- The paper presents HiPS, a method that combines TOC-based and LLM-refined extraction to robustly segment PDF textbooks into multi-level hierarchical sections.
- It evaluates performance using precision, recall, tree edit distance, and boundary metrics, showing improvements over baseline tools in legal and textbook domains.
- The study highlights challenges with deep hierarchies and metadata noise, offering insights for legal knowledge graph construction and future multimodal integration.
Hierarchical PDF Segmentation of Textbooks: Technical Analysis of HiPS
Motivation and Problem Setting
PDFs are ubiquitous for knowledge dissemination, but their syntactic layout obfuscates structural hierarchy, essential for computational interpretation. Textbooks, especially in the legal domain, exhibit deeply nested section trees—beyond typical hierarchies found in research papers—posing unique challenges for automated segmentation. Existing solutions often cap at three hierarchical levels and fail to generalize across heterogeneous publisher styles. HiPS addresses this gap, establishing methods for robust extraction of section titles, hierarchical allocation, and section boundaries from complex PDF textbooks leveraging both TOC-based and LLM-based paradigms.
Dataset and Annotation Methodology
The dataset construction targets English law textbooks sourced from the Open Research Library, optimizing for diversity in hierarchical complexity. 362 books were crawled, with 259 possessing outline metadata. Stratified sampling ensured coverage across hierarchy depths. Manual TOC curation resolved issues with incomplete metadata, OCR artifacts, and misaligned headings, resulting in a high-fidelity dataset comprising 9,812 annotated headings across 49 files. This meticulous annotation enables benchmarking at depth and validates the fidelity of detected segmentations.
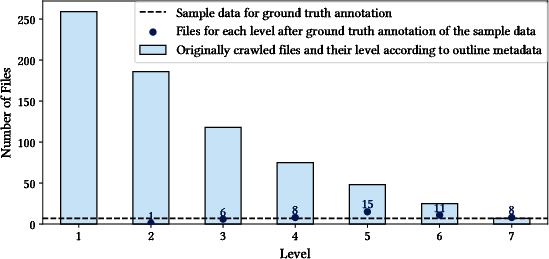
Figure 1: Sampling methodology visualizes depth-driven selection across the PDF corpus, guaranteeing diversity for hierarchical segmentation evaluation.
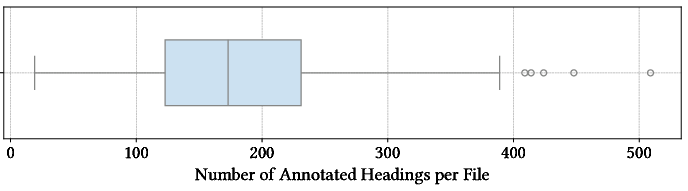
Figure 2: Annotation statistics reveal substantial variance in heading counts per file, reflecting vast structural diversity across textbooks.
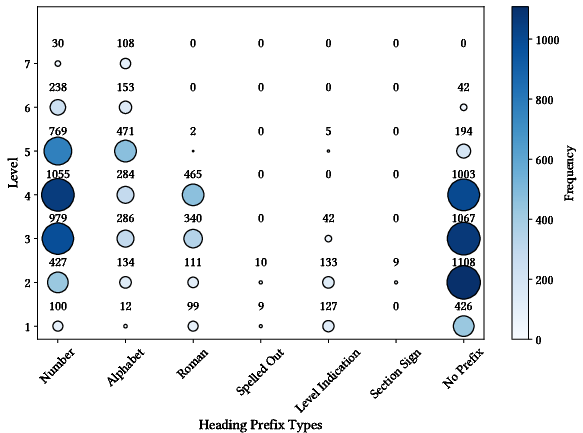
Figure 3: Prefix distribution highlights formatting heterogeneity, showing why rule-based detection suffers from low recall in law-domain PDFs.
Segmentation Approaches
TOC-Based PageParser
Directly utilizes PDF TOC metadata to extract section titles, pages, and hierarchical relationships. Multiple normalization and matching strategies (exact, substring, fuzzy) counteract minor formatting differences and OCR distortions. Robustness is contingent on metadata quality and presence.
LLM-Refined PageParser
Operates without explicit TOC input, relying on a candidate selection pipeline utilizing XML features and OCR-based context. Candidate headings, enriched with typographic and geometric cues, are handed to instruction-tuned LLMs (GPT-4, GPT-5, Llama3, Phi4) for semantic validation and hierarchy assignment. This approach demonstrates adaptability across layout formats and publisher idiosyncrasies.
Open-source parsers (PDFstructure, Marker, GROBID, Docling) are evaluated; most yield page-local or shallow hierarchical outputs and degrade under deep textbook structures due to lack of TOC reconciliation and insufficient boundary assignment strategies.
