoregressive models designed for text processing, enabling direct integration into the vocabulary of LLMs. Continuous features, conversely, retain the fine-grained acoustic details by embedding speech signals through layers of Self-Supervised Learning (SSL) models like HuBERT and WavLM (Figure 1).
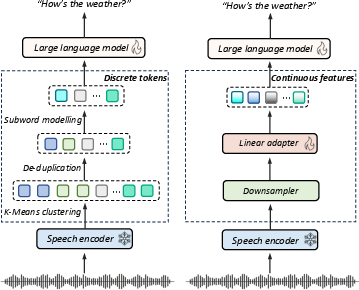
Figure 1: Architectures of two approaches for integrating speech into LLMs. (Left) discrete token-based encoding. (Right) continuous feature processing.
Pipeline Design and Instruction-Tuning
The study utilizes two established pipelines to evaluate performance across six tasks: ASR, PR, KS, ER, IC, and ST. Instruction-tuning with LLMs is conducted using specific prompt designs, comparing outcomes across different LLM scales, such as Qwen1.5-0.5B and Llama3.1-8B. This setup aims to reveal the interaction dynamics between speech-based representations and LLMs of varying sizes, thereby highlighting the distinct characteristics of discrete tokens and continuous features.
Experiments and Results
Benchmarking Comparative Outcomes
The paper reports that continuous features generally outperform discrete tokens across multiple tasks and model scales. WavLM-Large's continuous features achieve superior performance in ASR, ST, and ER tasks, especially when using the larger Llama3.1-8B model. Discrete tokens, however, show strength in phoneme recognition, suggesting their efficiency in capturing subword-level structures, an observation attributed to their alignment with phonetic-level encoding.
Efficiency Analysis
Continuous features demand more computational resources and data size, yet discrete tokens offer notable reductions in training time and bandwidth utilization. As illustrated in Figure 2, discrete tokens excel in training efficiency by drastically minimizing input sequence lengths and computational loads. Utility efficiency analysis reveals under-training challenges for discrete tokens—certain tokens are rarely encountered during training, leading to wasted capacity and potential degradation in generalization performance.
