$Agent^2$: An Agent-Generates-Agent Framework for Reinforcement Learning Automation
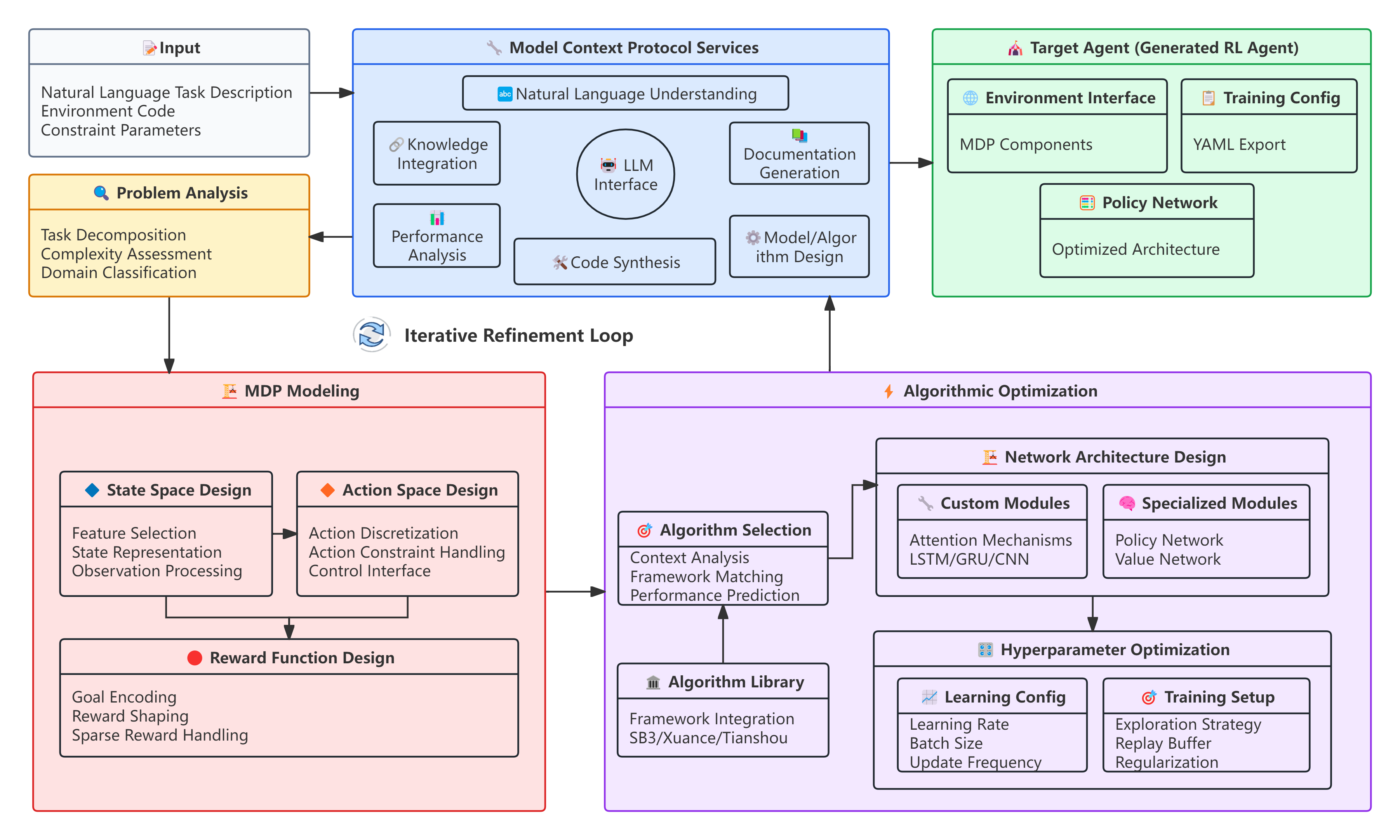
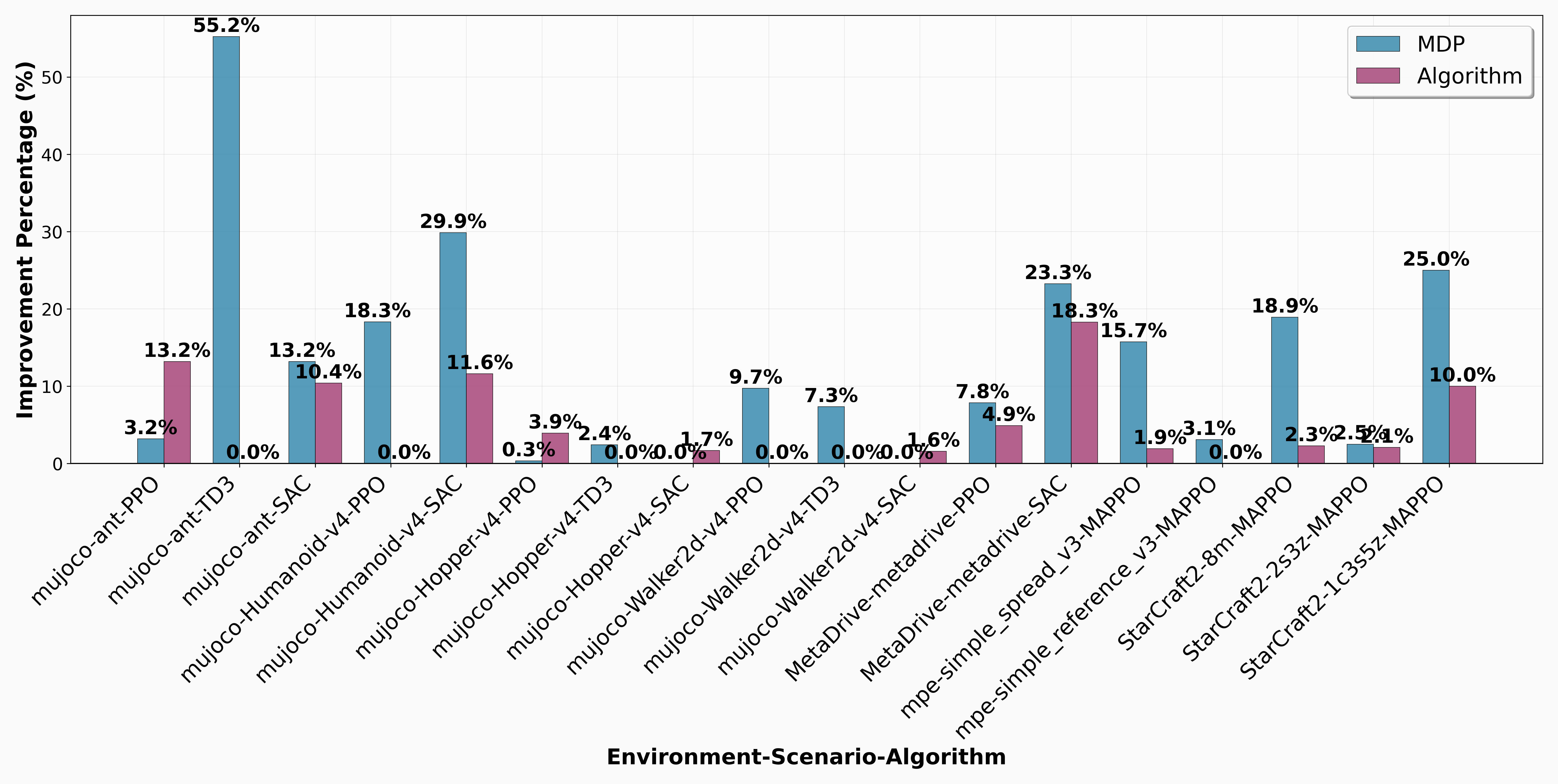
Abstract: Reinforcement learning (RL) agent development traditionally requires substantial expertise and iterative effort, often leading to high failure rates and limited accessibility. This paper introduces Agent$2$, an LLM-driven agent-generates-agent framework for fully automated RL agent design. Agent$2$ autonomously translates natural language task descriptions and environment code into executable RL solutions without human intervention. The framework adopts a dual-agent architecture: a Generator Agent that analyzes tasks and designs agents, and a Target Agent that is automatically generated and executed. To better support automation, RL development is decomposed into two stages, MDP modeling and algorithmic optimization, facilitating targeted and effective agent generation. Built on the Model Context Protocol, Agent$2$ provides a unified framework for standardized agent creation across diverse environments and algorithms, incorporating adaptive training management and intelligent feedback analysis for continuous refinement. Extensive experiments on benchmarks including MuJoCo, MetaDrive, MPE, and SMAC show that Agent$2$ outperforms manually designed baselines across all tasks, achieving up to 55\% performance improvement with consistent average gains. By enabling a closed-loop, end-to-end automation pipeline, this work advances a new paradigm in which agents can design and optimize other agents, underscoring the potential of agent-generates-agent systems for automated AI development.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Glossary
- Ablation studies: Controlled experiments that remove or isolate components of a system to quantify their impact on performance. "Finally, we perform ablation studies to quantify the respective impact of the two stages: Task-to-MDP mapping and algorithmic optimization."
- Adaptive verification and refinement: An automated process that verifies generated components and iteratively improves them using error and performance feedback. "To address this, we introduce an adaptive verification and refinement framework that integrates generated components into the RL pipeline and iteratively improves them via automated validation and feedback."
- Action masking: A technique that restricts an agent’s available actions at a given state to guide learning and enforce constraints. "recent methods use LLM-generated action masking or suboptimal policies to dynamically constrain and guide RL agents"
- Agent: The proposed LLM-driven framework that automates the design and optimization of reinforcement learning agents. "Agent outperforms manually designed baselines across all tasks, achieving up to 55\% performance improvement with consistent average gains."
- Agent-generates-agent: A paradigm where one agent designs and produces another agent to perform a target task. "an agent-generates-agent framework for fully automated RL agent design."