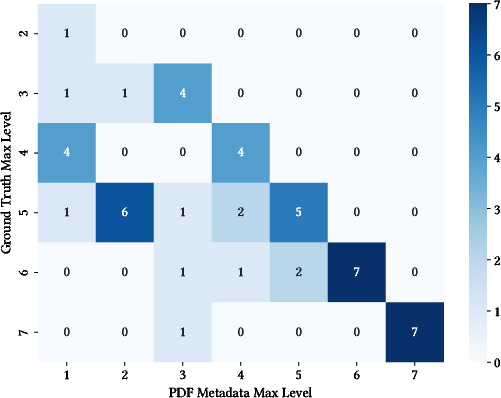
Figure 4: Comparison between maximum hierarchy depths found in metadata versus manual annotation underscores unreliability of PDF TOC metadata and necessity for supplementary methods.
Evaluation Metrics and Results
Hierarchical segmentation assessment pivots on three subtasks: title detection, hierarchy allocation, and boundary assignment.
Section Title Detection
Precision and recall (with edit-distance tolerance) measure detection efficacy. TOC-Based PageParser achieves highest PED on files with reliable metadata, whereas XML-OCR-GPT5 yields superior results on files with incomplete metadata or noisy layouts, evidencing LLMs' semantic adaptability. Notably, Phi4 outperforms Llama3, likely due to textbook-centric pretraining.
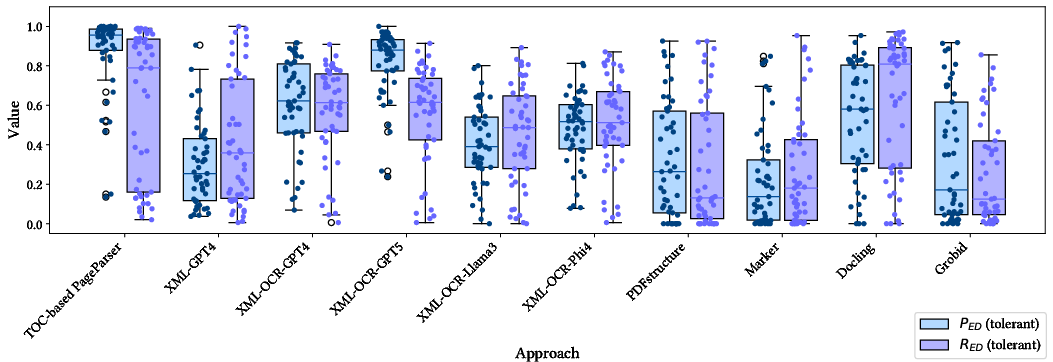
Figure 5: Tolerant edit distance precision/recall demonstrates superiority of TOC-based extraction when metadata is of sufficient quality, while semantically informed LLMs excel in noisy contexts.
Hierarchical Allocation
Tree edit distance quantifies structural fidelity. TOC-Based PageParser displays lowest distances, especially in deeply structured files with accurate metadata. LLM-refined and Marker approaches offer improved performance in challenging instances with corrupted or inconsistent metadata.
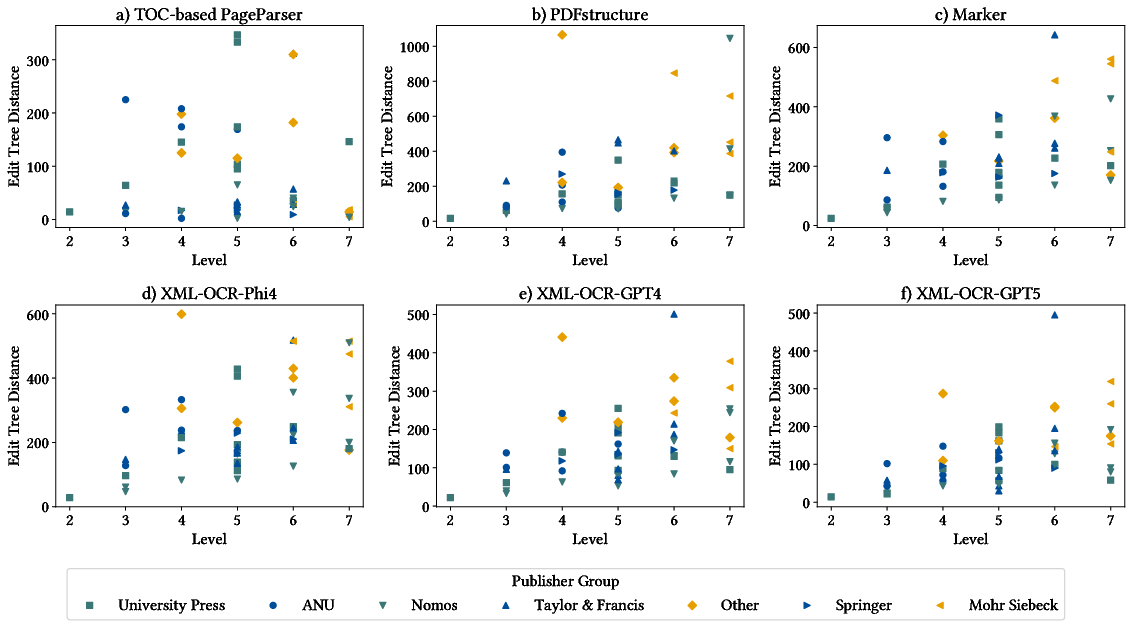
Figure 6: Edit tree distance evaluation exposes the strengths of metadata-driven TOC approaches and LLMs in handling varied publisher and layout artifacts.