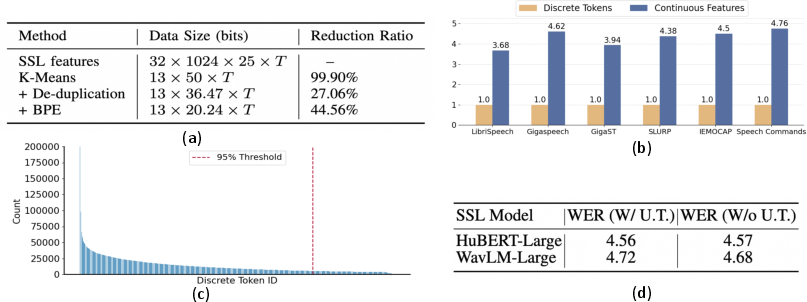
Figure 2: Efficiency analysis. (a) Data size comparison for utterance representation; (b) Training time comparison; (c) Frequency distribution of discrete tokens; (d) WER comparison with under-trained tokens.
In-Depth Analysis and Implications
SSL and LLM Layers
Figure 3 shows distinct usage patterns across SSL layers, where continuous features generally perform better in shallower layers for emotion recognition, while discrete tokens peak in deeper layers for phonetic tasks. For LLM alignment, the smooth transition in similarity between speech and text inputs for continuous features suggests more stable modality mapping over the network's lifespan compared to discrete tokens.
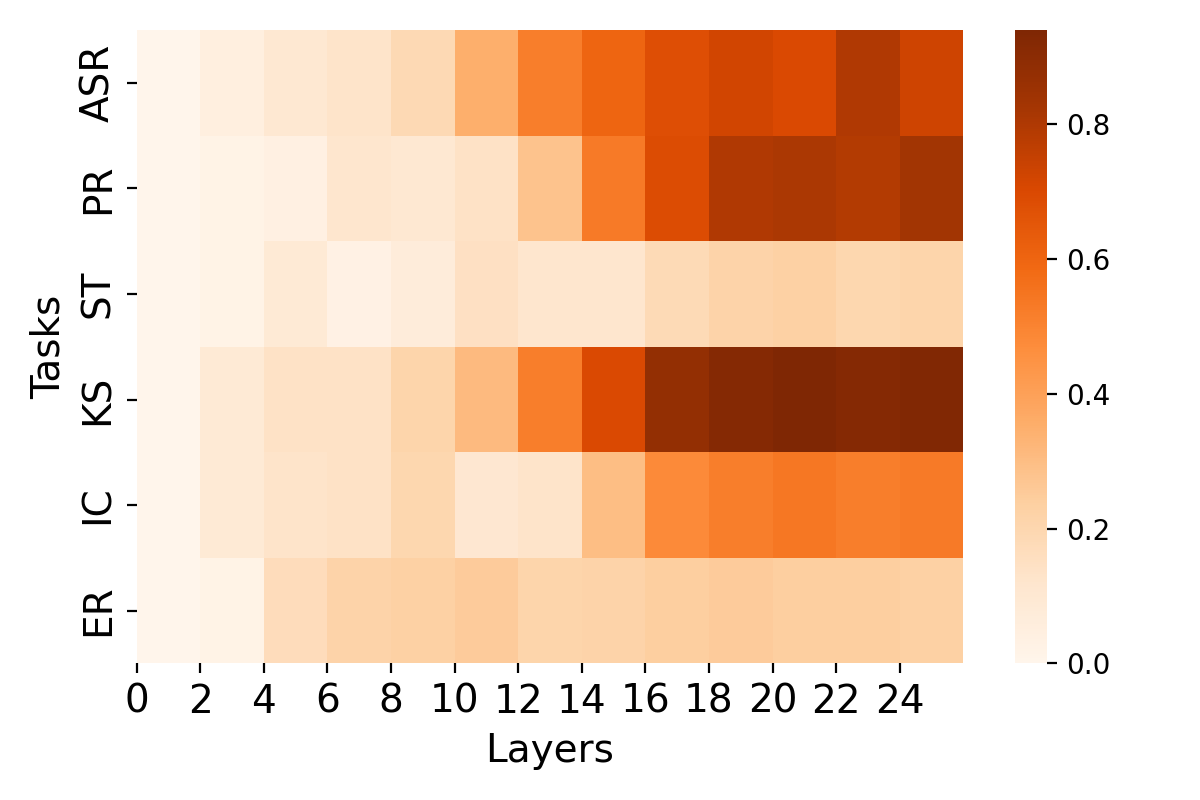
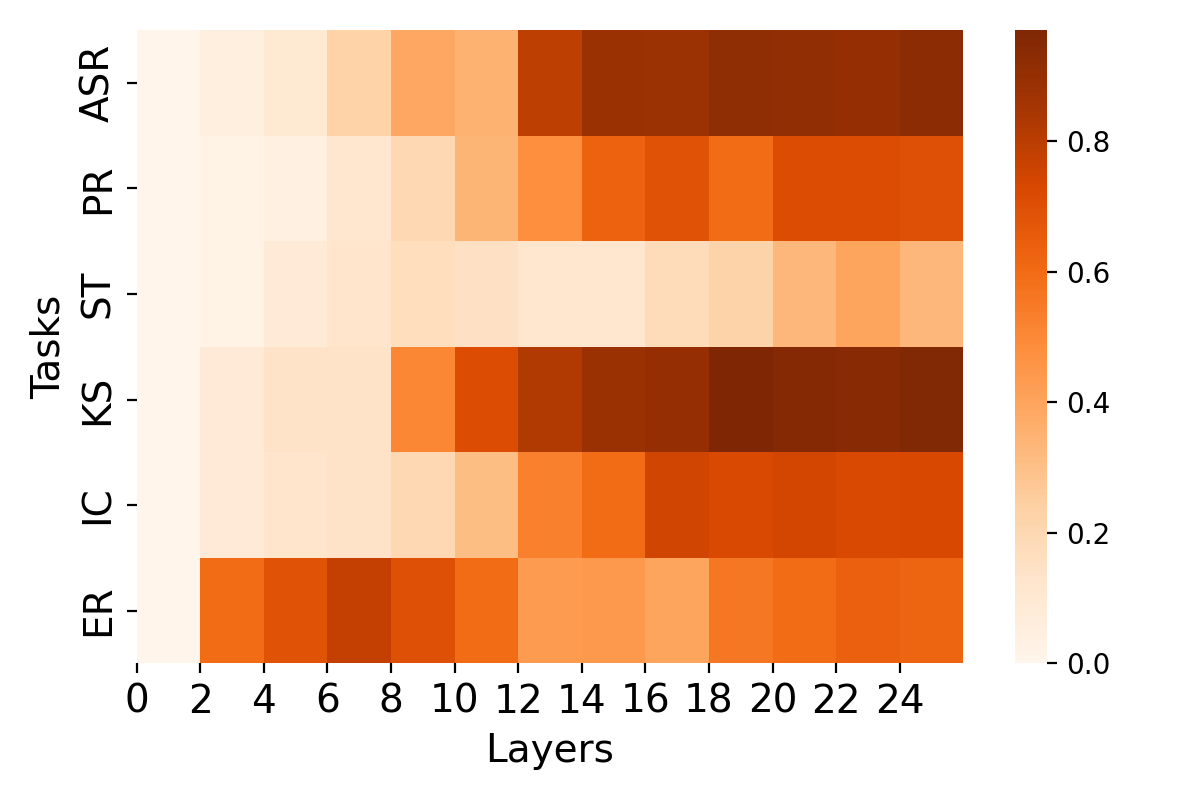
Figure 3: Layer analysis for each task on HuBERT-Large. (Left) Distribution of discrete token performance across each layer. (Right) Distribution of continuous features' performance across each layer.
Conclusion
The comparative study highlights that continuous features consistently outperform discrete tokens across varied scales in SpeechLLMs, showcasing robustness and adaptability advantages, except in phonetic-level tasks such as phoneme recognition. Moreover, discrete tokens offer data and training efficiency, potentially informing future optimization strategies in large-scale speech processing applications.
Future Directions
Future research could explore broader LLM backbones to further delineate the merits and limitations of these representation paradigms. Incorporating more exhaustive fine-tuning processes for individual tasks could also provide deeper insights into real-world applicability and performance optimization against state-of-the-art benchmarks.