- AutoML: Automated machine learning techniques for algorithmic and configuration optimization, reducing manual tuning. "Research on its algorithmic optimization mainly follows the AutoML, which has seen rapid development and become relatively mature~\citep{he2021automl}."
- AutoRL: Automation of the reinforcement learning pipeline, including environment modeling and algorithm selection/tuning. "most existing AutoRL approaches automate only a single stage of the RL pipeline"
- Credit assignment problem: The challenge of determining which actions or agents should receive credit for observed outcomes in multi-agent RL. "research mainly focuses on solving the credit assignment problem for effective reward distribution~\citep{nagpal2025leveraging, lin2025speaking, he2025enhancing}."
- DQN: Deep Q-Network, a value-based RL algorithm for discrete action spaces. "value-based methods like DQN are appropriate for discrete action spaces"
- Discount factor: A scalar that weights future rewards relative to immediate rewards in RL. "and the discount factor."
- EvoPrompting: A method that uses LLMs as adaptive operators within evolutionary neural architecture search. "EvoPrompting~\citep{chen2023evoprompting} uses LMs as adaptive operators in evolutionary NAS."
- Feature selection: Choosing a subset of relevant state variables or features to improve learning efficiency. "possibly applying feature selection, dimensionality reduction, or combining observations to improve learning efficiency."
- Generator Agent: The autonomous agent in Agent that analyzes tasks and generates all components needed for the Target Agent. "The Generator Agent serves as an autonomous AI designer, capable of analyzing and producing all necessary components for an RL agent."
- Hyperparameter optimization: The process of selecting and tuning training parameters (e.g., learning rate, batch size) to improve performance. "For hyperparameter optimization, some studies use LLMs to suggest and iteratively refine hyperparameter configurations based on dataset and model descriptions"
- MAPPO: Multi-Agent Proximal Policy Optimization, an actor-critic algorithm tailored for multi-agent cooperation. "we adopt MAPPO, a classic algorithm that has demonstrated strong performance in many benchmarks such as MPE and SMAC."
- MDP: Markov Decision Process, a formal model of decision making defined by states, actions, transitions, rewards, and a discount factor. "Formally, an MDP is defined as "
- MetaDrive: A large-scale autonomous driving simulator environment for RL research. "MetaDrive~\citep{li2022metadrive}, a large-scale autonomous driving simulator where agents must safely navigate diverse and dynamic traffic scenarios"
- Model Context Protocol (MCP): A protocol ensuring standardized integration of tools and services in the agent framework. "operates in compliance with the Model Context Protocol (MCP), ensuring standardized integration of services."
- MuJoCo: A physics engine and suite of continuous control tasks widely used for RL benchmarking. "benchmarks including MuJoCo, MetaDrive, MPE, and SMAC"
- NAS: Neural architecture search, automated discovery of neural network designs. "evolutionary NAS."
- Partial observability: When agents cannot fully observe the environment state, complicating decision making. "helping to address limitations from partial observability."
- Policy gradient methods: RL algorithms that directly optimize the policy via gradient ascent, typically used for continuous control. "policy gradient methods such as PPO and SAC are better for continuous control."
- PPO: Proximal Policy Optimization, a policy gradient algorithm emphasizing stable updates. "we employ PPO, SAC, and TD3 on the MuJoCo environments"
- Quality diversity optimization: Evolutionary optimization that seeks a diverse set of high-performing solutions. "combines LLM code generation with quality diversity optimization to discover diverse and effective architectures"
- Reward shaping: Modifying or augmenting the reward function to guide learning and improve performance, especially with sparse rewards. "developing automated reward shaping methods"
- SAC: Soft Actor-Critic, an off-policy RL algorithm optimizing a stochastic policy with an entropy term. "we employ PPO, SAC, and TD3 on the MuJoCo environments"
- Sample efficiency: The effectiveness of an RL method in learning good policies with fewer environment interactions. "improving sample efficiency and policy adaptability"
- SMAC: StarCraft Multi-Agent Challenge, a benchmark of cooperative micromanagement tasks for multi-agent RL. "SMAC~\citep{samvelyan2019starcraft}, which provides cooperative StarCraft II micromanagement tasks of varying scales and difficulties"
- Target Agent: The executable RL agent generated by the framework to interact with environments for training and evaluation. "Target Agent that is automatically generated and executed."
- TD3: Twin Delayed Deep Deterministic policy gradient, an off-policy algorithm for continuous control using twin critics and delayed updates. "we employ PPO, SAC, and TD3 on the MuJoCo environments"
- TensorBoard: A visualization toolkit for tracking and analyzing training metrics. "summarizes key performance indicators from TensorBoard data into a concise report"
- Transition probability: The dynamics describing the probability of moving from one state to another given an action. "the transition probability"
- Value-based methods: RL approaches that learn value functions and derive policies from them, typically suited to discrete actions. "value-based methods like DQN are appropriate for discrete action spaces"
- Verification operator: A programmatic checker used to validate generated components before training. "checked by a verification operator "
- YAML: A human-readable data serialization format used for exporting configurations. "exported in standardized YAML format for compatibility and reproducibility."
Collections
Sign up for free to add this paper to one or more collections.