Section Boundary Assignment
Pk and WindowDiff appraise boundary precision. XML-OCR-GPT5 achieves optimal boundary assignment. The TOC-Based PageParser’s performance degrades when TOC coverage is incomplete. Baseline tools perform consistently below LLM-refined approaches.
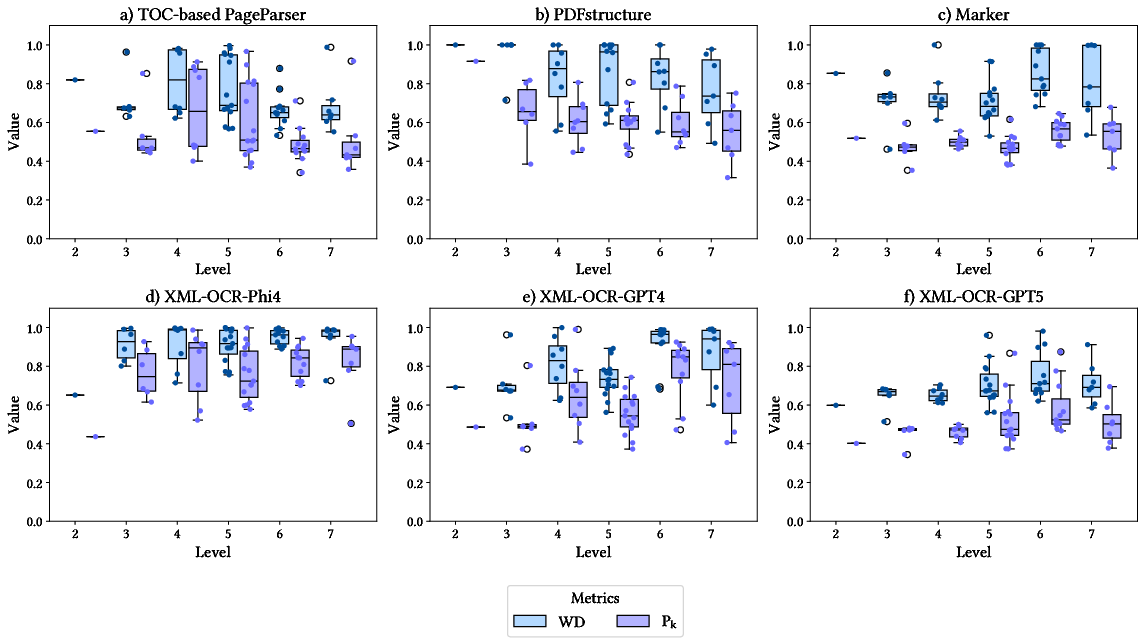
Figure 7: Boundary assignment results pinpoint best-in-class accuracy for XML-OCR-GPT5, affirming LLMs' competence when structural cues are ambiguous or missing.
Implications and Future Directions
The empirical evidence substantiates that while TOC-driven approaches are highly effective for well-tagged PDFs, their performance is inherently bounded by metadata quality. LLMs, particularly when augmented with structural preprocessing (XML, OCR), offer substantial gains in adaptability and precision, reducing false positives and enabling handling of publisher variability and deep hierarchies. However, even state-of-the-art LLMs and advanced open-source tools struggle with extreme tree depths and noisy formatting.
The practical implications extend to automated creation of legal knowledge graphs and context-aware entity extraction, contingent on reliable textbook segmentation. Theoretically, this work advances structuring strategies for unstructured digital artifacts, laying groundwork for semantic search and legal reasoning engines.
Future avenues involve dataset enrichment with TOC-less PDFs, domain-adaptive fine-tuning of LLMs, and integration with knowledge graph construction pipelines. The intersection of multimodal (visual, textual, structural) representations and instruction-following LLMs warrants further exploration to address edge cases and maximize segmentation reliability across heterogeneous document archetypes.
Conclusion
HiPS systematically benchmarks hierarchical segmentation methods, revealing the conditional strengths of TOC-based and LLM-refined approaches within the legal textbook domain. The combination of structural heuristics and LLMs represents a critical step forward. Benchmarking and dataset provision support community replication and further research. Deep hierarchies remain an open challenge; continued innovation in document parsing and semantic modeling is required to realize fully automated structured knowledge extraction from PDFs.